Programming Paradigm
There are some rules and conventions to be followed in any framework. Only by following and mastering these rules can we use them more easily and achieve twice the result with half the effort.When we develop Flink job, we actually use the API provided by Flink to write an executable program (which must have a main() function) according to the development method required by Flink. We access variousConnectorin the program, and after a series of operatoroperations, we finally sink the data to the target storage through the Connector .
We call this method of step-by-step programming according to certain agreed rules the "programming paradigm". In this chapter, we will talk about the "programming paradigm" of StreamPark and the development considerations.
Let's start from these aspects
- Architecture
- Programming paradigm
- RunTime Context
- Life Cycle
- Catalog Structure
- Packaged Deployment
Architecture
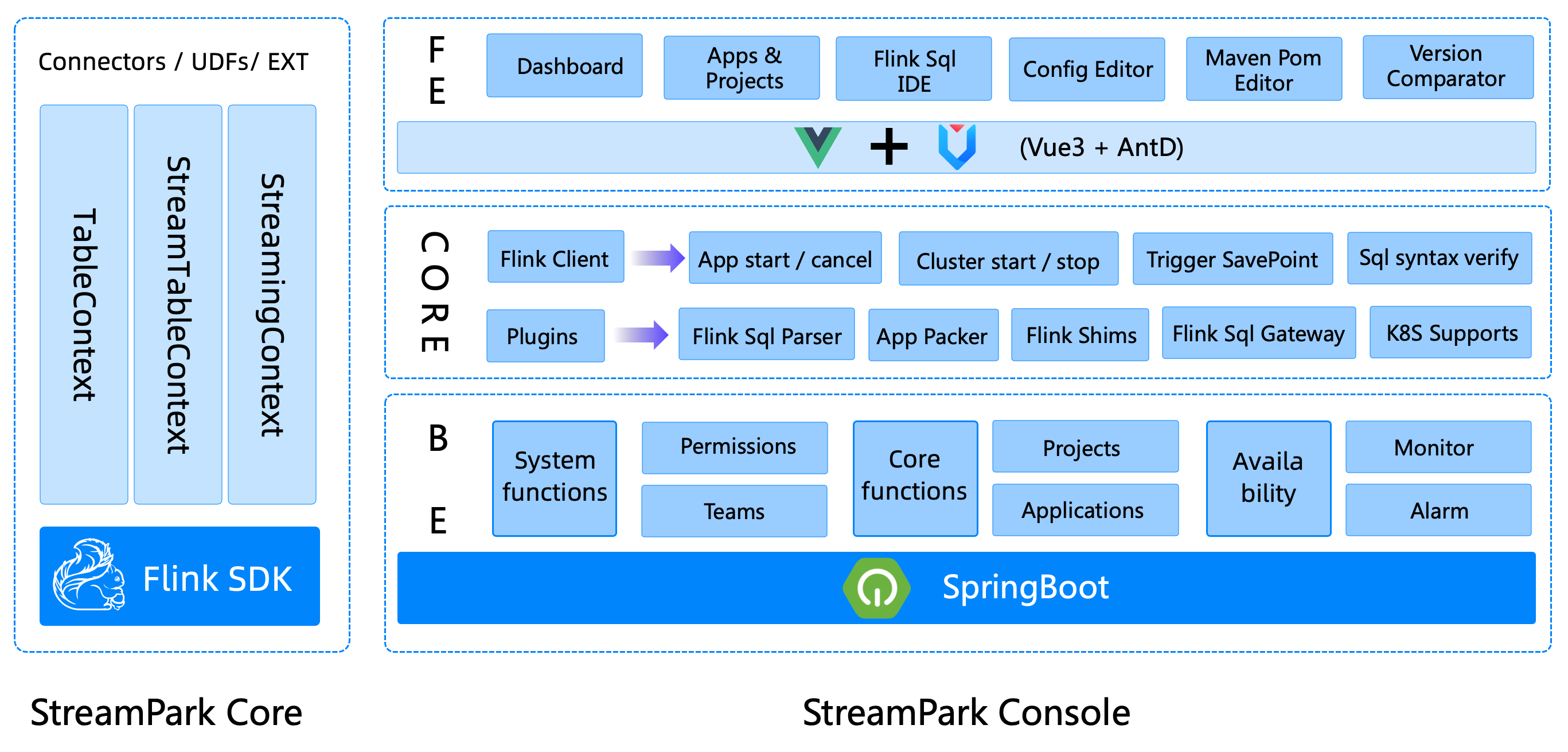
Programming paradigm
streampark-core is positioned as a programming time framework, rapid development scaffolding, specifically created to simplify Flink development. Developers will use this module during the development phase. Let's take a look at what the programming paradigm of DataStream and Flink Sql with StreamPark looks like, and what the specifications and requirements are.
DataStream
StreamPark provides both scala and Java APIs to develop DataStream programs, the specific code development is as follows.
- Scala
- Java
import org.apache.streampark.flink.core.scala.FlinkStreaming
import org.apache.flink.api.scala._
object MyFlinkApp extends FlinkStreaming {
override def handle(): Unit = {
...
}
}
public class MyFlinkJavaApp {
public static void main(String[] args) {
StreamEnvConfig JavaConfig = new StreamEnvConfig(args, (environment, parameterTool) -> {
//The user can set parameters for the environment...
System.out.println("environment argument set...");
});
StreamingContext context = new StreamingContext(JavaConfig);
....
context.start();
}
}
To develop with the scala API, the program must inherit from FlinkStreaming. After inheritance, it is mandatory for developers to implement the handle() method, which is the entry point for users to write code, and the streamingContext for developers to use.
Development with the Java API can not omit the main() method due to the limitations of the language itself, so it will be a standard main() function,. The user needs to create the StreamingContext manually. StreamingContext is a very important class, which will be introduced later.
The above lines of scala and Java code are the basic skeleton code necessary to develop DataStream with StreamPark. Developing a DataStream program with StreamPark. Starting from these lines of code, Java API development requires the developer to manually start the task start.
Flink Sql
The TableEnvironment is used to create the contextual execution environment for Table & SQL programs and is the entry point for Table & SQL programs. The main functions of the TableEnvironment include: interfacing with external systems, registering and retrieving tables and metadata, executing SQL statements, and providing more detailed configuration options.
The Flink community has been promoting the batch processing capability of DataStream and unifying the stream-batch integration, and in Flink 1.12, the stream-batch integration is truly unified, many historical APIs such as: DataSet API, BatchTableEnvironment API, etc. are deprecated and retired from the history stage. TableEnvironment** and StreamTableEnvironment.
StreamPark provides a more convenient API for the development of TableEnvironment and StreamTableEnvironment environments.
TableEnvironment
To develop Table & SQL jobs, TableEnvironment will be the recommended entry class for Flink, supporting both Java API and Scala API, the following code demonstrates how to develop a TableEnvironment type job in StreamPark
- Scala
- Java
import org.apache.streampark.flink.core.scala.FlinkTable
object TableApp extends FlinkTable {
override def handle(): Unit = {
...
}
}
import org.apache.streampark.flink.core.scala.TableContext;
import org.apache.streampark.flink.core.scala.util.TableEnvConfig;
public class JavaTableApp {
public static void main(String[] args) {
TableEnvConfig tableEnvConfig = new TableEnvConfig(args, null);
TableContext context = new TableContext(tableEnvConfig);
...
context.start("Flink SQl Job");
}
}
The above lines of Scala and Java code are the essential skeleton code for developing a TableEnvironment with StreamPark.
Scala API must inherit FlinkTable, Java API development needs to manually construct TableContext, and the developer needs to manually start the task start.
StreamTableEnvironment
StreamTableEnvironment is used in stream computing scenarios, where the object of stream computing is a DataStream. Compared to TableEnvironment, StreamTableEnvironment provides an interface to convert between DataStream and Table. If your application is written using the DataStream API in addition to the Table API & SQL, you need to use the StreamTableEnvironment.
The following code demonstrates how to develop a StreamTableEnvironment type job in StreamPark.
- Scala
- Java
package org.apache.streampark.test.tablesql
import org.apache.streampark.flink.core.scala.FlinkStreamTable
object StreamTableApp extends FlinkStreamTable {
override def handle(): Unit = {
...
}
}
import org.apache.streampark.flink.core.scala.StreamTableContext;
import org.apache.streampark.flink.core.scala.util.StreamTableEnvConfig;
public class JavaStreamTableApp {
public static void main(String[] args) {
StreamTableEnvConfig JavaConfig = new StreamTableEnvConfig(args, null, null);
StreamTableContext context = new StreamTableContext(JavaConfig);
...
context.start("Flink SQl Job");
}
}
The above lines of scala and Java code are the essential skeleton code for developing StreamTableEnvironment with StreamPark, and for developing StreamTableEnvironment programs with StreamPark. Starting from these lines of code, Java code needs to construct StreamTableContext manually, and Java API development requires the developer to start the task start manually.
RunTime Context
RunTime Context - StreamingContext , TableContext , StreamTableContext are three very important objects in StreamPark, next we look at the definition and role of these three Context.
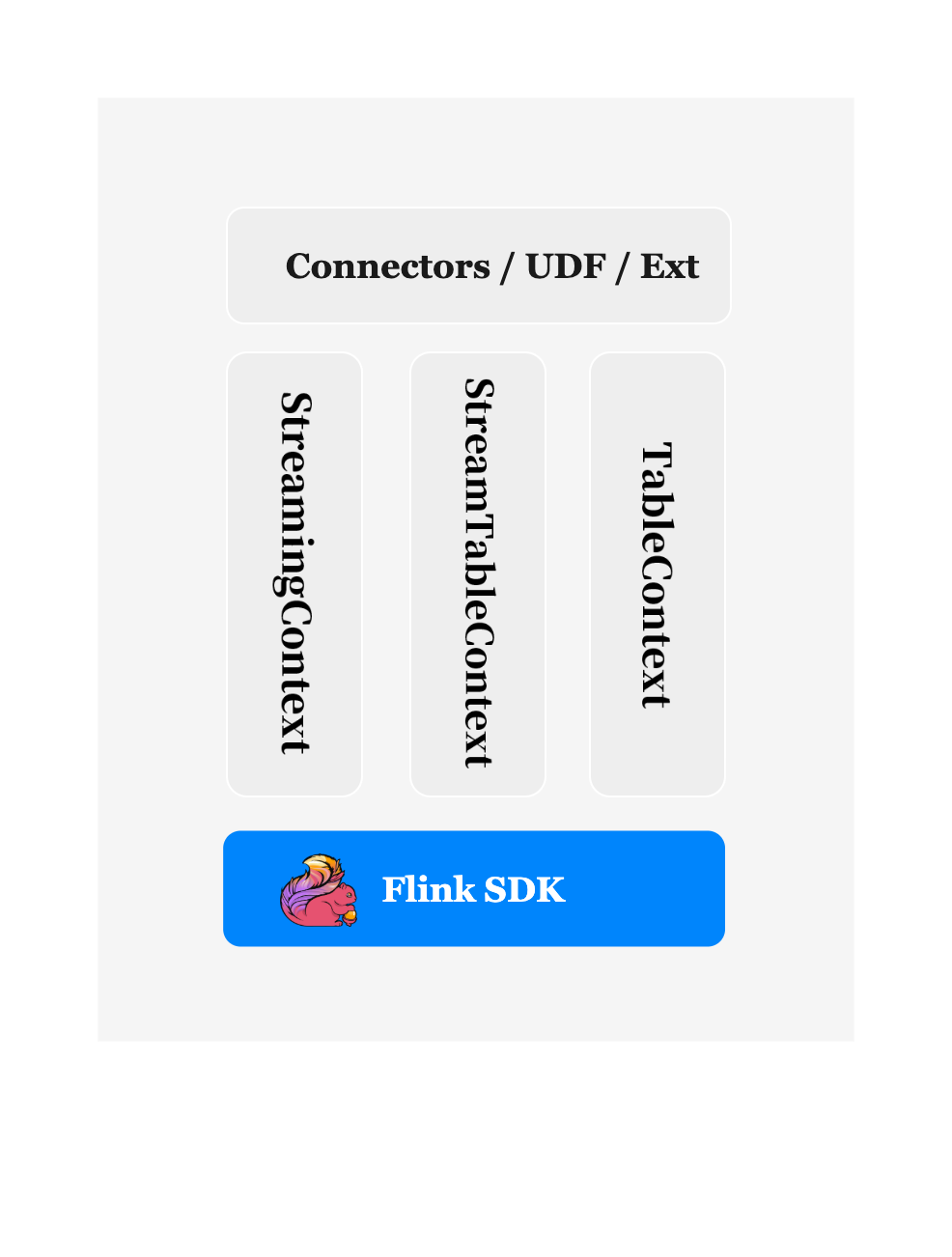
StreamingContext
StreamingContext inherits from StreamExecutionEnvironment, adding ParameterTool on top of StreamExecutionEnvironment, which can be simply understood as:
StreamingContext = ParameterTool + StreamExecutionEnvironment
The specific definitions are as follows:
class StreamingContext(val parameter: ParameterTool, private val environment: StreamExecutionEnvironment)
extends StreamExecutionEnvironment(environment.getJavaEnv) {
/**
* for scala
*
* @param args
*/
def this(args: (ParameterTool, StreamExecutionEnvironment)) = this(args._1, args._2)
/**
* for Java
*
* @param args
*/
def this(args: StreamEnvConfig) = this(FlinkStreamingInitializer.initJavaStream(args))
...
}
This object is very important and will be used throughout the lifecycle of the task in the DataStream job. The StreamingContext itself inherits from the StreamExecutionEnvironment, and the configuration file is fully integrated into the StreamingContext, so that it is very easy to get various parameters from the StreamingContext.
In StreamPark, StreamingContext is also the entry class for the Java API to write DataStream jobs, one of the constructors of StreamingContext is specially built for the Java API, the constructor is defined as follows:
/**
* for Java
* @param args
*/
def this(args: StreamEnvConfig) = this(FlinkStreamingInitializer.initJavaStream(args))
From the above constructor you can see that to create StreamingContext, you need to pass in a StreamEnvConfig object. StreamEnvConfig is defined as follows:
class StreamEnvConfig(val args: Array[String], val conf: StreamEnvConfigFunction)
In the constructor of StreamEnvConfig,
argsis the start parameter and must be theargsin themainmethodconfis aFunctionof typeStreamEnvConfigFunction
The definition of StreamEnvConfigFunction is as follows.
@FunctionalInterface
public interface StreamEnvConfigFunction {
/**
* Used to initialize the StreamExecutionEnvironment, for the function can be implemented, customize the parameters to be set...
*
* @param environment
* @param parameterTool
*/
void configuration(StreamExecutionEnvironment environment, ParameterTool parameterTool);
}
The purpose of the Function is to allow the developer to set more parameters by means of hooks, which will pass the parameter (parsing all parameters in the configuration file) and the initialized StreamExecutionEnvironment object to the developer to set more parameters, e.g.:
StreamEnvConfig JavaConfig = new StreamEnvConfig(args, (environment, parameterTool) -> {
System.out.println("environment argument set...");
environment.getConfig().enableForceAvro();
});
StreamingContext context = new StreamingContext(JavaConfig);
TableContext
TableContext inherits from TableEnvironment. On top of TableEnvironment, it adds ParameterTool, which is used to create the contextual execution environment for Table & SQL programs. It can be simply understood as :
TableContext = ParameterTool + TableEnvironment
The specific definitions are as follows:
class TableContext(val parameter: ParameterTool,
private val tableEnv: TableEnvironment)
extends TableEnvironment
with FlinkTableTrait {
/**
* for scala
*
* @param args
*/
def this(args: (ParameterTool, TableEnvironment)) = this(args._1, args._2)
/**
* for Java
* @param args
*/
def this(args: TableEnvConfig) = this(FlinkTableInitializer.initJavaTable(args))
...
}
In StreamPark, TableContext is also the entry class for the Java API to write Table Sql jobs of type TableEnvironment. One of the constructor methods of TableContext is a constructor specifically built for the Java API, which is defined as follows:
/**
* for Java
* @param args
*/
def this(args: TableEnvConfig) = this(FlinkTableInitializer.initJavaTable(args))
From the above constructor you can see that to create a TableContext, you need to pass in a TableEnvConfig object. TableEnvConfig is defined as follows:
class TableEnvConfig(val args: Array[String], val conf: TableEnvConfigFunction)
In the constructor method of TableEnvConfig,
argsis the start parameter, and is theargsin themainmethod.confis aFunctionof typeTableEnvConfigFunction
The definition of TableEnvConfigFunction is as follows.
@FunctionalInterface
public interface TableEnvConfigFunction {
/**
* Used to initialize the TableEnvironment, for the function can be implemented, customize the parameters to be set...
*
* @param tableConfig
* @param parameterTool
*/
void configuration(TableConfig tableConfig, ParameterTool parameterTool);
}
The purpose of the Function is to allow the developer to set more parameters by hooking the parameter (parsing all parameters in the configuration file) and the TableConfig object in the initialized TableEnvironment to the developer to set more parameters, such as:
TableEnvConfig config = new TableEnvConfig(args,(tableConfig,parameterTool)->{
tableConfig.setLocalTimeZone(ZoneId.of("Asia/Shanghai"));
});
TableContext context = new TableContext(config);
...
StreamTableContext
StreamTableContext inherits from StreamTableEnvironment and is used in stream computing scenarios. The object of stream computation is DataStream. Compared to TableEnvironment, StreamTableEnvironment provides an interface for conversion between DataStream and Table.
StreamTableContext adds ParameterTool on top of StreamTableEnvironment and directly accesses the StreamTableEnvironment API, which can be easily understood as:
StreamTableContext = ParameterTool + StreamTableEnvironment + StreamExecutionEnvironment
The specific definitions are as follows:
class StreamTableContext(val parameter: ParameterTool,
private val streamEnv: StreamExecutionEnvironment,
private val tableEnv: StreamTableEnvironment)
extends StreamTableEnvironment
with FlinkTableTrait {
/**
* Once the Table is converted to a DataStream,
* The DataStream job must be executed using the execute method of the StreamExecutionEnvironment.
*/
private[scala] var isConvertedToDataStream: Boolean = false
/**
* for scala
*
* @param args
*/
def this(args: (ParameterTool, StreamExecutionEnvironment, StreamTableEnvironment)) =
this(args._1, args._2, args._3)
/**
* for Java
*
* @param args
*/
def this(args: StreamTableEnvConfig) = this(FlinkTableInitializer.initJavaStreamTable(args))
...
}
In StreamPark, StreamTableContext is the entry class for the Java API to write Table Sql jobs of type StreamTableEnvironment. One of the constructors of StreamTableContext is a function built specifically for the Java API, which is defined as follows:
/**
* for Java
*
* @param args
*/
def this(args: StreamTableEnvConfig) = this(FlinkTableInitializer.initJavaStreamTable(args))
From the above constructor you can see that to create StreamTableContext, you need to pass in a StreamTableEnvConfig object. StreamTableEnvConfig is defined as follows:
class StreamTableEnvConfig (
val args: Array[String],
val streamConfig: StreamEnvConfigFunction,
val tableConfig: TableEnvConfigFunction
)
The constructor of StreamTableEnvConfig has three parameters:
argsis the start parameter, and must beargsin themainmethodstreamConfigis aFunctionof typeStreamEnvConfigFunction.tableConfigis aFunctionof typeTableEnvConfigFunction
The definitions of StreamEnvConfigFunction and TableEnvConfigFunction have been described above and will not be repeated here.
The purpose of this Function is to allow the developer to set more parameters by means of hooks. Unlike the other parameter settings above, this Function provides the opportunity to set both the StreamExecutionEnvironment and the TableEnvironment, which will pass the parameter and the initialized StreamExecutionEnvironment ' and the TableConfigobject in theTableEnvironment` are passed to the developer for additional parameter settings, such as:
StreamTableEnvConfig JavaConfig = new StreamTableEnvConfig(args, (environment, parameterTool) -> {
environment.getConfig().enableForceAvro();
}, (tableConfig, parameterTool) -> {
tableConfig.setLocalTimeZone(ZoneId.of("Asia/Shanghai"));
});
StreamTableContext context = new StreamTableContext(JavaConfig);
...
You can use the StreamExecutionEnvironment API directly in the StreamTableContext, methods prefixed with $ are the StreamExecutionEnvironment API.
Life Cycle
The lifecycle concept is currently only available for the scala API. this lifecycle explicitly defines the entire process of running a task, which is executed according to this lifecycle as long as it is inherited from FlinkStreaming or FlinkTable or StreamingTable. The core methods of the lifecycle are as follows.
final def main(args: Array[String]): Unit = {
init(args)
ready()
handle()
jobExecutionResult = context.start()
destroy()
}
private[this] def init(args: Array[String]): Unit = {
SystemPropertyUtils.setAppHome(KEY_APP_HOME, classOf[FlinkStreaming])
context = new StreamingContext(FlinkStreamingInitializer.initStream(args, config))
}
/**
* Users can override the sub-method...
*
*/
def ready(): Unit = {}
def config(env: StreamExecutionEnvironment, parameter: ParameterTool): Unit = {}
def handle(): Unit
def destroy(): Unit = {}
The life cycle is as follows.
- init Stages of configuration file initialization
- config Stage of manual parameter setting by the developer
- ready Stage for executing custom actions before starting
- handle Stages of developer code access
- start Stages of program initiation
- destroy Stages of destruction
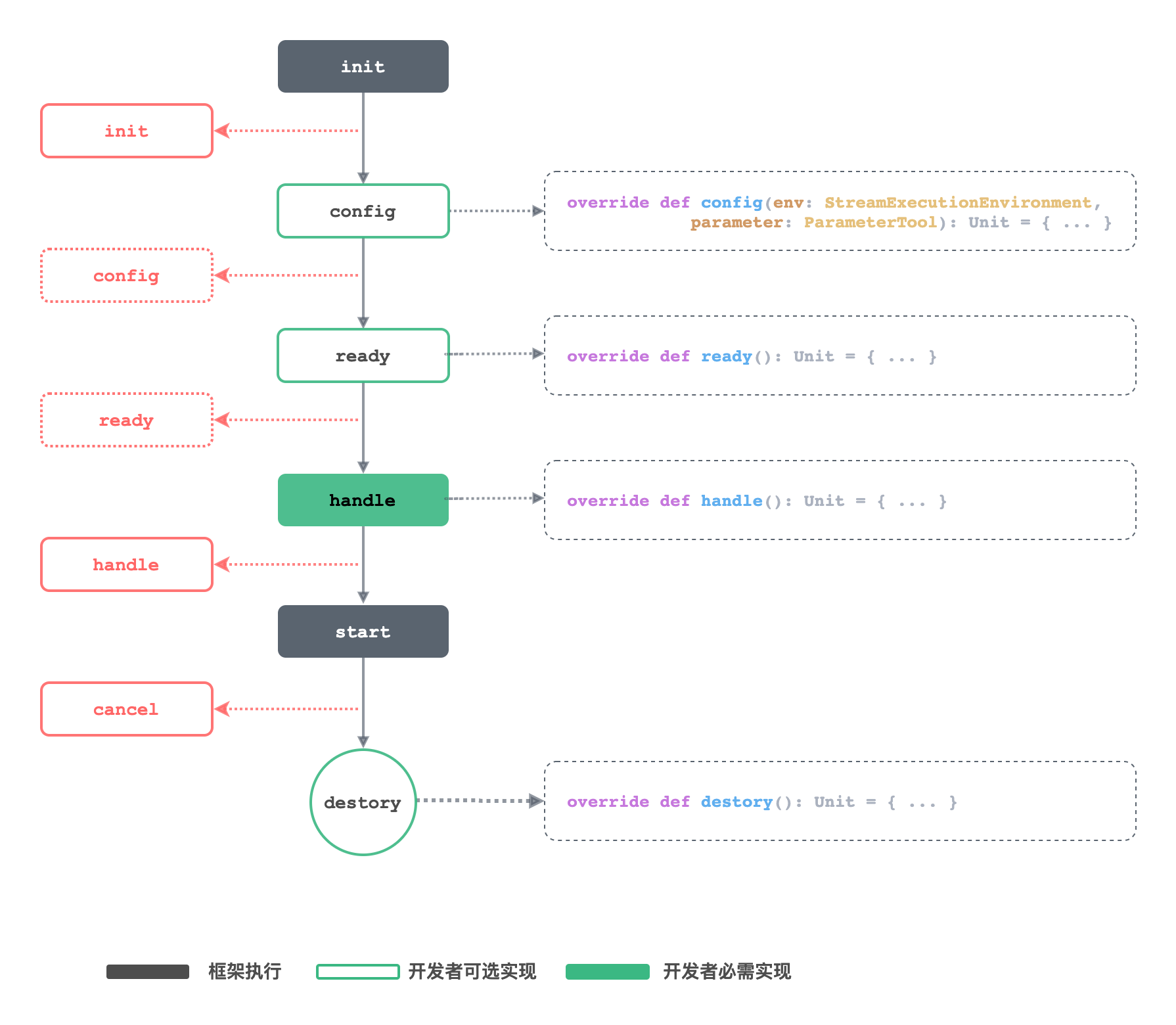
Life Cycle - init
In the init phase, the framework automatically parses the incoming configuration file and initializes the StreamExecutionEnvironment according to the various parameters defined inside. This step is automatically executed by the framework and does not require developer involvement.
Life Cycle — config
The purpose of the config phase is to allow the developer to set more parameters (other than the agreed configuration file), by means of hooks. The config phase passes parameter (all parameters in the configuration file parsed in the init phase) and the StreamExecutionEnvironment object initialized in the init phase to the developer,this allows the developer to configure more parameters.
The config stage is an optional stage that requires developer participation.
Life Cycle — ready
The ready stage is an entry point for the developer to do other actions after the parameters have been set, and is done after **initialization is complete **before the program is started.
The ready stage is a stage that requires developer participation and is optional.
Life Cycle — handle
The handle stage is the stage of accessing the code written by the developer, it is the entrance to the code written by the developer and is the most important stage, this handle method will force the developer to implement.
The handle stage is a mandatory stage that requires developer participation.
Life Cycle — start
The start phase, which starts the task, is executed automatically by the framework.
Life Cycle — destroy
The destroy phase is the last phase before jvm exits after the program has finished running, and is generally used to wrap up the work.
The destroy stage is an optional stage that requires developer participation.
Catalog Structure
The recommended project directory structure is as follows, please refer to the directory structure and configuration in StreamPark-flink-quickstart
.
|── assembly
│ ├── bin
│ │ ├── startup.sh //Launch Script
│ │ ├── setclasspath.sh //ava environment variables related to the script (internal use of the framework, developers do not need to pay attention to)
│ │ ├── shutdown.sh //Task stop script (not recommended)
│ │ └── flink.sh //the script that internal use to, when starting (this script is used internally in the framework, the developer does not need to pay attention to)
│ │── conf
│ │ ├── test
│ │ │ ├── application.yaml //Configuration file for the test phase
│ │ │ └── sql.yaml //flink sql
│ │ │
│ │ ├── prod
│ │ │ ├── application.yaml //Profiles for the production (prod) stage
│ │ │ └── sql.yaml //flink sql
│ │── logs //logs Catalog
│ └── temp
│
│── src
│ └── main
│ ├── Java
│ ├── resources
│ └── scala
│
│── assembly.xml
│
└── pom.xml
assembly.xml is the configuration file needed for the assembly packaging plugin, defined as follows:
<assembly>
<id>bin</id>
<formats>
<format>tar.gz</format>
</formats>
<fileSets>
<fileSet>
<directory>assembly/bin</directory>
<outputDirectory>bin</outputDirectory>
<fileMode>0755</fileMode>
</fileSet>
<fileSet>
<directory>${project.build.directory}</directory>
<outputDirectory>lib</outputDirectory>
<fileMode>0755</fileMode>
<includes>
<include>*.jar</include>
</includes>
<excludes>
<exclude>original-*.jar</exclude>
</excludes>
</fileSet>
<fileSet>
<directory>assembly/conf</directory>
<outputDirectory>conf</outputDirectory>
<fileMode>0755</fileMode>
</fileSet>
<fileSet>
<directory>assembly/logs</directory>
<outputDirectory>logs</outputDirectory>
<fileMode>0755</fileMode>
</fileSet>
<fileSet>
<directory>assembly/temp</directory>
<outputDirectory>temp</outputDirectory>
<fileMode>0755</fileMode>
</fileSet>
</fileSets>
</assembly>
Packaged Deployment
The recommended packaging mode in streampark-flink-quickstart is recommended. It runs maven package directly to generate a standard StreamPark recommended project package, after unpacking the directory structure is as follows.
.
StreamPark-flink-quickstart-1.0.0
├── bin
│ ├── startup.sh //Launch Script
│ ├── setclasspath.sh //Java environment variable-related scripts (used internally, not of concern to users)
│ ├── shutdown.sh //Task stop script (not recommended)
│ ├── flink.sh //Scripts used internally at startup (used internally, not of concern to the user)
├── conf
│ ├── application.yaml //Project's configuration file
│ ├── sql.yaml // flink sql file
├── lib
│ └── StreamPark-flink-quickstart-1.0.0.jar //The project's jar package
└── temp
Start command
The application.yaml and sql.yaml configuration files need to be defined before starting. If the task to be started is a DataStream task, just follow the configuration file directly after startup.sh.
bin/startup.sh --conf conf/application.yaml
If the task you want to start is the Flink Sql task, you need to follow the configuration file and sql.yaml.
bin/startup.sh --conf conf/application.yaml --sql conf/sql.yaml