项目配置
配置在StreamPark中是非常重要的概念,先说说为什么需要配置
为什么需要配置
开发DataStream程序,大体流程都可以抽象为以下4步
- StreamExecutionEnvironment初始并配置
- Source接入数据
- Transformation逻辑处理
- Sink结果数据落地
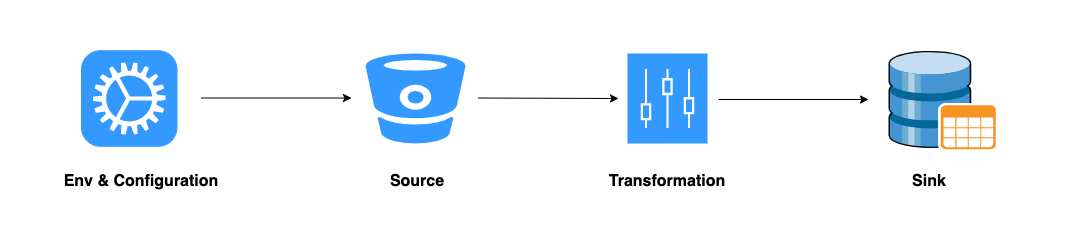
开发DataStream程序都需要定义Environment初始化并且配置环境相关的参数,一般我们都会在第一步初始化Environment并配置各种参数,配置的参数大概有以下几类
- Parallelism 默认并行度配置
- TimeCharacteristic 时间特征配置
- checkpoint 检查点的相关配置
- Watermark 相关配置
- State Backend 状态后端配置
- Restart Strategy 重启策略配置
- 其他配置...
以上的配置基本都是比较普遍且通用的,是每个程序上来第一步就要定义的,是一项重复的工作
当程序写好后,要上线运行,任务启动提交都差不多用下面的命令行的方式,设置各种启动参数, 这时就得开发�者清楚的知道每个参数的含义,如果再设置几个运行时资源参数,那启动命名会很长,可读性很差,参数解析用到了强校验,一旦设置错误,会直接报错,导致任务启动失败,最直接的异常是 找不到程序的jar
flink run -m yarn-cluster -p 1 -c com.xx.Main job.jar
开发Flink Sql程序,也需要设置一系列环境参数,除此之外,如果要使用纯sql的方式开发,举一个最简单的例子,代码如下
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
public class JavaTableApp {
public static void main(String[] args) {
EnvironmentSettings bbSettings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()
.build();
TableEnvironment bsTableEnv = TableEnvironment.create(bbSettings);
String sourceDDL = "CREATE TABLE datagen ( " +
" f_random INT, " +
" f_random_str STRING, " +
" ts AS localtimestamp, " +
" WATERMARK FOR ts AS ts " +
") WITH ( " +
" 'connector' = 'datagen', " +
" 'rows-per-second'='10', " +
" 'fields.f_random.min'='1', " +
" 'fields.f_random.max'='5', " +
" 'fields.f_random_str.length'='10' " +
")";
bsTableEnv.executeSql(sourceDDL);
String sinkDDL = "CREATE TABLE print_table (" +
" f_random int," +
" c_val bigint, " +
" wStart TIMESTAMP(3) " +
") WITH ('connector' = 'print') ";
bsTableEnv.executeSql(sinkDDL);
}
}
我们会看到除了设置 EnvironmentSettings 参数之外,剩下的几乎大段大段的代码都是在写 sql,用java代码拼接各种sql,这种编码的方式,极不优雅,如果业务复杂,更是难以维护,而且会发现,整个编码的模式是统一的, 都是声明一段sql,然后调用 executeSql 方法
我们的设想是:能不能以一种更好的方式将这种重复的工作简单化,将DataStream和Flink Sql任务中的一些环境初始化相关的参数和启动相关参数简化,最好一行代码都不写,针对Flink Sql作业,也不想在代码里写大段的sql,能不能以一种更优雅的方式解决?
答案是肯定的
针对参数设置的问题,在StreamPark中提出统一程序配置的概念,把程序的一系列参数从开发到部署阶段按照特定的格式配置到application.yml里,抽象出
一个通用的配置模板,按照这种规定的格式将上述配置的各项参数在配置文件里定义出来,在程序启动的时候将这个项目配置传入到程序中即可完成环境的初始化工作,在任务启动的时候也会自动识别启动时的参数.
针对Flink Sql作业在代码里写sql的问题,StreamPark针对Flink Sql作业做了更高层级封装和抽象,开发者只需要将sql按照一定的规范要求定义到application.yaml中,在程序启动时传入该文件到主程序中, 就会自动按照要求加载执行sql
下面我们来详细看看这个配置文件的各项配置都是如何进行配置的,有哪些注意事项
flink:
option:
target: yarn-per-job
detached:
shutdownOnAttachedExit:
zookeeperNamespace:
jobmanager:
property: #@see: https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/deployment/config/
$internal.application.main: org.apache.streampark.flink.quickstart.QuickStartApp
pipeline.name: streampark-quickstartApp
yarn.application.queue:
taskmanager.numberOfTaskSlots: 1
parallelism.default: 2
jobmanager.memory:
flink.size:
heap.size:
jvm-metaspace.size:
jvm-overhead.max:
off-heap.size:
process.size:
taskmanager.memory:
flink.size:
framework.heap.size:
framework.off-heap.size:
managed.size:
process.size:
task.heap.size:
task.off-heap.size:
jvm-metaspace.size:
jvm-overhead.max:
jvm-overhead.min:
managed.fraction: 0.4
pipeline:
auto-watermark-interval: 200ms
# checkpoint
execution:
checkpointing:
mode: EXACTLY_ONCE
interval: 30s
timeout: 10min
unaligned: false
externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
# state backend
state:
backend: hashmap # Special note: flink1.12 optional configuration ('jobmanager', 'filesystem', 'rocksdb'), flink1.12+ optional configuration ('hashmap', 'rocksdb'),
backend.incremental: true
checkpoint-storage: filesystem
savepoints.dir: file:///tmp/chkdir
checkpoints.dir: file:///tmp/chkdir
# restart strategy
restart-strategy: fixed-delay # Restart strategy [(fixed-delay|failure-rate|none) a total of 3 configurable strategies]
restart-strategy.fixed-delay:
attempts: 3
delay: 5000
restart-strategy.failure-rate:
max-failures-per-interval:
failure-rate-interval:
delay:
# table
table:
table.local-time-zone: default # @see https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/dev/table/config/
# kafka source
app:
kafka.source:
bootstrap.servers: kfk1:9092,kfk2:9092,kfk3:9092
topic: test_user
group.id: user_01
auto.offset.reset: earliest
# mysql
jdbc:
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://localhost:3306/test?useSSL=false&allowPublicKeyRetrieval=true
username: root
password: 123456
sql:
flinksql: |
CREATE TABLE datagen (
f_sequence INT,
f_random INT,
f_random_str STRING,
ts AS localtimestamp,
WATERMARK FOR ts AS ts
) WITH (
'connector' = 'datagen',
-- optional options --
'rows-per-second'='5',
'fields.f_sequence.kind'='sequence',
'fields.f_sequence.start'='1',
'fields.f_sequence.end'='1000',
'fields.f_random.min'='1',
'fields.f_random.max'='1000000',
'fields.f_random_str.length'='10'
);
CREATE TABLE print_table (
f_sequence INT,
f_random INT,
f_random_str STRING
) WITH (
'connector' = 'print'
);
INSERT INTO print_table select f_sequence,f_random,f_random_str from datagen;
从全局看参数分为三大类: flink, app, sql, 各自作用如下:
flink
flink下放的是作业的基础参数, 包括 option 和 property, table 三大类:
option
option下放�的参数是flink run 下支持的参数,目前支持的参数如下
| 短参数 | 完整参数(前缀"--") | 有效 | 取值范围值或类型 | 作用描述 |
| -t | target | yarn-per-job | application | 部署方式(目前只支持yarn-per-job,application) | |
| -d | detached | true | false | 是否以detached模式启动 | |
| -n | allowNonRestoredState | true | false | 从savePoint恢复失败时是否允许跳过该步骤 | |
| -sae | shutdownOnAttachedExit | true | false | attached模式下任务停止时是否关闭集群 | |
| -m | jobmanager | yarn-cluster | 连接地址 | JobManager的连接地址 | |
| -p | parallelism | int | 程序并行度 | |
| -c | class | String | 程序的main方法的全名称 |
parallelism (-p) 并行度不支持在option里配置,会在后面的property里配置
class (-c) 程序main不支持在option里配置,会在后面的property里配置
option下的参数必须是 完整参数名
property
property下放的参数是标准的flink参数(-D下的参数),flink所有的参数数据都可以在这里进行配置, 大致如下:
基础参数
基础参数可以配置的选项非常之多,这里举例5个最基础的设置
| 参数名称 | 作用描述 | 是否必须 |
| $internal.application.main | 程序的主类(main)的完整类名 | |
| yarn.application.name | 程序的名称(YARN中显示的任务名称) | |
| yarn.application.queue | 在YARN中运行的队列名称 | |
| taskmanager.numberOfTaskSlots | taskmanager Slot的数量 | |
| parallelism.default | 程序的并行 |
$internal.application.main 和 yarn.application.name 这两个参数是必须的
如您需要设置更多的参数,可参考这里
一定要将这些参数放到property下,并且参数名称要正确,StreamPark会自动解析这些参数并生效
Memory参数
Memory相关的参数设置也非常之多,一般常见的配置如下
| 参数名称 | 作用描述 |
| jobmanager.memory.heap.size | JobManager 的 JVM 堆内存 |
| jobmanager.memory.off-heap.size | JobManager 的堆外内存(直接内存或本地内存) |
| jobmanager.memory.jvm-metaspace.size | Flink JVM进程的Metaspace |
| jobmanager.memory.jvm-metaspace.size | Flink JVM进程的Metaspace |
| jobmanager.memory.jvm-overhead.min | Flink JVM进程的Metaspace |
| jobmanager.memory.jvm-metaspace.size | 用于其他 JVM 开销的本地内存 |
| jobmanager.memory.jvm-overhead.max | 用于其他 JVM 开销的本地内存 |
| jobmanager.memory.jvm-overhead.fraction | 用于其他 JVM开销的本地内存 |
| taskmanager.memory.framework.heap.size | 用于Flink 框架的JVM堆内存(进阶配置) |
| taskmanager.memory.task.heap.size | 由Flink管理的用于排序,哈希表,缓存状态后端的本地内存 |
| taskmanager.memory.managed.size | 用于其他 JVM 开销的本地内存 |
| taskmanager.memory.managed.fraction | 用于其他 JVM 开销的本地内存 |
| taskmanager.memory.framework.off-heap.size | 用于Flink框架的堆外内存(直接内存或本地内存)进阶配置 |
| taskmanager.memory.task.off-heap.size | 用于Flink应用的算子及用户代码的堆外内存(直接内存或本地内存) |
| taskmanager.memory.jvm-metaspace.size | Flink JVM 进程的 Metaspace |
同样,如你想配置更多的内存相关的参数,请参考这里 查看Flink Process Memory , jobmanager 及 taskmanager
相关的内存配置将这些参数放到property下,保证参数正确即可生效
配置总内存
Flink JVM 进程的进程总内存(Total Process Memory)包含了由 Flink 应用使用的内存(Flink 总内存)以及由运行 Flink 的 JVM 使用的内存。 Flink 总内存(Total Flink Memory)包括 JVM 堆内存(Heap Memory)和堆外内存(Off-Heap Memory)。 其中堆外内存包括直接内存(Direct Memory)和本地内存(Native Memory)

配置 Flink 进程内存最简单的方法是指定以下两个配置项中的任意一个:
| 配置项 | TaskManager 配置参数 | JobManager 配置参数 |
| Flink 总内存 | taskmanager.memory.flink.size | jobmanager.memory.flink.size |
| 进程总内存 | taskmanager.memory.process.size | jobmanager.memory.process.size |
不建议同时设置进程总内存和 Flink 总内存。 这可能会造成内存配置冲突,从而导致部署失败。 额外配置其他内存部分时,同样需要注意可能产生的配置冲突。
Table
在table下是Flink Sql相关的配置,目前支持的配置项和作用如下
- planner
- mode
- catalog
- database
| 配置项 | 作用描述 | 参数值 |
| planner | Table Planner | blink | old | any |
| mode | Table Mode | streaming | batch |
| catalog | 指定catalog,如指定初始化时会使用到 | |
| database | 指定database,如指定初始化时会使用到 |
app
我们将作业中需要的一些用户自定义的参数放到app下, 这里可以放用户需要的任意参数. 如,用户的需求是从kafka读取数据写入mysql, 则肯定会用到kafka和mysql的相关信息. 就可以定义到这里.
sql
sql是在flink sql作业中需要指定的, 我们提倡将sql语句本身抽取到配置文件里,使开发更简单, 该sql得遵循yaml文件的定义规则,具体内部sql格式的定义非常简单,如下:
sql: |
CREATE TABLE datagen (
f_sequence INT,
f_random INT,
f_random_str STRING,
ts AS localtimestamp,
WATERMARK FOR ts AS ts
) WITH (
'connector' = 'datagen',
-- optional options --
'rows-per-second'='5',
'fields.f_sequence.kind'='sequence',
'fields.f_sequence.start'='1',
'fields.f_sequence.end'='1000',
'fields.f_random.min'='1',
'fields.f_random.max'='1000',
'fields.f_random_str.length'='10'
);
CREATE TABLE print_table (
f_sequence INT,
f_random INT,
f_random_str STRING
) WITH (
'connector' = 'print'
);
INSERT INTO print_table select f_sequence,f_random,f_random_str from datagen;
sql为当前sql的id,必须是唯一的,后面的内容则是具体的sql
上面内容中 sql: 后面的 | 是必带的, 加上 | 会保留整段内容的格式,重点是保留了换行符, StreamPark封装了Flink Sql的提交,可以直接将多个Sql一次性定义出来,每个Sql必须用 ; 分割,每段 Sql也必须遵循Flink Sql规定的格式和规范
总结
本章节详细介绍了配置文件和sql文件的由来和具体配置,相信你已经有了一个初步的印象和概念,具体使用请查后续章节