Platform Deployment using Docker
This tutorial for docker deploy StreamPark
Prepare
Docker 1.13.1+ Docker Compose 1.28.0+
1. Install docker
To start the service with docker, you need to install docker first
2. Install docker-compose
To start the service with docker-compose, you need to install docker-compose first
Apache StreamPark™ Deployment
1. Apache StreamPark™ deployment based on h2 and docker-compose
This method is suitable for beginners to learn and become familiar with the features. The configuration will reset after the container is restarted. Below, you can configure Mysql or Pgsql for persistence.
2. Deployment
wget https://raw.githubusercontent.com/apache/incubator-streampark/dev/docker/docker-compose.yaml
wget https://raw.githubusercontent.com/apache/incubator-streampark/dev/docker/.env
docker-compose up -d
Once the service is started, StreamPark can be accessed through http://localhost:10000 and also through http://localhost:8081 to access Flink. Accessing the StreamPark link will redirect you to the login page, where the default user and password for StreamPark are admin and streampark respectively. To learn more about the operation, please refer to the user manual for a quick start.
3. Configure flink home
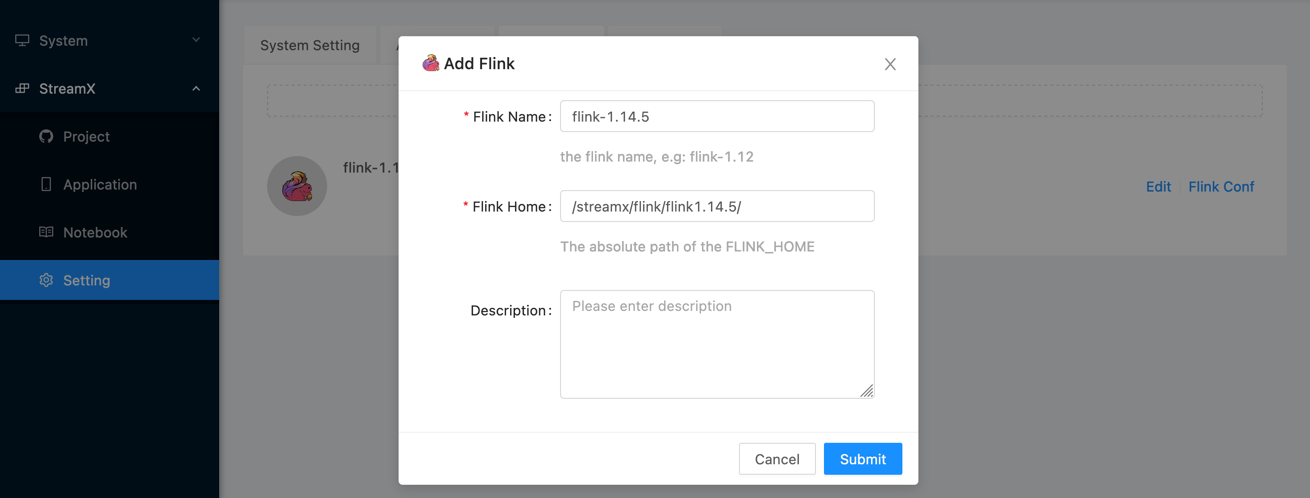
4. Configure flink-session cluster
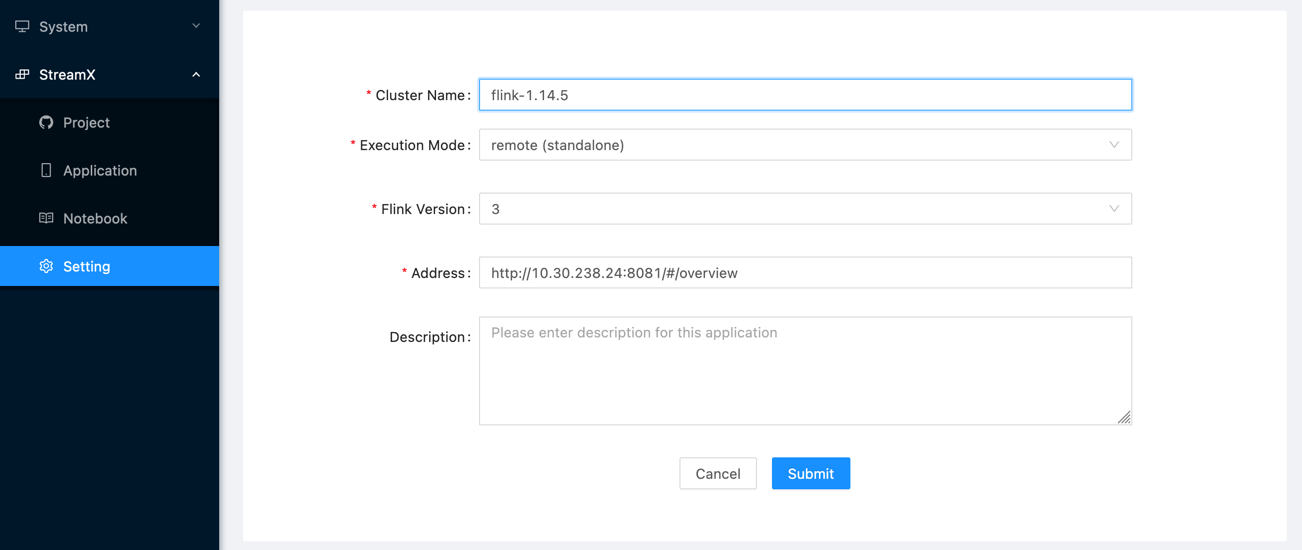
Note:When configuring the flink-sessin cluster address, the ip address is not localhost, but the host network ip, which can be obtained through ifconfig
5. Submit flink job
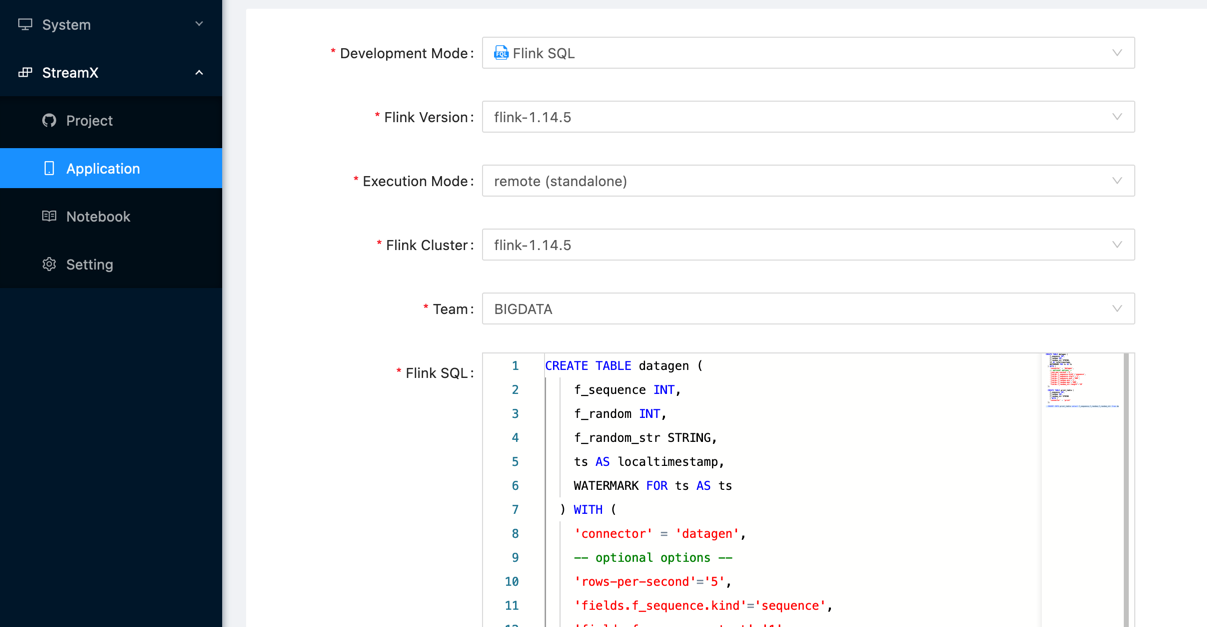
Use existing Mysql services
This approach is suitable for enterprise production, where you can quickly deploy StreamPark based on docker and associate it with an online database Note: The diversity of deployment support is maintained through the .env configuration file, make sure there is one and only one .env file in the directory
wget https://raw.githubusercontent.com/apache/incubator-streampark/dev/deploy/docker/docker-compose.yaml
wget https://raw.githubusercontent.com/apache/incubator-streampark/dev/deploy/docker/mysql/.env
vim .env
First, you need to create the "streampark" database in MySQL, and then manually execute the corresponding SQL found in the schema and data for the relevant data source.
After that, modify the corresponding connection information.
SPRING_PROFILES_ACTIVE=mysql
SPRING_DATASOURCE_URL=jdbc:mysql://localhost:3306/streampark?useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=false&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=GMT%2B8
SPRING_DATASOURCE_USERNAME=root
SPRING_DATASOURCE_PASSWORD=streampark
docker-compose up -d
Use existing Pgsql services
wget https://raw.githubusercontent.com/apache/incubator-streampark/dev/deploy/docker/docker-compose.yaml
wget https://raw.githubusercontent.com/apache/incubator-streampark/dev/deploy/docker/pgsql/.env
vim .env
Modify the corresponding connection information
SPRING_PROFILES_ACTIVE=pgsql
SPRING_DATASOURCE_URL=jdbc:postgresql://localhost:5432/streampark?stringtype=unspecified
SPRING_DATASOURCE_USERNAME=postgres
SPRING_DATASOURCE_PASSWORD=streampark
docker-compose up -d
Build images based on source code for Apache StreamPark™ deployment
git clone https://github.com/apache/incubator-streampark.git
cd incubator-streampark/deploy/docker
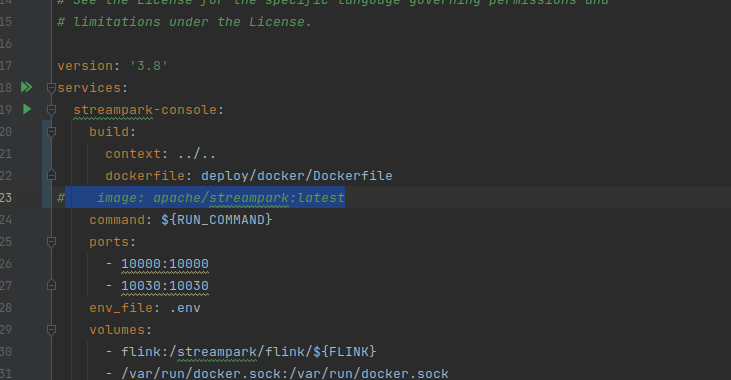
vim docker-compose
build:
context: ../..
dockerfile: deploy/docker/console/Dockerfile
# image: ${HUB}:${TAG}
docker-compose up -d
Docker-Compse Configuration
The docker-compose.yaml file will reference the configuration from the env file, and the modified configuration is as follows:
version: '3.8'
services:
## streampark-console container
streampark-console:
## streampark image
image: apache/streampark:latest
## streampark image startup command
command: ${
RUN_COMMAND}
ports:
- 10000:10000
## Environment configuration file
env_file: .env
environment:
## Declare environment variable
HADOOP_HOME: ${
HADOOP_HOME}
volumes:
- flink:/streampark/flink/${
FLINK}
- /var/run/docker.sock:/var/run/docker.sock
- /etc/hosts:/etc/hosts:ro
- ~/.kube:/root/.kube:ro
privileged: true
restart: unless-stopped
networks:
- streampark
## flink-jobmanager container
flink-jobmanager:
image: ${
FLINK_IMAGE}
ports:
- "8081:8081"
command: jobmanager
volumes:
- flink:/opt/flink
env_file: .env
restart: unless-stopped
privileged: true
networks:
- streampark
## streampark-taskmanager container
flink-taskmanager:
image: ${
FLINK_IMAGE}
depends_on:
- flink-jobmanager
command: taskmanager
deploy:
replicas: 1
env_file: .env
restart: unless-stopped
privileged: true
networks:
- streampark
networks:
streampark:
driver: bridge
volumes:
flink:
Finally, execute the start command:
cd deploy/docker
docker-compose up -d
You can use docker ps to check if the installation was successful. If the following information is displayed, it indicates a successful installation:

Uploading Configuration to the Container
In the previous env file, HADOOP_HOME was declared, with the corresponding directory being "/streampark/hadoop". Therefore, you need to upload the /etc/hadoop from the Hadoop installation package to the /streampark/hadoop directory. The commands are as follows:
## Upload Hadoop resources
docker cp entire etc directory streampark-docker_streampark-console_1:/streampark/hadoop
## Enter the container
docker exec -it streampark-docker_streampark-console_1 bash
## Check
ls

In addition, other configuration files, such as Maven's settings.xml file, are uploaded in the same manner.