Abstract: This article presents the production practices of StreamPark at Joyme, written by Qin Jiyong, a big data engineer at Joyme. The main contents include:
- Encountering StreamPark
- Flink SQL job development
- Custom code job development
- Monitoring and alerting
- Common issues
- Community impressions
- Summary
1 Encountering Apache StreamPark™
Encountering StreamPark was inevitable. Based on our existing real-time job development mode, we had to find an open-source platform to support our company's real-time business. Our current situation was as follows:
- We wrote jobs and packaged them to servers, then executed the Flink run command to submit them, which was a cumbersome and inefficient process.
- Flink SQL was submitted through a self-developed old platform. The developers of the old platform had left, and no one maintained the subsequent code, even if someone did, they would have to face the problem of high maintenance costs.
- Some of the authors were SparkStreaming jobs, with two sets of streaming engines and frameworks not unified, resulting in high development costs.
- Real-time jobs were developed in Scala and Java, with languages and technology stacks not unified.
For all these reasons, we needed an open-source platform to manage our real-time jobs, and we also needed to refactor to unify the development mode and language and centralize project management.
The first encounter with StreamPark basically confirmed our choice. We quickly deployed and installed according to the official documentation, performed some operations after setting up, and were greeted with a user-friendly interface. StreamPark's support for multiple versions of Flink, permission management, job monitoring, and other series of functions already met our needs well. Further understanding revealed that its community is also very active. We have witnessed the process of StreamPark's feature completion since version 1.1.0. The development team is very ambitious, and we believe they will continue to improve.
2 Development of Flink SQL Jobs
The Flink SQL development mode has brought great convenience. For some simple metric developments, it is possible to complete them with just a few SQL statements, without the need to write a single line of code. Flink SQL has facilitated the development work for many colleagues, especially since writing code can be somewhat difficult for those who work on warehouses.
To add a new task, you open the task addition interface of StreamPark, where the default Development Mode is Flink SQL mode. You can write the SQL logic directly in the Flink SQL section.
For the Flink SQL part, you can progressively write the logic SQL following the Flink official website's documentation. Generally, for our company, it consists of three parts: the Source connection, intermediate logic processing, and finally the Sink. Essentially, the Source is consuming data from Kafka, the logic layer will involve MySQL for dimension table queries, and the Sink part is mostly Elasticsearch, Redis, or MySQL.
1. Writing SQL
-- Connect kafka
CREATE TABLE source_table (
`Data` ROW<uid STRING>
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = '主题',
'connector.properties.bootstrap.servers'='broker地址',
'connector.startup-mode' = 'latest-offset',
'update-mode' = 'append',
'format.type' = 'json',
'connector.properties.group.id' = '消费组id',
'format.derive-schema' = 'true'
);
-- Landing table sink
CREATE TABLE sink_table (
`uid` STRING
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://xxx/xxx?useSSL=false',
'connector.username' = 'username',
'connector.password' = 'password',
'connector.table' = 'tablename',
'connector.write.flush.max-rows' = '50',
'connector.write.flush.interval' = '2s',
'connector.write.max-retries' = '3'
);
-- Code logic pass
INSERT INTO sink_table
SELECT Data.uid FROM source_table;
2. Add Dependency
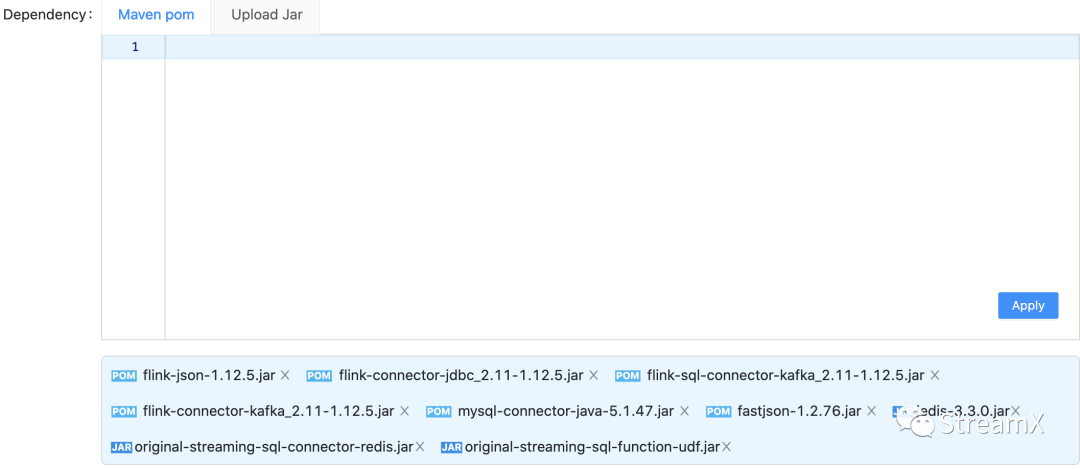
In terms of dependencies, it's an unique feature to Streampark. A complete Flink SQL job is innovatively split into two components within StreamPark: the SQL and the dependencies. The SQL part is easy to understand and requires no further explanation, but the dependencies are the various Connector JARs needed within the SQL, such as Kafka and MySQL Connectors. If these are used within the SQL, then these Connector dependencies must be introduced. In StreamPark, there are two ways to add dependencies: one is based on the standard Maven pom coordinates, and the other is by uploading the required Jars from a local source. These two methods can also be mixed and used as needed; simply apply, and these dependencies will be automatically loaded when the job is submitted.
3. Parameter Configuration
The task addition and modification page has listed some common parameter settings, and for more extensive configuration options, a yaml configuration file is provided. Here, we've only set up checkpoint and savepoint configurations. The first is the location of the checkpoint, and the second is the frequency of checkpoint execution. We haven't changed other configurations much; users can customize these settings as per their needs.
The rest of the parameter settings should be configured according to the specific circumstances of the job. If the volume of data processed is large or the logic is complex, it might require more memory and higher parallelism. Sometimes, adjustments need to be made multiple times based on the job's operational performance.

4. Dynamic Parameter Settings
Since our deployment mode is on Yarn, we configured the name of the Yarn queue in the dynamic options. Some configurations have also been set to enable incremental checkpoints and state TTL (time-to-live), all of which can be found on Flink's official website. Before, some jobs frequently encountered out-of-memory issues. After adding the incremental parameter and TTL, the job operation improved significantly. Also, in cases where the Flink SQL job involves larger states and complex logic, I personally feel that it's better to implement them through streaming code for more control.
- -Dyarn.application.queue=Yarn queue name
- -Dstate.backend.incremental=true
- -Dtable.exec.state.ttl=expiration time
After completing the configuration, submit & deploy it from the application interface.
3 Custom Code Job Development
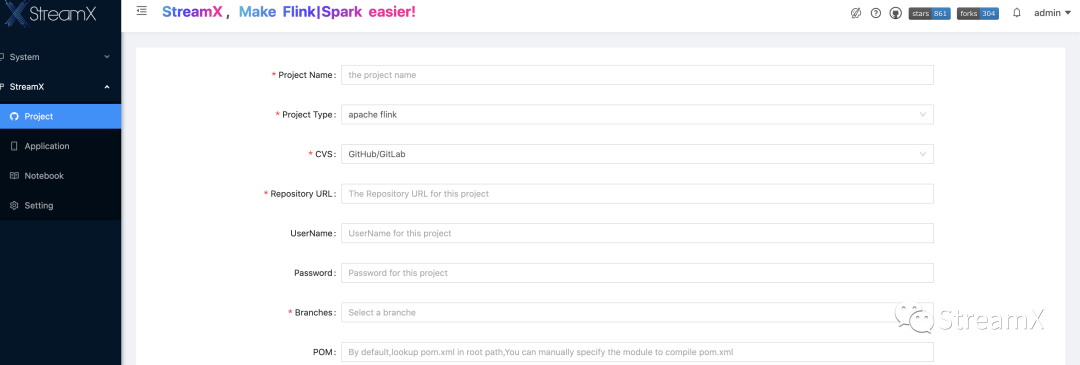
For streaming jobs, we use Flink Java for development, having refactored previous Spark Scala, Flink Scala, and Flink Java jobs and then integrated these projects together. The purpose of this integration is to facilitate maintenance. Custom code jobs require the submission of code to Git, followed by project configuration:
Once the configuration is completed, compile the corresponding project to finish the packaging phase. Thus, the Custom code jobs can also reference it. Compilation is required every time the code needs to go live; otherwise, only the last compiled code is available. Here's an issue: for security reasons, our company’s GitLab account passwords are regularly updated. This leads to a situation where the StreamPark projects have the old passwords configured, resulting in a failure when pulling projects from Git during compilation. To address this problem, we contacted the community and learned that the capability to modify projects has been added in the subsequent version 1.2.1.

To create a new task, select Custom code, choose the Flink version, select the project and the module Jar package, and choose the development application mode as Apache Flink® (standard Flink program), program main function entry class, and the task's name.
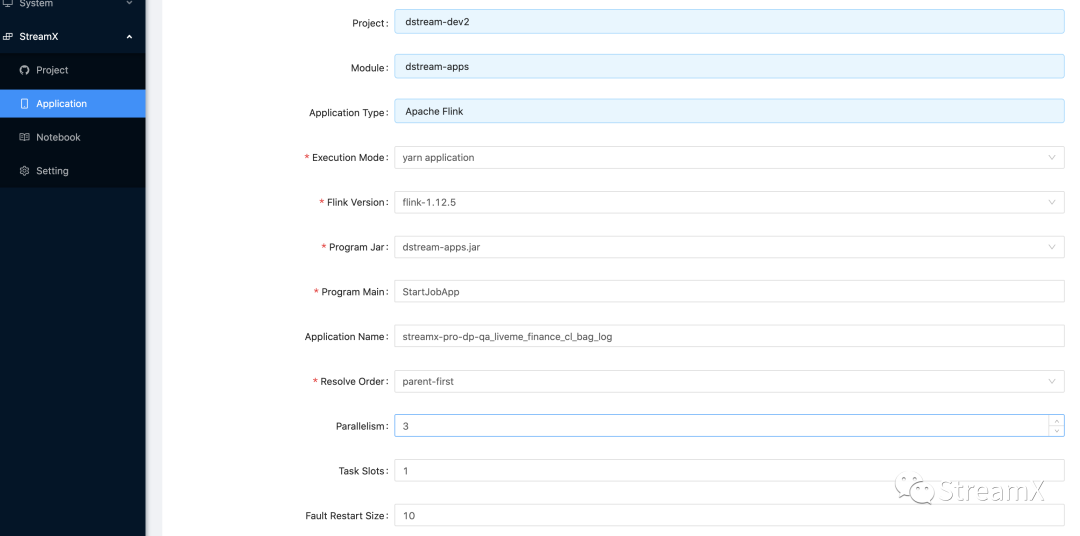
As well as the task’s parallelism, monitoring method, etc., memory size should be configured based on the needs of the task. Program Args, the program parameters, are defined according to the program's needs. For example: If our unified startup class is StartJobApp, to start a job, it's necessary to pass the full name of the job, informing the startup class which class to find to launch the task—essentially, which is a reflection mechanism. After the job configuration is complete, it is also submitted with Submit and then deployed from the application interface.
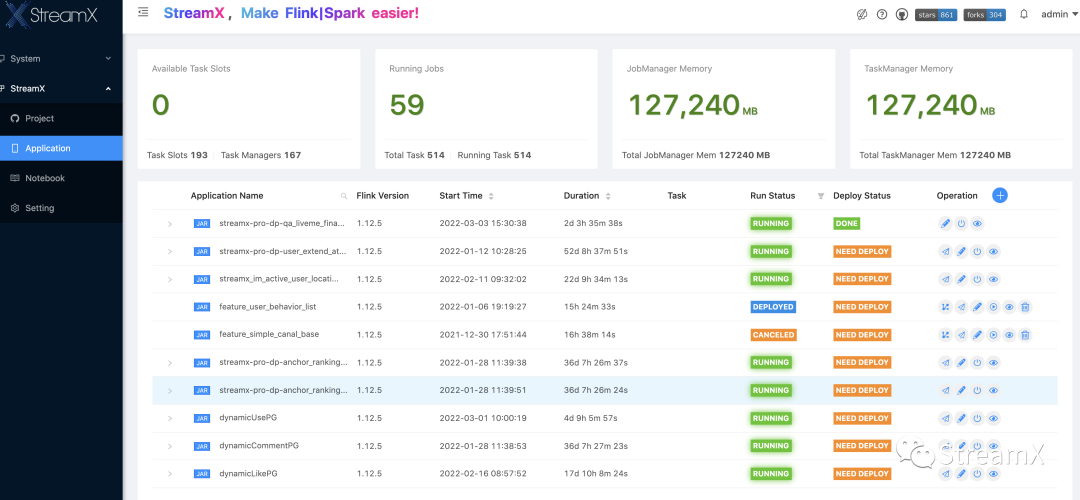
4 Monitoring and Alerts
The monitoring in StreamPark requires configuration in the setting module to set up the basic information for sending emails.
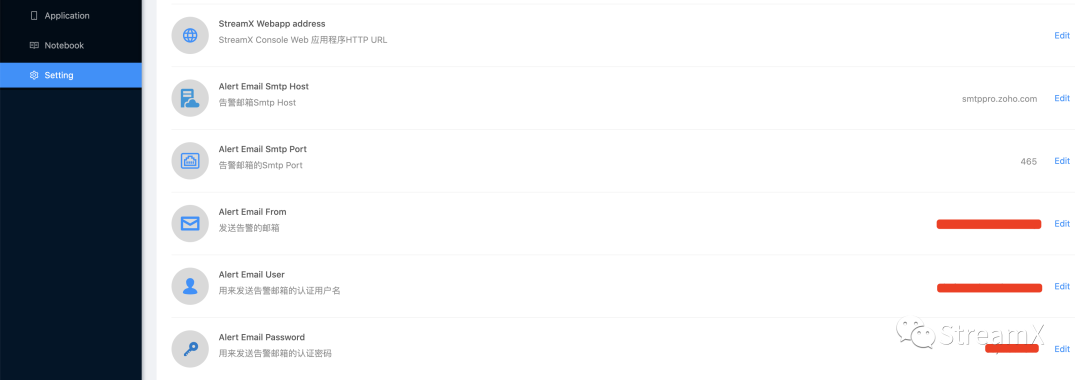
Then, within the tasks, configure the restart strategy: monitor how many times an exception occurs within a certain time, and then decide whether the strategy is to alert or restart, as well as which email address should receive the alert notifications. The version currently used by our company is 1.2.1, which supports only email sending.

When our jobs fail, we can receive alerts through email. These alerts are quite clear, showing which job is in what state. You can also click on the specific address below to view details.
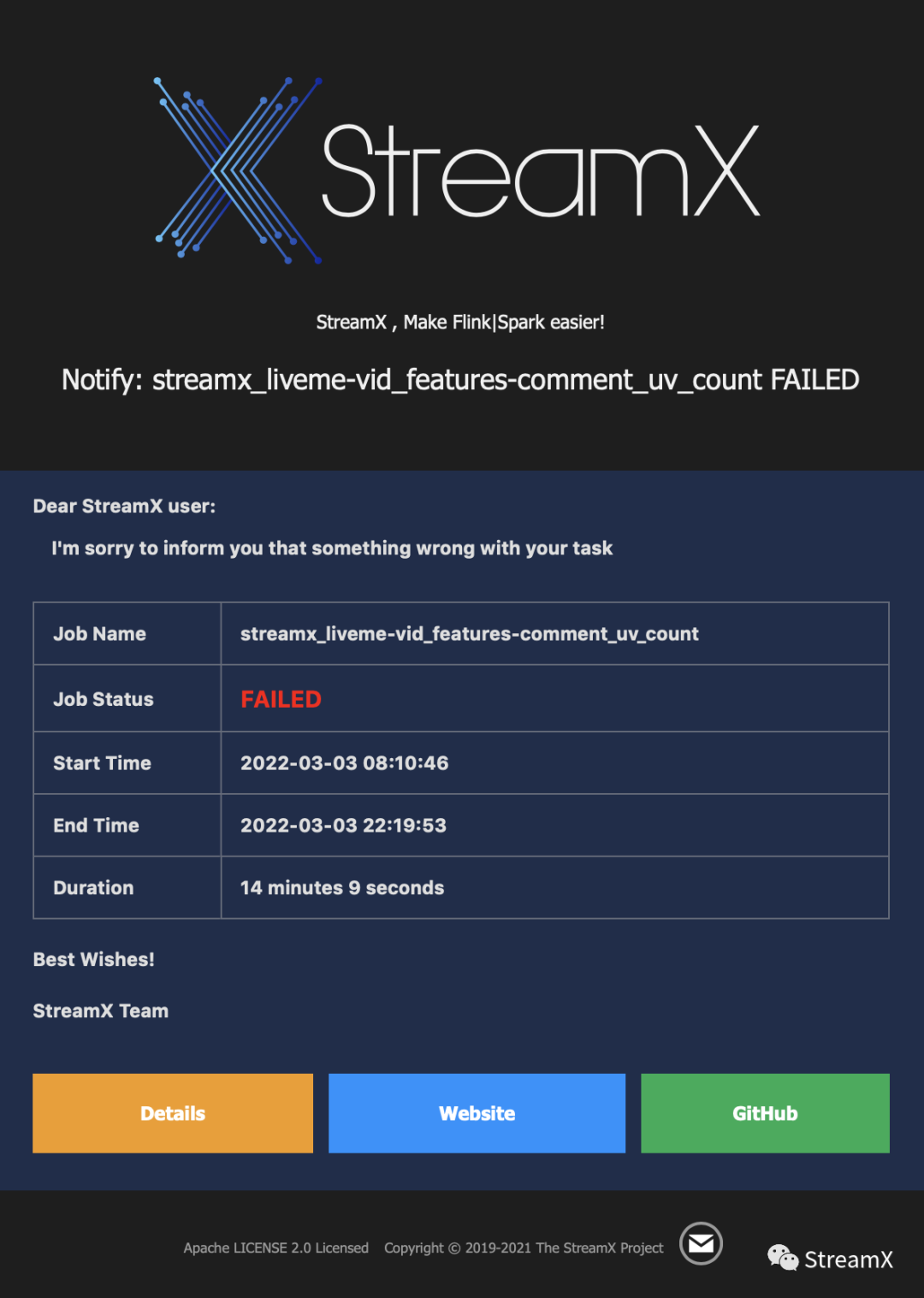
Regarding alerts, we have developed a scheduled task based on StreamPark's t_flink_app table. Why do this? Because most people might not check their emails promptly when it comes to email notifications. Therefore, we opted to monitor the status of each task and send corresponding monitoring information to our Lark (Feishu) alert group, enabling us to promptly identify and address issues with the tasks. It's a simple Python script, then configured with crontab to execute at scheduled times.
5 Common Issues
When it comes to the abnormal issues of jobs, we have summarized them into the following categories:
1. Job Launch Failure
The issue of job launch failure refers to the situation where the job does not start upon initiation. In this case, one needs to check the detailed information logs on the interface. There is an eye-shaped button in our task list; by clicking on it, one can find the submitted job log information in the start logs. If there is clear prompt information, the issue can be directly addressed. If not, one has to check the streamx.out file under the logs/ directory of the backend deployment task to find the log information regarding the launch failure.

2. Job Running Failure
If the task has started but fails during the running phase, this situation might seem similar to the first, but is actually entirely different. This means that the task has been submitted to the cluster, but the task itself has problems running. One can still apply the troubleshooting method from the first scenario to open the specific logs of the job, find the task information on yarn, and then go to yarn's logs with the yarn's tackurl recorded in the logs to look for the specific reasons. Whether it is the absence of the Sql's Connector or a null pointer in a line of code, one can find the detailed stack information. With specific information, one can find the right remedy.

6 Community Impression
Often when we discuss issues in the StreamPark user group, we get immediate responses from community members. Issues that cannot be resolved at the moment are generally fixed in the next version or the latest code branch. In the group, we also see many non-community members actively helping each other out. There are many big names from other communities as well, and many members actively join the community development work. The whole community feels very active to me!
7 Conclusion
Currently, our company runs 60 real-time jobs online, with Flink SQL and custom code each making up about half. More real-time tasks will be put online subsequently. Many colleagues worry about the stability of StreamPark, but based on several months of production practice in our company, StreamPark is just a platform to help you develop, deploy, monitor, and manage jobs. Whether it is stable or not depends on the stability of our own Hadoop Yarn cluster (we use the onyan mode) and has little to do with StreamPark itself. It also depends on the robustness of the Flink SQL or code you write. These two aspects should be the primary concerns. Only when these two aspects are problem-free can the flexibility of StreamPark be fully utilized to improve job performance. To discuss the stability of StreamPark in isolation is somewhat extreme.
That is all the content shared by StreamPark at Joyme. Thank you for reading this article. We are very grateful for such an excellent product provided by StreamPark, which is a true act of benefiting others. From version 1.0 to 1.2.1, the bugs encountered are promptly fixed, and every issue is taken seriously. We are still using the on yarn deployment mode. Restarting yarn will still cause jobs to be lost, but restarting yarn is not something we do every day. The community will also look to fix this problem as soon as possible. I believe that StreamPark will get better and better, with a promising future ahead.