Wuxin Technology was founded in January 2018. The current main business includes the research and development, design, manufacturing and sales of RELX brand products. With core technologies and capabilities covering the entire industry chain, RELX is committed to providing users with products that are both high quality and safe.
12 posts tagged with "Production Practice"
View All Tags9
February, 2026
9
February, 2026

Introduction:This article mainly introduces the architecture upgrade and evolution of the self-migrating MySQL data to Hive, the original architecture involves many components, complex links, and encounters many challenges, and effectively solves the dilemmas and challenges encountered in data integration after using the combination of StreamPark + Paimon, and shares the specific practical solutions of StreamPark + Paimon in practical applications, as well as the advantages and benefits brought by this rookie combination solution.
StreamPark: https://github.com/apache/streampark
Paimon: https://github.com/apache/paimon
Welcome to follow, star, fork, and participate in contributions
Contributor|Beijing Ziru Information Technology Co., Ltd.
Authors of the article|Liu Tao, Liang Yansheng, Wei Linzi
Article compilation|Yang Linwei
Content proofreading|Pan Yuepeng
9
February, 2026

Introduction: This paper mainly introduces the challenges of job development and management faced by Tianyancha in the operation and maintenance of nearly 1,000 Flink jobs in the real-time computing business, and solves these challenges by introducing Apache StreamPark. It introduces some of the problems encountered in the process of introducing StreamPark, and how to solve these problems and successfully land the project, and finally greatly reduces operation and maintenance costs and significantly improve human efficiency.
Github: https://github.com/apache/streampark
Welcome to follow, star, fork, and participate in contributions
Contributor | Beijing Tianyancha
Author | Li Zhilin
Article compilation|Yang Linwei
Content proofreading|Pan Yuepeng
9
February, 2026

Introduction: This article mainly introduces Joymaker's application of big data technology architecture in practice, and explains why Joymaker chose "Kubernetes + StreamPark" to continuously optimise and enhance the existing architecture. It not only systematically describes how to deploy and apply these key technologies in the actual environment, but also explains the practical use of StreamPark in depth, emphasising the perfect integration of theory and practice. I believe that by reading this article, readers will help to understand and master the relevant technologies, and will be able to make progress in practice, which will lead to significant learning results.
Github: https://github.com/apache/streampark
Welcome to follow, Star, Fork and participate in contributing!
Contributed by | Joymaker
Author | Du Yao
Article Organiser | Yang Linwei
Proofreader | Pan Yuepeng
9
February, 2026
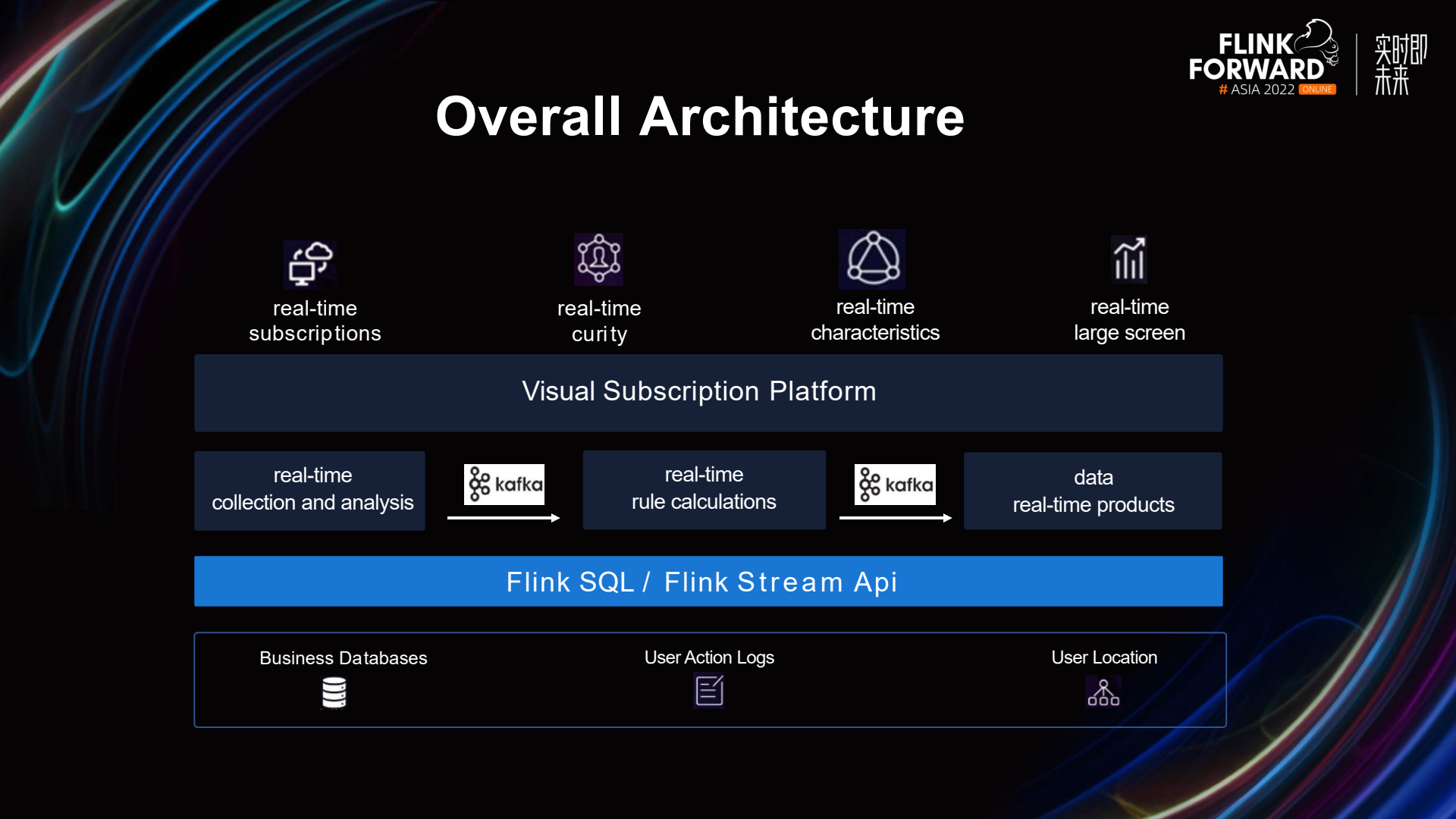
Abstract: This article is compiled from the sharing of Mu Chunjin, the head of China Union Data Science's real-time computing team and Apache StreamPark Committer, at the Flink Forward Asia 2022 platform construction session. The content of this article is mainly divided into four parts:
- Introduction to the Real-Time Computing Platform Background
- Operational Challenges of Flink Real-Time Jobs
- Integrated Management Based on StreamPark
- Future Planning and Evolution
9
February, 2026

**Foreword: **This article mainly introduces the implementation of a streaming data warehouse by Bondex, a supply chain logistics service provider, in the process of digital transformation using the Paimon + StreamPark platform. We provide an easy-to-follow operational manual with the Apache StreamPark integrated stream-batch platform to help users submit Flink tasks and quickly master the use of Paimon.
- Introduction to Company Business
- Pain Points and Selection in Big Data Technology
- Production Practice
- Troubleshooting Analysis
- Future Planning