
Introduction: This article mainly introduces Joymaker's application of big data technology architecture in practice, and explains why Joymaker chose "Kubernetes + StreamPark" to continuously optimise and enhance the existing architecture. It not only systematically describes how to deploy and apply these key technologies in the actual environment, but also explains the practical use of StreamPark in depth, emphasising the perfect integration of theory and practice. I believe that by reading this article, readers will help to understand and master the relevant technologies, and will be able to make progress in practice, which will lead to significant learning results.
Github: https://github.com/apache/streampark
Welcome to follow, Star, Fork and participate in contributing!
Contributed by | Joymaker
Author | Du Yao
Article Organiser | Yang Linwei
Proofreader | Pan Yuepeng
Joymaker, is a global game development and publishing company; the company's products focus on two categories: MMORPG and MMOACT; Joy's product philosophy: "It is better to make a product that 100 people scream than a product that 10,000 people applaud"; Joy's products are always of high quality. RO Legend of Wonderland: Love is Like the First Time" was launched in Southeast Asia, and reached the milestone of 10 million reservations during the booking period, achieved the first place in the best-seller list of five countries on the first day of the launch, and was released in Japan, Korea, the United States, Hong Kong, Macao, Taiwan, and other places, and has achieved good results.
1. Operational Context and Challenges
The big data base currently used by Joymaker Entertainment is Tencent Cloud's EMR, and the number warehouse architecture is mainly divided into the following categories:
-
Offline Warehouse Architecture: Hadoop + Hive + Dolphinscheduler + Trino
-
Real-time Warehouse Architecture: Kafka + Flink + StreamPark + Doris
-
Streaming Warehouse Architecture (in planning): Paimon + Flink + StreamPark + Doris
Among them, the streaming warehouse architecture is one of our key plans for 2024, with the goal of improving big data analytics and the value output of various data products based on the elasticity feature of Kubernetes. However, due to earlier architectural reasons (mainly the mixed deployment of Apache Doris and EMR core nodes), it made us encounter many problems, such as:
-
Resource contention: Under the YARN resource scheduling platform, Apache Doris, Apache Flink real-time tasks, Hive's offline tasks, and Spark's SQL tasks often contend for CPU and memory resources, resulting in Doris query stability degradation and frequent query errors.
-
Insufficient resources: YARN's machine resource usage rate is between 70% and 80% most of the time, especially in the scenario of a large number of complements, the cluster resources are often insufficient.
-
Manual Intervention: Real-time Flink has more and more tasks, the data of each game has obvious peaks and valleys changes in a day, especially the hangout activities carried out on weekends, the data volume doubles, and even increases to more than 10 billion entries per day, and this requires frequent manual adjustment of parallelism to adapt to the computational pressure in order to ensure the data consumption capacity.
2. Solution Selection
In order to solve the above problems, we are looking for components that can perform "resource elasticity scaling" and "task management", and considering the trend of big data cloud-native, it is imminent to adopt cloud-native architecture, which can reduce the burden of big data operation and maintenance and provide better and more stable capabilities such as high availability, load balancing, grey update, etc. under Kubernetes architecture. The Kubernetes architecture reduces the burden on big data operations and provides better and more stable capabilities such as high availability, load balancing, and grey scale updates.
At the same time, simplifying the development and operation and maintenance of Apache Flink real-time tasks is also a problem that has to be faced. Since mid-2022, we have focused on researching Flink-related open-source and commercialisation-related projects, and in the process of technology selection, the company has conducted in-depth investigations mainly from several key dimensions, including:Kubernetes containerised deployment, lightweightness, multi-version support for Flink, and functionality. Flink version support, completeness of features, multiple deployment modes, support for CI/CD, stability, maturity, etc. And finally chose Apache StreamPark.

In the process of using StreamPark, we have carried out in-depth application and exploration of it, and have successfully achieved 100+ Flink tasks easily deployed to Kubernetes, which can be very convenient for job management.
Next, will detail how we use StreamPark to achieve Flink on kubernetes in the production environment of the practice process, although the content is longer, but full of dry goods, the content is mainly divided into the following parts:
-
Environmental Preparation: This part introduces the installation and configuration process of Kubernetes, StreamPark, Maven, Docker, kubectl tools and Flink.
-
StreamPark Use Chapter: This part introduces how to use StreamPark to start session clusters, as well as the process of deploying SQL and JAR jobs.
-
Flink Tasks Application Scenarios: In this section, we will share the practical scenarios of Joyful Hub's actual use of Flink tasks.
3. Practical - Environment Preparation
Next we will start from the installation of a detailed introduction to the StreamPark landing practice, on the Tencent cloud products, some of the steps, will be briefly introduced at the end of the article, here mainly share the core steps.
3.1. Preparing the Kubernetes Environment
Joymaker's Kubernetes environment uses the Tencent Cloud container service product, in which the Kubernetes namespace is mainly divided as follows:
-
Apache Doris: Doris cluster + 3 FE (standard nodes) + CN (1 supernode).
-
Apache Flink: The Flink cluster consists of a supernode, which is the equivalent of an oversized resource machine that is very easy to use and can quickly and elastically scale to tens of thousands of pods.
-
BigData: contains various Big Data components.
In addition, we have two native nodes that are mainly used to deploy StreamPark, Dolphinscheduler, and Prometheus + Grafana. screenshots related to the cluster information are shown below:

3.2. Mounting StreamPark
We are using the latest stable version of StreamPark 2.1.4, which fixes some bugs and adds some new features, such as support for Flink 1.18, Jar task support via pom or uploading dependencies and so on.
Although StreamPark supports Docker and Kubernetes deployment, for the sake of saving time and the need to containerise all big data components in a top-level design, we currently chose to quickly build StreamPark on a CVM in the cloud, and the following is the installation and deployment script for StreamPark:
#Use root user to enter the installation directory (java environment is required first) and k8s environment on the same network segment!!!! You can save yourself the trouble.
cd /data
#Download the binary installer.
wget https://dlcdn.apache.org/incubator/streampark/2.1.4/apache-streampark_2.12-2.1.4-incubating-bin.tar.gz
#Compare it with the values provided to ensure the package is complete.
sha512sum apache-streampark_2.12-2.1.2-incubating-bin.tar.gz #unzip it
tar -xzvf apache-streampark_2.12-2.1.2-incubating-bin.tar.gz #rename it
mv apache-streampark_2.12-2.1.2-incubating-bin streampark_2.12-2.1.2 #create softlinks
ln -s streampark_2.12-2.1.2 streampark
# Modify the database configuration
vim /data/streampark/conf/application-mysql.ymlspring:
datasource:
username: root
password: xxxxx
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://10.16.x.x:3306/streampark_k8s?...
# Modify streampark kernel configuration You can modify the port (because k8s nodeport port range 30000-32767) so you can configure this range to save the port for external development and then configure or account password We use cos for storage so we do not configure hdfs.
vim /data/streampark/conf/application.yml workspace:
local: /data/streampark/streampark_workspace #create the required directory
mkdir -p vim /data/streampark/conf/application.yml
#Initialise the database tables for streampark. Requires a mysql client in the environment. After execution, you can go to mysql and see if the tables exist.
mysql -u root -p xxxxx < /data/streampark/script/schema/mysql-schema.sql
#Add the dependent mysql-connector package because it's not under the streampark lib. Under /data/streampark/lib run.
wget https://repo1.maven.org/maven2/com/mysql/mysql-connector-j/8.0.33/mysql-connector-j-8.0.33.jar
#Start and log in. You can verify the java environment first. java -version to make sure it's ok. Execute under /data/streampark/lib.
./startup.sh
3.3. Mounting Maven
To configure Flink tasks on StreamPark, you can download the dependencies via maven, here is the Maven installation configuration:
#Download maven as root user.
cd /data && wget https://dlcdn.apache.org/maven/maven-3/3.9.6/binaries/apache-maven-3.9.6-bin.tar.gz
#Verify that the installation package is complete.
sha512sum apache-maven-3.9.6-bin.tar.gz
#Unzip Softlink.
tar -xzvf apache-maven-3.9.6-bin.tar.gz
ln -s apache-maven-3.9.6 maven
#Set up a maven mirror to speed up downloads from the AliCloud repository.
vim /data/maven/conf/settings.xml
<mirror>
<id>alimaven</id>
<mirrorOf>central</mirrorOf>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/repository/central</url>
</mirror>
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
#Environment Variables Finally add.
vim /etc/profile
export MAVEN_HOME=/data/maven
PATH=$MAVEN_HOME/bin:$PATH
#Validate.
source /etc/profile && mvn -version
3.4 Mounting Docker
Because StreamPark uses Kubernetes, you can use Docker to build and upload images to your company's popular Harbor image service, here's the Docker install script
#Uninstall the old version If available
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
#Download the repository
wget -O /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo #AliCloud docker-ce image repository
#Update the package index
yum makecache
#Download and install
yum install docker-ce docker-ce-cli containerd.io -y # docker-ce community edition ee enterprise edition
#Start View
systemctl start docker && docker version
#Boot
systemctl enable docker
3.5. Kubectl Tool Installation
In order to interact with the Kubernetes cluster, view configurations, access logs, etc., we also installed the kubectl tool. Before installing kubectl, you first need to get the access credentials for the Kubernetes cluster from here, as shown in the following figure:

Next, download a copy of the configuration to the root user directory, specify the directory and rename it:
# 1)Create the default hidden directory.
mkdir -p /root/.kube
# 2)Upload k8s intranet access credentials.
rz cls-dtyxxxxl-config
# 3)Modify the default name of the credentials.
mv cls-dtyxxxxl-config config
# 4)Place the credentials in the specified location.
mv config /root/.kube
You can install the kubetcl client as follows (you can also install kubectx to make it easier to access multiple kubernetes clusters and switch between fixed namespaces):
# 1)Download the latest version.
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
# 2)Add execute permissions.
chmod +x kubectl
# 3)Move to a common tool command location.
mv ./kubectl /usr/local/bin/kubectl
# 4)This can be configured in /etc/profile or in .bashrc in the root user's home directory.
vim /root/.bashrc
export JAVA_HOME=/usr/local/jdk1.8.0_391
PATH=/usr/local/bin:$JAVA_HOME/bin:$PATH
# 5)Verify the client and cluster keys.
kubectl cluster-info
Finally, you also need to create a Flink-specific account credentials (which will be used later):
# 1)Create namespace.
kubectl create namespace flink
# 2)Create account for flink to access k8s Remember to bring the namespace!
kubectl create serviceaccount flink-service-account -n flink
# 3)Bind some permissions for container operations to this account Remember with namespaces!!!
kubectl create clusterrolebinding flink-role-binding-flink --clusterrole=edit --serviceaccount=flink:flink-service-account -n flink
3.6. Installation Configuration Flink
We chose the Flink1.17-scala2.12 Java11 image for our Kubernetes environment because some of the dependencies of Flink 1.18 were not easy to find.
Download and extract the flink-1.17.2-bin-scala_2.12.tgz installer with the following script:
cd /data && wget https://dlcdn.apache.org/flink/flink-1.17.2/flink-1.17.2-bin-scala_2.12.tgz
#Integrity checksum.
sha512sum flink-1.17.2-bin-scala_2.12.tgz
#Unzip
tar -xzvf flink-1.17.2-bin-scala_2.12.tgz
#Rename
mv flink-1.17.2-bin-scala_2.12 flink-1.17.2
#Soft connect.
ln -s flink-1.17.2 flink
#Store old binary packages.
mv flink-1.17.2-bin-scala_2.12.tgz /data/softbag
At this point, we have set up the environment, the following continue to step by step detailed explanation of the use of StreamPark.
4. Practical - StreamPark in Action
Readers who want to get a quick overview of StreamPark running jobs to Kubernetes can watch the video below:
// Video link (Flink On Kubernetes Application Hands-On Tutorial)
// Video link (Flink On Kubernetes Session Hands-On Tutorial)
4.1. Configure Flink Home
After logging in to StreamPark, switch to the Flink Home menu and configure the directory where we extracted the Flink installation package earlier, as shown in the screenshot below:

4.2. Establish Flink Session
Then switch to FlinkCluster and Add New to add a new Flink cluster:

Configuration details are as follows, here is the first part of the configuration:
Configuration details: cluster name and Kubernetes cluster ID We usually write the same, fill in the correct Kubernetes service account, here the image is used in tencent cloud tcr, and use lb as the external access to the Flink UI. (The slots here are usually set to 2, and the task parallelism is usually a multiple of 2, so that the session cluster has no idle resources).

The second part of the configuration content:
Configuration details: We take the Session mode, a JobManager manages a lot of tasks, so the resources can be slightly larger, we give 2G, after observing can be satisfied, but due to the task is more, the memory allocation of JobManager metaspace consumption is relatively large, so you can be the default of 256M, change to 500M, after After observation, a session manages less than 10 tasks, this configuration is reasonable.
After TaskManager memory session configuration is given, it can not be modified in StreamPark programme configuration page, so you can estimate the amount of session project data, if the amount of data is large, you can adjust "CPU : Memory" to "1 core : 2G", of course, you can also adjust "CPU : Memory" to "1 core : 2G", of course, you can also change the default to 256M. 2G", of course, can also be larger, because the data processing and the number of TaskManager related, that is, the degree of parallelism, so you can basically avoid some OOM problems, we "1 : 2" session cluster project a day to deal with the data volume of six billion, 18 Parallelism is for reference only. The default cpu: memory 1 : 1 is basically ok.

The last part reads as follows::

The exact textual content is posted here:
#Access method reuse lb+port lb can be created in advance without k8s creation so that the ip is fixed. It is more convenient to reuse.
-Drest.port=8091
-Dkubernetes.rest-service.annotations=service.kubernetes.io/qcloud-share-existed-lb:true,service.kubernetes.io/tke-existed-lbid:lb-iv9ixxxxx
-Dkubernetes.rest-service.exposed.type=LoadBalancer
#cp sp access tencent cloud cos using s3 protocol plugin way.
-Dcontainerized.master.env.ENABLE_BUILT_IN_PLUGINS=flink-s3-fs-hadoop-1.17.2.jar
-Dcontainerized.taskmanager.env.EANABLE_BUILT_IN_PLUGINS=flink-s3-fs-hadoop-1.17.2.jar
-Dstate.checkpoints.dir=s3://k8s-bigdata-xxxxxx/flink-checkpoints
-Dstate.savepoints.dir=s3://k8s-bigdata-xxxxx/flink-savepoints
#The task scheduling policy in #k8s, the node selection policy, because the flink namespace is logical, and the node selection policy can be made to run on a flink-specific physical supernode.
-Dkubernetes.jobmanager.node-selector=usefor:flink
-Dkubernetes.taskmanager.node-selector=usefor:flink
#Enable high availability for jobmanager Use k8s implementation, use cos directory storage, no hdfs overall.
-Dhigh-availability.type=kubernetes
-Dhigh-availability.storageDir=s3://k8s-bigdata-xxx/flink-recovery
-Dkubernetes.cluster-id=streampark-share-session
-Dkubernetes.jobmanager.replicas=2
#pod image pull policy and flink cancel cp reservation Time zone
-Dkubernetes.container.image.pull-policy=Always
-Dexecution.checkpointing.externalized-checkpoint-retention=RETAIN_ON_CANCELLATION
-Dtable.local-time-zone=Asia/Shanghai
#Mirror pull cache acceleration as explained below.
-Dkubernetes.taskmanager.annotations=eks.tke.cloud.tencent.com/use-image-cache: imc-6iubofdt
-Dkubernetes.jobmanager.annotations=eks.tke.cloud.tencent.com/use-image-cache: imc-6iubofdt
Note: Flink basic information can be configured in the conf file, and more general information is recommended to be written in the session, StreamPark is more appropriate to fill in the parallelism/cp/sp/fault-tolerance/main parameter, and so on.
Finally, you can start the session cluster. You can use the kubectl command to check whether the Flink kubernetes session cluster has started successfully:

4.3. Task Configuration
Here we will continue to demonstrate the use of StreamPark to submit three types of tasks, namely SQL tasks, Jar tasks, and Application mode tasks.
- Submitting a Flink SQL job
A screenshot of the configuration of a Flink Sql job is shown below:

The kubernetes clusterid should just be the session name of the corresponding project:

The dynamic parameters are configured as follows:
-Dstate.checkpoints.dir=s3://k8s-bigdata-12xxxxx/flink-checkpoints/ro-cn-sync
-Dstate.savepoints.dir=s3://k8s-bigdata-12xxxxxxx/flink-savepoints/ro-cn-sync
-Dkubernetes.container.image.pull-policy=Always
-Dkubernetes.service-account=flink-service-account
-Dexecution.checkpointing.interval=25s
-Dexecution.checkpointing.mode=EXACTLY_ONCE
-Dtable.local-time-zone=Asia/Shanghai
-Drestart-strategy.fixed-delay.attempts=10
-Drestart-strategy.fixed-delay.delay=3min
- Submit Flink JAR Tasks
The Jar task is basically the same as the Sql task, the configuration screenshot is below:

Dynamic parameters are as follows (if there is a configuration template, here can be more streamlined, because StreamPark supports very good task replication, so you can write a standard Jar and SQL task demo, the rest of the tasks are replicated, which can greatly improve the efficiency of task development):
-Dstate.checkpoints.dir=s3://k8s-bigdata-1xxxx/flink-checkpoints/ro-cn-shushu
-Dstate.savepoints.dir=s3://k8s-bigdata-1xxxx/flink-savepoints/ro-cn-shushu
-Dkubernetes.container.image.pull-policy=Always
-Dkubernetes.service-account=flink-service-account
-Dexecution.checkpointing.interval=60s
-Dexecution.checkpointing.mode=EXACTLY_ONCE
-Dstate.checkpoints.num-retained=2
-Drestart-strategy.type=failure-rate
-Drestart-strategy.failure-rate.delay=3min
-Drestart-strategy.failure-rate.failure-rate-interval=30min
-Drestart-strategy.failure-rate.max-failures-per-interval=8
- Submitting a Flink Application task
Of course, you can also deploy Application mode tasks to Kubernetes, so here's an example, starting with the first part of the configuration:

This is the second part of the configuration as follows:

The third part of the configuration is as follows:
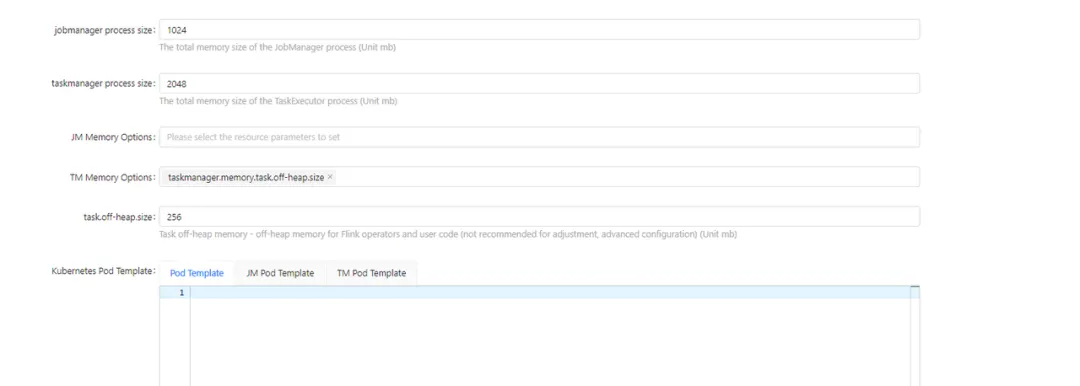
Dynamic parameters:

Detailed configuration content::
-Dcontainerized.master.env.ENABLE_BUILT_IN_PLUGINS=flink-s3-fs-hadoop-1.17.2.jar
-Dcontainerized.taskmanager.env.ENABLE_BUILT_IN_PLUGINS=flink-s3-fs-hadoop-1.17.2.jar
-Dstate.checkpoints.dir=s3://k8s-bigdata-xxx/flink-checkpoints/Kafka2Rocketmq2Kafka
-Dstate.savepoints.dir=s3://k8s-bigdata-xxx/flink-savepoints/Kafka2Rocketmq2Kafka
-Dkubernetes.container.image.pull-policy=Always
-Dkubernetes.service-account=flink-service-account
-Dexecution.checkpointing.interval=60s
-Dexecution.checkpointing.mode=EXACTLY_ONCE
-Dstate.checkpoints.num-retained=2
-Drest.port=8092
-Dkubernetes.jobmanager.node-selector=usefor:flink
-Dkubernetes.taskmanager.node-selector=usefor:flink
-Dkubernetes.rest-service.annotations=service.kubernetes.io/qcloud-share-existed-lb:true,service.kubernetes.io/tke-existed-lbid:lb-xxx
-Dkubernetes.rest-service.exposed.type=LoadBalancer
-Dfs.allowed-fallback-filesystems=s3
4.4. Build Tasks
The task is then constructed, and each step of the task construction can be clearly seen here:

Eventually you can run it and observe that the task is running:

4.5. Notification Alarm Configuration (optional)
Of course, StreamPark supports multiple notification alert methods (e.g. mailboxes and flybooks, etc.), and we use the mailbox method, which can be configured directly from the interface:

So far, we have shared how to successfully go about deploying different types of Flink tasks running in kubernetes in StremPark, very silky smooth!
5. Practical - Homework Application Scenarios
Next, we will continue to dissect the job, from the tuning, hands-on and other scenarios to give us a better understanding of the application of Flink tasks.
5.1. Tuning Recommendations
Recommendation 1 (time zone): containers need to be in utc+8 to easily see the logs, we can add the following in the conf configuration:
env.java.opts.jobmanager: -Duser.timezone=GMT+08
env.java.opts.taskmanager: -Duser.timezone=GMT+08
Recommendation 2 (StreamPark Variable Management): StreamPark provides variable management, which allows us to manage some configurations to improve security and convenience:

Proposal 3 (StreamPark Passing Parameters): On YARN, we used Flink's own toolkit to pass parameters, and it was difficult to pass parameters to the Flink environment, so we didn't look into it. We chose to pass in the program parameters through StreamPark, so that it can be used in both YARN and kubernetes, while the application and session methods in kubernetes can also be used, it becomes more general and easy to change, highly recommended!
Recommendation 4 (Use Session pattern): Although the Yarn-application pattern provides a high degree of task isolation, each of its tasks requires a separate jobmanager resource, which leads to excessive resource consumption. In addition, merging tasks, while reducing resource consumption, can lead to problems such as high workload and unstable data. In contrast, the session pattern allows tasks to share a single jobmanager resource in a session, which can maximise the saving of computing resources, and although it may have a single-point problem, it can be solved by using two jobmanager instances to achieve high availability. More importantly, the session mode also makes it easier to view logs generated due to job failures, which helps improve the efficiency of troubleshooting. Therefore, given its advantages in terms of resource utilisation, high availability and task failure handling, choosing session mode becomes a more desirable option.
5.2. Data CDC synchronisation
[MySQL → Doris]: The following code essentially demonstrates the Flink sql pipeline for MySQL data synchronisation to Apache Doris:
CREATE TABLE IF NOT EXISTS `login_log_mysql` (
login_log_id bigint not null,
account_id bigint ,
long_account_id string ,
short_account_id string ,
game_code string ,
package_code string ,
channel_id int ,
login_at int ,
login_ip string ,
device_ua string ,
device_id string ,
device_net string ,
device_ratio string ,
device_os string ,
device_carrier string ,
ext string ,
created_at int ,
updated_at int ,
deleted_at int ,
PRIMARY KEY(`login_log_id`)
NOT ENFORCED
) with (
'connector' = 'mysql-cdc',
'hostname' = '10.xxx.xxx.xxx',
'port' = '3306',
'username' = 'http_readxxxxx',
'password' = 'xxxx@)',
'database-name' = 'player_user_center',
-- 'scan.startup.mode' = 'latest-offset',
'scan.startup.mode' = 'earliest-offset',
'table-name' = 'login_log_202[3-9][0-9]{2}',
'server-time-zone' = '+07:00'
);
create table if not EXISTS login_log_doris(
`date` date ,
login_log_id bigint ,
account_id bigint ,
long_account_id string ,
short_account_id string ,
game_code string ,
`package_code` string ,
`channel_id` int ,
login_at string ,
login_ip string ,
device_ua string ,
device_id string ,
device_net string ,
device_ratio string ,
device_os string ,
device_carrier string ,
ext string ,
created_at string ,
updated_at string ,
deleted_at string ,
PRIMARY KEY(`date`,`login_log_id`)
NOT ENFORCED
) WITH (
'connector' = 'doris',
'jdbc-url'='jdbc:mysql://xxx.xx.xx.xx:9030,xxx.xxx.xxx.xxx:9030,xxx.xxx.xxx.xxx:9030',
'load-url'='xxx.xx.xx.xx:8030;xxx.xx.xx.xx:8030;xxx.xx.xx.xx:8030',
'database-name' = 'ro_sea_player_user_center',
'table-name' = 'ods_login_log',
'username' = 'root',
'password' = 'root123',
'sink.semantic' = 'exactly-once',
'sink.max-retries' = '10'
);
create view login_log_flink_trans as
select
to_date(cast(to_timestamp_ltz(login_at,0) as varchar) ) ,
login_log_id ,
account_id ,
long_account_id ,
short_account_id ,
game_code ,
package_code ,
channel_id,
cast(to_timestamp_ltz(login_at,0) as varchar) as login_at,
login_ip ,
device_ua ,
device_id ,
device_net ,
device_ratio ,
device_os ,
device_carrier ,
ext ,
cast(to_timestamp_ltz(created_at,0) as varchar) as created_at,
cast(to_timestamp_ltz(updated_at,0) as varchar) as updated_at,
cast(to_timestamp_ltz(deleted_at,0) as varchar) as deleted_at
from login_log_mysql;
insert into login_log_doris select * from login_log_flink_trans;
CREATE TABLE IF NOT EXISTS `account_mysql` (
account_id bigint ,
open_id string ,
dy_openid string ,
dy_ios_openid string ,
ext string ,
last_channel int ,
last_login_time int ,
last_login_ip string ,
created_at int ,
updated_at int ,
deleted_at string ,
PRIMARY KEY(`account_id`)
NOT ENFORCED
) with (
'connector' = 'mysql-cdc',
'hostname' = 'xxx.xx.xx.xx',
'port' = '3306',
'username' = 'http_readxxxx',
'password' = 'xxxxx@)',
'database-name' = 'player_user_center',
-- 'scan.startup.mode' = 'latest-offset',
'scan.startup.mode' = 'earliest-offset',
'table-name' = 'account_[0-9]+',
'server-time-zone' = '+07:00'
);
create table if not EXISTS account_doris(
`date` date ,
account_id bigint ,
open_id string ,
dy_openid string ,
dy_ios_openid string ,
ext string ,
`last_channel` int ,
last_login_time string ,
last_login_ip string ,
created_at string ,
updated_at string ,
deleted_at string ,
PRIMARY KEY(`date`,`account_id`)
NOT ENFORCED
) WITH (
'connector' = 'doris',
'jdbc-url'='jdbc:mysql://xxx.xx.xx.xx:9030,xxx.xx.xx.xx:9030,xxx.xx.xx.xx:9030',
'load-url'='xxx.xx.xx.xx:8030;xxx.xx.xx.xx:8030;xxx.xx.xx.xx:8030',
'database-name' = 'ro_sea_player_user_center',
'table-name' = 'ods_account_log',
'username' = 'root',
'password' = 'root123',
'sink.semantic' = 'exactly-once',
'sink.max-retries' = '10'
);
create view account_flink_trans as
select
to_date(cast(to_timestamp_ltz(created_at,0) as varchar) ) ,
account_id ,
open_id ,
dy_openid ,
dy_ios_openid ,
ext ,
last_channel ,
cast(to_timestamp_ltz(last_login_time,0) as varchar) as last_login_time,
last_login_ip ,
cast(to_timestamp_ltz(created_at,0) as varchar) as created_at,
cast(to_timestamp_ltz(updated_at,0) as varchar) as updated_at,
deleted_at
from account_mysql;
insert into account_doris select * from account_flink_trans;
[Game Data Synchronisation]: pull kafka data collected by overseas filebeat to domestic kafka and process metadata processing:
--Create a kafka source table for hmt.
CREATE TABLE kafka_in (
`env` STRING comment 'Game environment hdf /qc/cbt/obt/prod',
`host` STRING comment 'Game server where logs are located',
`tags` STRING comment 'Log Tags normal | fix',
`log` STRING comment 'File and offset of the log',
`topic` STRING METADATA VIRTUAL comment 'kafka topic',
`partition_id` BIGINT METADATA FROM 'partition' VIRTUAL comment 'The kafka partition where the logs are located',
`offset` BIGINT METADATA VIRTUAL comment 'The offset of the kafka partition',
`uuid` STRING comment 'uuid generated by filebeat',
`message` STRING comment 'tlog message',
`@timestamp` STRING comment 'filebeat capture time',
`ts` TIMESTAMP(3) METADATA FROM 'timestamp' comment 'kafka storage message time'
) WITH (
'connector' = 'kafka',
'topic' = 'ro_sea_tlog',
'properties.bootstrap.servers' = 'sea-kafka-01:9092,sea-kafka-02:9092,sea-kafka-03:9092',
'properties.group.id' = 'streamx-ro-sea-total',
'properties.client.id' = 'streamx-ro-sea-total',
'properties.session.timeout.ms' = '60000',
'properties.request.timeout.ms' = '60000',
'scan.startup.mode' = 'group-offsets',
--'scan.startup.mode' = 'earliest-offset',\
'properties.fetch.max.bytes' = '123886080',
'properties.max.partition.fetch.bytes' = '50388608',
'properties.fetch.max.wait.ms' = '2000',
'properties.max.poll.records' = '1000',
'format' = 'json',
'json.ignore-parse-errors' = 'false'
);
--Creating the kafka official table for emr
CREATE TABLE kafka_out_sea (
`env` STRING comment 'Game environment qc/cbt/obt/prod',
`hostname` STRING comment 'Game server where logs are located',
`tags` STRING comment 'Log Tags normal | fix',
`log_offset` STRING comment 'File and offset of the log',
`uuid` STRING comment 'uuid generated by filebeat',
`topic` STRING comment 'kafka topic',
`partition_id` BIGINT comment 'The kafka partition where the logs are located',
`kafka_offset` BIGINT comment 'The offset of the kafka partition',
eventname string comment 'event name',
`message` STRING comment 'tlog message',
`filebeat_ts` STRING comment 'filebeat collection time',
`kafka_ts` TIMESTAMP(3) comment 'kafka stored message time',
`flink_ts` TIMESTAMP(3) comment 'flink processed message time'
) WITH (
'connector' = 'kafka',
'topic' = 'ro_sea_tlog',
--'properties.client.id' = 'flinkx-ro-sea-prod-v2',
'properties.bootstrap.servers' = 'emr_kafka1:9092,emr_kafka2:9092,emr_kafka3:9092',
'format' = 'json',
--'sink.partitioner'= 'fixed',
'sink.delivery-guarantee' = 'exactly-once',
'sink.transactional-id-prefix' = 'ro_sea_kafka_sync_v10',
'properties.compression.type' = 'zstd',
'properties.transaction.timeout.ms' = '600000',
'properties.message.max.bytes' = '13000000',
'properties.max.request.size' = '13048576',
--'properties.buffer.memory' = '83554432',
'properties.acks' = '-1'
);
--etl create target view
create view kafka_sea_in_view as
select `env`,JSON_VALUE(`host`,'$.name') as hostname,`tags`,`log` as log_offset,`uuid`,
`topic`,`partition_id`,`offset` as kafka_offset,
lower(SPLIT_INDEX(message,'|',0)) as eventname,`message`,
CONVERT_TZ(REPLACE(REPLACE(`@timestamp`,'T',' '),'Z',''), 'UTC', 'Asia/Bangkok') as filebeat_ts, `ts` as kafka_ts ,CURRENT_TIMESTAMP as flink_ts
from kafka_in;
--Write data to emr sea topic
insert into kafka_out_sea
select * from kafka_sea_in_view ;
[Real-time counting warehouse]: shunt Jar program and ods -> dwd sql processing function, part of the code screenshot below:

and the associated Flink sql:
--2 dwd_moneyflow_log
CREATE TABLE kafka_in_money (
`env` STRING comment 'Game environment qc/cbt/obt/prod',
`hostname` STRING comment 'Game server where logs are located',
`uuid` STRING comment 'Log unique id',
`message` STRING comment 'tlog message',
`filebeat_ts` STRING comment 'filebeat collection time'
) WITH (
'connector' = 'kafka',
'topic' = 'ro_sea_tlog_split_moneyflow',
'properties.bootstrap.servers' = 'emr_kafka1:9092,emr_kafka2:9092,emr_kafka3:9092',
'properties.group.id' = 'flinksql_kafka_in_moneyflow_v2',
'scan.startup.mode' = 'group-offsets',
--'scan.startup.mode' = 'earliest-offset',
'properties.isolation.level' = 'read_committed',
'format' = 'json',
'json.ignore-parse-errors' = 'false'
);
CREATE TABLE kafka_out_money(
`date` string not NULL COMMENT 'date',
`vroleid` int NULL COMMENT 'role id',
`moneytype` int NULL COMMENT 'Currency type',
`env` string NULL COMMENT 'Game environment hdf /qc/cbt/obt/prod',
`hostname` string NULL COMMENT 'The game server where the logs are located',
`uuid` string NULL COMMENT 'The uuid generated by the filebeat capture',
`filebeat_ts` string NULL COMMENT 'filebeat capture time',
flink_ts string NULL COMMENT 'message time written by flink',
`gamesvrid` int NULL COMMENT 'Logged in game server number',
`dteventtime` string NULL COMMENT 'The time of the game event, format YYYY-MM-DD HH:MM:SS',
`vgameappid` string NULL COMMENT 'Game APPID',
`platid` int NULL COMMENT 'ios 0 /android 1',
`izoneareaid` int NULL COMMENT 'The zone id is used to uniquely identify a zone for split-server games; 0 for non-split-server games',
`vopenid` string NULL COMMENT 'User's OPENID number',
`vrolename` string NULL COMMENT 'Character name',
`jobid` int NULL COMMENT 'Role Occupation 0=Wizard 1=......',
`gender` int NULL COMMENT 'Character Gender 0=Male 1=Female',
`ilevel` int NULL COMMENT 'Character base level',
`ijoblevel` int NULL COMMENT 'Character's career level',
`playerfriendsnum` int NULL COMMENT 'Number of player friends',
`chargegold` int NULL COMMENT 'Character's recharge experience (cumulative recharge),
`iviplevel` int NULL COMMENT 'Character's VIP level',
`createtime` string NULL COMMENT 'Account creation time',
`irolece` int NULL COMMENT 'Battle power/rating',
`unionid` int NULL COMMENT 'Guild ID',
`unionname` string NULL COMMENT 'Guild name',
`regchannel` int NULL COMMENT 'registration channel',
`loginchannel` int NULL COMMENT 'login channel',
`sequence` int NULL COMMENT 'Used to correlate a single action to generate multiple logs of different types of currency movement',
`reason` int NULL COMMENT 'Behavior (currency flow level 1 reason)',
`subreason` int NULL COMMENT 'Flow direction (item flow definition)',
`imoney` int NULL COMMENT 'Number of currency changes',
`aftermoney` int NULL COMMENT 'Number of aftermoney after action',
`afterboundmoney` int NULL COMMENT 'Number of money bound after the action',
`addorreduce` int NULL COMMENT 'Increase or decrease: 0 is increase; 1 is decrease',
`serialnum` string NULL COMMENT 'The running number',
`sourceid` int NULL COMMENT 'Channel number',
`cmd` string NULL COMMENT 'command word',
`orderid` string NULL COMMENT 'Order id (contains meowgoincrease and meowgoincrease, also contains cash recharge order id)',
`imoneytype` int NULL COMMENT 'Currency type 2',
`distincid` string NULL COMMENT 'Visitor ID',
`deviceuid` string NULL COMMENT 'device ID',
`guildjob` int NULL COMMENT 'Guild Position',
`regtime` string NULL COMMENT 'Account registration time'
) WITH (
'connector' = 'doris',
'jdbc-url'='jdbc:mysql://xxx:9030,xxx:9030,xxx:9030',
'load-url'='xx:8030;xxx:8030;xxx:8030',
'database-name' = 'ro_sea',
'table-name' = 'dwd_moneyflow_log',
'username' = 'root',
'password' = 'root123',
'sink.semantic' = 'exactly-once'
);
create view kafka_out_money_view1 as
select IF(to_date(SPLIT_INDEX(message,'|',2)) > CURRENT_DATE + interval '1' day,CURRENT_DATE,to_date(SPLIT_INDEX(message,'|',2))) as `date`,
`env`,`hostname` as hostname,`uuid`,
try_cast(SPLIT_INDEX(message,'|',1) as int) as gamesvrid ,
SPLIT_INDEX(message,'|',2) as dteventtime ,
SPLIT_INDEX(message,'|',3) as vgameappid ,
try_cast(SPLIT_INDEX(message,'|',4) as int) as platid ,
try_cast(SPLIT_INDEX(message,'|',5) as int) as izoneareaid ,
SPLIT_INDEX(message,'|',6) as vopenid ,
try_cast(SPLIT_INDEX(message,'|',7) as int) as vroleid ,
SPLIT_INDEX(message,'|',8) as vrolename ,
try_cast(SPLIT_INDEX(message,'|',9) as int) as jobid ,
try_cast(SPLIT_INDEX(message,'|',10) as int) as gender ,
try_cast(SPLIT_INDEX(message,'|',11) as int) as ilevel ,
try_cast(SPLIT_INDEX(message,'|',12) as int) as ijoblevel ,
try_cast(SPLIT_INDEX(message,'|',13) as int) as playerfriendsnum ,
try_cast(SPLIT_INDEX(message,'|',14) as int) as chargegold ,
try_cast(SPLIT_INDEX(message,'|',15) as int) as iviplevel ,
SPLIT_INDEX(message,'|',16) as createtime ,
try_cast(SPLIT_INDEX(message,'|',17) as int) as irolece ,
try_cast(SPLIT_INDEX(message,'|',18) as int) as unionid ,
SPLIT_INDEX(message,'|',19) as unionname ,
try_cast(SPLIT_INDEX(message,'|',20) as int) as regchannel ,
try_cast(SPLIT_INDEX(message,'|',21) as int) as loginchannel ,
try_cast(SPLIT_INDEX(message,'|',22) as int) as `sequence` ,
try_cast(SPLIT_INDEX(message,'|',23) as int) as `reason` ,
try_cast(SPLIT_INDEX(message,'|',24) as int) as subreason ,
try_cast(SPLIT_INDEX(message,'|',25) as int) as moneytype ,
try_cast(SPLIT_INDEX(message,'|',26) as int) as imoney ,
try_cast(SPLIT_INDEX(message,'|',27) as int) as aftermoney ,
try_cast(SPLIT_INDEX(message,'|',28) as int) as afterboundmoney ,
try_cast(SPLIT_INDEX(message,'|',29) as int) as addorreduce ,
SPLIT_INDEX(message,'|',30) as serialnum ,
try_cast(SPLIT_INDEX(message,'|',31) as int) as sourceid ,
SPLIT_INDEX(message,'|',32) as `cmd` ,
SPLIT_INDEX(message,'|',33) as orderid ,
try_cast(SPLIT_INDEX(message,'|',34) as int) as imoneytype ,
SPLIT_INDEX(message,'|',35) as distincid ,
SPLIT_INDEX(message,'|',36) as deviceuid ,
try_cast(SPLIT_INDEX(message,'|',37) as int) as guildjob ,
SPLIT_INDEX(message,'|',38) as regtime ,
filebeat_ts,CURRENT_TIMESTAMP as flink_ts
from kafka_in_money;
insert into kafka_out_money
select
cast(`date` as varchar) as `date`,
`vroleid`,
`moneytype`,
`env`,
`hostname`,
`uuid`,
`filebeat_ts`,
cast(`flink_ts` as varchar) as flink_ts,
`gamesvrid`,
`dteventtime`,
`vgameappid`,
`platid`,
`izoneareaid`,
`vopenid`,
`vrolename`,
`jobid`,
`gender`,
`ilevel`,
`ijoblevel`,
`playerfriendsnum`,
`chargegold`,
`iviplevel`,
`createtime`,
`irolece`,
`unionid`,
`unionname`,
`regchannel`,
`loginchannel`,
`sequence`,
`reason`,
`subreason`,
`imoney`,
`aftermoney`,
`afterboundmoney`,
`addorreduce`,
`serialnum`,
`sourceid`,
`cmd`,
`orderid`,
`imoneytype`,
`distincid`,
`deviceuid`,
`guildjob`,
`regtime`
from kafka_out_money_view1;
[Advertisement system]: Use Flink SQL to slice and dice a row of log data to parse out the data in each field and complete the business calculations :
CREATE TABLE IF NOT EXISTS ods_adjust_in (
log STRING
) WITH (
'connector' = 'kafka',
'topic' = 'ad_adjust_callback',
'properties.bootstrap.servers' = 'emr_kafka1:9092,emr_kafka2:9092,emr_kafka3:9092',
'properties.group.id' = 'ods_adjust_etl_20231011',
'properties.max.partition.fetch.bytes' = '4048576',
'scan.startup.mode' = 'group-offsets',
'properties.isolation.level' = 'read_committed',
'format' = 'raw'
);
CREATE TABLE IF NOT EXISTS ods_af_in (
log STRING
) WITH (
'connector' = 'kafka',
'topic' = 'ad_af_callback',
'properties.bootstrap.servers' = 'emr_kafka1:9092,emr_kafka2:9092,emr_kafka3:9092',
'properties.max.partition.fetch.bytes' = '4048576',
'properties.group.id' = 'ods_af_etl_20231011',
'scan.startup.mode' = 'group-offsets',
'properties.isolation.level' = 'read_committed',
'format' = 'raw'
);
CREATE TABLE IF NOT EXISTS ods_mmp_out (
`date` DATE,
`mmp_type` STRING,
`app_id` STRING,
`event_name` STRING,
`event_time` TIMESTAMP(3),
`mmp_id` STRING,
`distinct_id` STRING,
`open_id` STRING,
`account_id` STRING,
`os_name` STRING, -- platform
`country_code` STRING,
`install_time` TIMESTAMP(3),
`bundle_id` STRING,
`media` STRING,
`channel` STRING,
`campaign` STRING,
`campaign_id` STRING,
`adgroup` STRING,
`adgroup_id` STRING,
`ad` STRING,
`ad_id` STRING,
`flink_ts` TIMESTAMP(3) comment 'Message time processed by flink',
`device_properties` STRING,
`log` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'ods_mmp_log',
'properties.bootstrap.servers' = 'emr_kafka1:9092,emr_kafka2:9092,emr_kafka3:9092',
'scan.topic-partition-discovery.interval'='60000',
'properties.group.id' = 'mmp2etl-out',
'format' = 'json'
);
INSERT INTO ods_mmp_out
SELECT
`date`
,'Adjust' as `mmp_type`
,`app_token` as `app_id`
,`event_name`
,`event_time`
,`adid` as `mmp_id`
,`distinct_id`
,`open_id`
,`account_id`
,`os_name`
,`country_code`
,`install_time`
,'' as `bundle_id`
,'' as `media`
,`network` as `channel`
,`campaign`
,REGEXP_EXTRACT(`campaign`, '([\\(=])([a-z0-9]+)', 2) as `campaign_id`
,`adgroup`
,REGEXP_EXTRACT(`adgroup`, '([\\(=])([a-z0-9]+)', 2) as `adgroup_id`
,`creative` as `ad`
,REGEXP_EXTRACT(`creative`, '([\\(=])([a-z0-9]+)', 2) as `ad_id`
,`flink_ts`
,`device_properties`
,`log`
FROM (
SELECT
to_date(FROM_UNIXTIME(cast(JSON_VALUE(log,'$.created_at') as bigint))) as `date`
,JSON_VALUE(log,'$.app_token') as `app_token`
,JSON_VALUE(log,'$.adid') as `adid`
,LOWER(REPLACE( TRIM( COALESCE(JSON_VALUE(log,'$.event_name'), JSON_VALUE(log,'$.activity_kind')) ), ' ', '_')) as `event_name`
,TO_TIMESTAMP(FROM_UNIXTIME(cast(JSON_VALUE(log,'$.created_at') as bigint))) as `event_time`
,TO_TIMESTAMP(FROM_UNIXTIME(cast(JSON_VALUE(log,'$.installed_at') as bigint))) as `install_time`
,LOWER(CASE WHEN (JSON_VALUE(log,'$.network_name') = 'Unattributed') THEN COALESCE(JSON_VALUE(log,'$.fb_install_referrer_publisher_platform'),'facebook') ELSE JSON_VALUE(log,'$.network_name') END) AS `network`
,LOWER(CASE WHEN (JSON_VALUE(log,'$.network_name') = 'Unattributed') THEN (concat(JSON_VALUE(log,'$.fb_install_referrer_campaign_group_name'), '(', JSON_VALUE(log,'$.fb_install_referrer_campaign_group_id'), ')')) ELSE JSON_VALUE(log,'$.campaign_name') END) AS `campaign`
,LOWER(CASE WHEN (JSON_VALUE(log,'$.network_name') = 'Unattributed') THEN (concat(JSON_VALUE(log,'$.fb_install_referrer_campaign_name'), '(', JSON_VALUE(log,'$.fb_install_referrer_campaign_id'), ')')) ELSE JSON_VALUE(log,'$.adgroup_name') END) AS `adgroup`
,LOWER(CASE WHEN (JSON_VALUE(log,'$.network_name') = 'Unattributed') THEN (concat(JSON_VALUE(log,'$.fb_install_referrer_adgroup_name'), '(', JSON_VALUE(log,'$.fb_install_referrer_adgroup_id'), ')')) ELSE JSON_VALUE(log,'$.creative_name') END) AS `creative`
,JSON_VALUE(log,'$.os_name') as `os_name`
,JSON_VALUE(log,'$.country_code') as `country_code`
,JSON_VALUE(JSON_VALUE(log,'$.publisher_parameters'), '$.ta_distinct_id') as `distinct_id`
,JSON_VALUE(JSON_VALUE(log,'$.publisher_parameters'), '$.open_id') as `open_id`
,JSON_VALUE(JSON_VALUE(log,'$.publisher_parameters'), '$.ta_account_id') as `account_id`
,CURRENT_TIMESTAMP as `flink_ts`
,JSON_OBJECT(
'ip' VALUE JSON_VALUE(log,'$.ip')
,'ua' VALUE JSON_VALUE(log,'$.ua')
,'idfa' VALUE JSON_VALUE(log,'$.idfa')
,'idfv' VALUE JSON_VALUE(log,'$.idfv')
,'gps_adid' VALUE JSON_VALUE(log,'$.gps_adid')
,'android_id' VALUE JSON_VALUE(log,'$.android_id')
,'mac_md5' VALUE JSON_VALUE(log,'$.mac_md5')
,'oaid' VALUE JSON_VALUE(log,'$.oaid')
,'gclid' VALUE JSON_VALUE(log,'$.gclid')
,'gbraid' VALUE JSON_VALUE(log,'$.gbraid')
,'dcp_wbraid' VALUE JSON_VALUE(log,'$.dcp_wbraid')
) as `device_properties`
,`log`
FROM ods_adjust_in
WHERE COALESCE(JSON_VALUE(log,'$.activity_kind'), JSON_VALUE(log,'$.event_name')) not in ('impression', 'click')
)
UNION ALL
SELECT
to_date(CONVERT_TZ(JSON_VALUE(log,'$.event_time'), 'UTC', 'Asia/Shanghai')) as `date`
,'AppsFlyer' as `mmp_type`
,JSON_VALUE(log,'$.app_id') as `app_id`
,LOWER(REPLACE( TRIM(JSON_VALUE(log,'$.event_name') ), ' ', '-')) as `event_name`
,TO_TIMESTAMP(CONVERT_TZ(JSON_VALUE(log,'$.event_time'), 'UTC', 'Asia/Shanghai')) as `event_time`
,JSON_VALUE(log,'$.appsflyer_id') as `mmp_id`
,JSON_VALUE(JSON_VALUE(log,'$.custom_data'), '$.ta_distinct_id') as `distinct_id`
,JSON_VALUE(JSON_VALUE(log,'$.custom_data'), '$.open_id') as `open_id`
,JSON_VALUE(JSON_VALUE(log,'$.custom_data'), '$.ta_account_id') as `account_id`
,LOWER(JSON_VALUE(log,'$.platform')) AS `os_name`
,LOWER(JSON_VALUE(log,'$.country_code')) as `country_code`
,TO_TIMESTAMP(CONVERT_TZ(JSON_VALUE(log,'$.install_time'), 'UTC', 'Asia/Shanghai')) as `install_time`
,LOWER(JSON_VALUE(log,'$.bundle_id')) AS `bundle_id`
,LOWER(JSON_VALUE(log,'$.media_source')) AS `media`
,LOWER(JSON_VALUE(log,'$.af_channel')) AS `channel`
,CONCAT(LOWER(JSON_VALUE(log,'$.campaign')), ' (', LOWER(JSON_VALUE(log,'$.af_c_id')), ')') AS `campaign`
,LOWER(JSON_VALUE(log,'$.af_c_id')) AS `campaign_id`
,CONCAT(LOWER(JSON_VALUE(log,'$.af_adset')), ' (', LOWER(JSON_VALUE(log,'$.af_adset_id')), ')') AS `adgroup`
,LOWER(JSON_VALUE(log,'$.af_adset_id')) AS `adgroup_id`
,CONCAT(LOWER(JSON_VALUE(log,'$.af_ad')), ' (', LOWER(JSON_VALUE(log,'$.af_ad_id')), ')') AS `ad`
,LOWER(JSON_VALUE(log,'$.af_ad_id')) AS `ad_id`
,CURRENT_TIMESTAMP as `flink_ts`
,JSON_OBJECT(
'ip' VALUE JSON_VALUE(log,'$.ip')
,'ua' VALUE JSON_VALUE(log,'$.user_agent')
,'idfa' VALUE JSON_VALUE(log,'$.idfa')
,'idfv' VALUE JSON_VALUE(log,'$.idfv')
,'gps_adid' VALUE JSON_VALUE(log,'$.advertising_id')
,'android_id' VALUE JSON_VALUE(log,'$.android_id')
,'oaid' VALUE JSON_VALUE(log,'$.oaid')
) as `device_properties`
,`log`
FROM ods_af_in;
Data reporting: similar to Shenzhe

6. Practical - Tencent Cloud Environment
The Flink task in this article is running in Tencent's kubernetes environment, which includes some related knowledge points that will not be detailed here, for example:
-
Mirror synchronisation: harbor configures automatic synchronisation of mirrors to the Tencent cloud mirror service TCR.
-
Mirror configuration: such as secret-free pull, cache acceleration.
-
Flink webui extranet access: need to buy from the extranet lb in order to access Flink UI.
-
Environmental access: because the kubernetes cluster is mainly a closed intranet computing environment, with the system network, security groups, permissions, routing, etc. need to be well configured and tested, in order to let the task really run in the production environment better.
-
Security Group Configuration: In order to pull real-time data from overseas games and write it to the domestic Kafka cluster to ensure a smooth data flow, we use a dedicated line and open a dedicated extranet access to the kubernetes Flink super node to achieve this.
Relevant screenshots:


7. Benefits and expectations
After using Apache StreamPark, the biggest impression we got is that StreamPark is very easy to use. With simple configuration, we can quickly deploy Flink tasks to any cluster and monitor and manage thousands of jobs in real time, which is very nice!
-
The benefits are as follows: A large number of real-time tasks were quickly migrated to Kubernetes via StreamPark. After YARN was dropped, the Apache Doris cluster, which had been a part of the early mix, became very stable after there was no resource contention.
-
When replenishing data, we can quickly borrow the capacity of super nodes in TKE, and through the StreamPark platform, it is easy to populate and shrink thousands of pods in a minute, which makes replenishment very efficient.
-
The technology stack has become more advanced and unified. The pile of components in the era of big data has become more and more efficient and unified. At present, Joy Big Data has already completed the Kubernetes cloud nativeisation of a series of components such as Doris, Flink, Spark, Hive, Grafana, Prometheus, etc., which makes operation and maintenance simpler and more efficient, and StreamPark has played a great role in the Flink containerisation process.
-
StreamPark platform is easy to operate, complete, stable and responsive to the community, which really makes stream processing job development more and more simple, and brings us a lot of convenience, allowing us to focus more on business, kudos~.
Here, we also expect StreamPark can do better and better, here are some optimisation suggestions:
-
Support Operator Deployment: Expect Flink on kubernetes to support operator deployment method because of its benefits of customising resource types, specifying invocation order, monitoring metrics and so on.
-
Support autoscaler: Because real-time streaming tasks have business peaks and valleys, special weekly events, doubled data volume, and artificial periodic adjustment of parallelism is not very suitable. Therefore, in combination with Kubernetes, we expect StreamPark to complete the operator way to create a Flink cluster as soon as possible. In Flink 1.17 or above, you can set a better threshold, use the automatic pop-up shrinkage to achieve the peak period to pop up more resources to process the data, and in the trough period to shrink the resources to save the cost, and we are very much looking forward to it.
-
programme error logic: the current Flink task set a fixed number of times or ratio retry, but the current StreamPark mail alarms are particularly frequent, not the expected task fails once for an alarm, so I hope that it will be further upgraded.
Finally, we would like to thank the Apache StreamPark community for their selfless help in using StreamPark. Their professionalism and user-centred attitude has enabled us to use this powerful framework more efficiently and smoothly. We look forward to StreamPark getting better and better, and becoming a model for up-and-coming Apache projects!