
导读:本文主要详细介绍欢乐互娱在实战中对大数据技术架构的应用,阐述为何选择 “Kubernetes + StreamPark” 来持续优化和增强现有的架构。不仅系统地阐述了如何在实际环境中部署并运用这些关键技术,更是深入地讲解了 StreamPark 的实践使用,强调理论与实践的完美融合,相信读者通过阅读这篇文章,将有助于理解和掌握相关技术,并能在实践中进步,从而取得显著的学习效果。
Github: https://github.com/apache/streampark
欢迎关注、Star、Fork,参与贡献
供稿单位 | 欢乐互娱
文章作者 | 杜遥
文章整理 | 杨林伟
内容校对 | 潘月鹏
欢乐互娱,是一家全球游戏研发和发行公司;公司产品聚焦在 MMORPG 和 MMOACT 两大品类;欢乐产品理念:“宁做100人尖叫的产品,不做1万人叫好的产品”;欢乐出品,必属精品。《RO仙境传说:爱如初见》上线东南亚,预约期间达成了 1000 万预约的里程碑,上线首日取得五国畅销榜第一,并在日韩美、港澳台等地都有发行,取得了不错的成绩。
1. 业务背景与挑战
欢乐互娱目前使用的大数据底座是腾讯云的 EMR,数仓架构主要分为了如下几类:
-
离线数仓架构:Hadoop + Hive + Dolphinscheduler + Trino
-
实时数仓架构:Kafka + Flink + StreamPark + Doris
-
流式数仓架构(规划中):Paimon + Flink + StreamPark + Doris
其中,流式数仓架构是我们 2024 年的重点计划之一,目标是基于 Kubernetes 的弹性特点以提高大数据分析能力及各种数据产品的价值输出。然而,由于早前的架构原因(主要是 Apache Doris 和 EMR 核心节点的混部署),让我们遇到了许多问题,例如:
-
资源争夺:在 YARN 资源调度平台下,Apache Doris、Apache Flink 实时任务、Hive 的离线任务以及 Spark 的 SQL 任务经常争抢 CPU 和内存资源,导致 Doris 查询稳定性下降,查询错误频繁。
-
资源不足:YARN 的机器资源使用率大部分时间位于 70% 至 80% 之间,特别是在大量的补数的场景下,集群资源往往不足。
-
人工干预:实时 Flink 的任务越来越多,各游戏的数据在一天内有明显的波峰波谷变化,特别是在周末进行的挂机活动,数据量翻倍,甚至增加至每天超过 100 亿条,而且这需要频繁地手动调整并行度来适应计算压力,以保证数据消费能力。
2. 解决方案选型
为了解决以上问题,我们寻求能够进行 “资源弹性伸缩” 和 “任务管理” 的相关组件,同时考虑到大数据云原生的趋势,采用云原生的架构迫在眉睫, Kubernetes 架构下能为大数据运维减负、提供高可用、负载均衡、灰度更新等更好更稳定的能力。
同时简化 Apache Flink 实时任务的开发和运维也是不得不面对的问题,自 2022 年中旬开始,就重点研究 Flink 相关的开源和商业化相关的项目,在进行技术选型时,公司主要从几个关键维度进行了深入考察,包括:Kubernetes 容器化部署、轻量程度、多 Flink版本的支持、功能的完备性、多种部署模式、对 CI/CD 的支持以及稳定性、成熟度等,最终不出意外的选择了 Apache StreamPark。
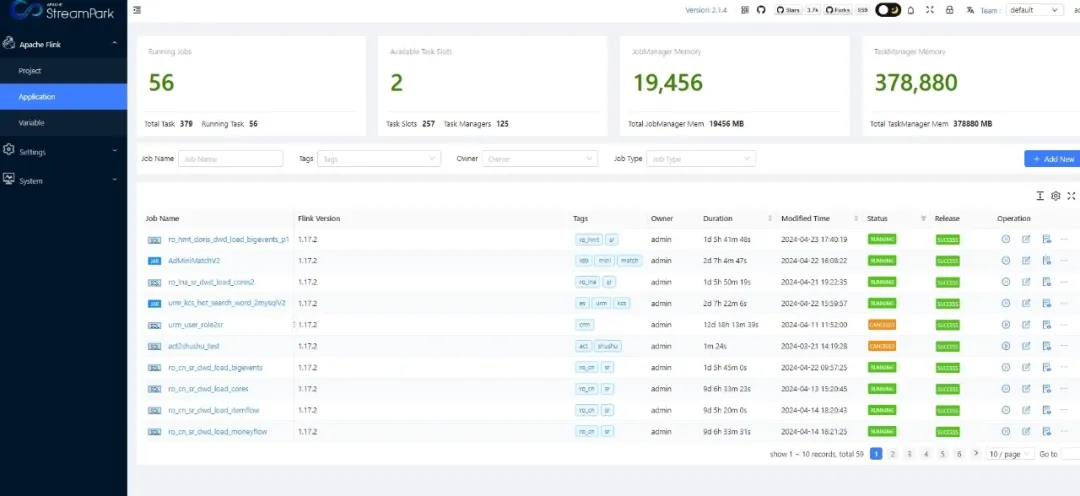
我们在使用 StreamPark 的过程中,对其进行了深入的应用和探索,已经成功实现了100+ Flink 任务轻松部署到 Kubernetes,可以十分方便地进行作业管理。
接下来,将详述我们是如何使用 StreamPark 实现 Flink on kubernetes 在生产环境中的实践过程,尽管内容较长,但是干货满满,内容主要分为以下的几个部分:
-
环境准备篇:这部分介绍 Kubernetes、StreamPark、Maven、Docker、kubectl 工具和 Flink 的安装与配置过程。
-
StreamPark 使用篇:这部分介绍如何使用 StreamPark 启动 Session 集群,以及部署 SQL、JAR 作业的流程等。
-
Flink 任务应用场景篇:在这一部分,将分享欢乐互娱实际运用 Flink 任务的实践场景。
3. 落地实践 - 环境准备篇
接下来我们将从安装开始详细介绍 StreamPark 的落地实践,关于腾讯云产品的一些使用步骤,将在文末简要介绍,此处主要分享核心的步骤。
3.1. 准备 Kubernetes 环境
欢乐互娱的 Kubernetes 环境使用的是腾讯云容器服务产品,其中 Kubernetes 命名空间主要划分如下:
-
Apache Doris:Doris 集群 + 3 FE(标准节点) + CN(1 台超级节点)。
-
Apache Flink:Flink 集群由一个超级节点组成,这个节点相当于一台超大资源的机器,使用起来非常简单,并且可以迅速弹性扩展到数以万计的 pod。
-
BigData:包含各种大数据组件。
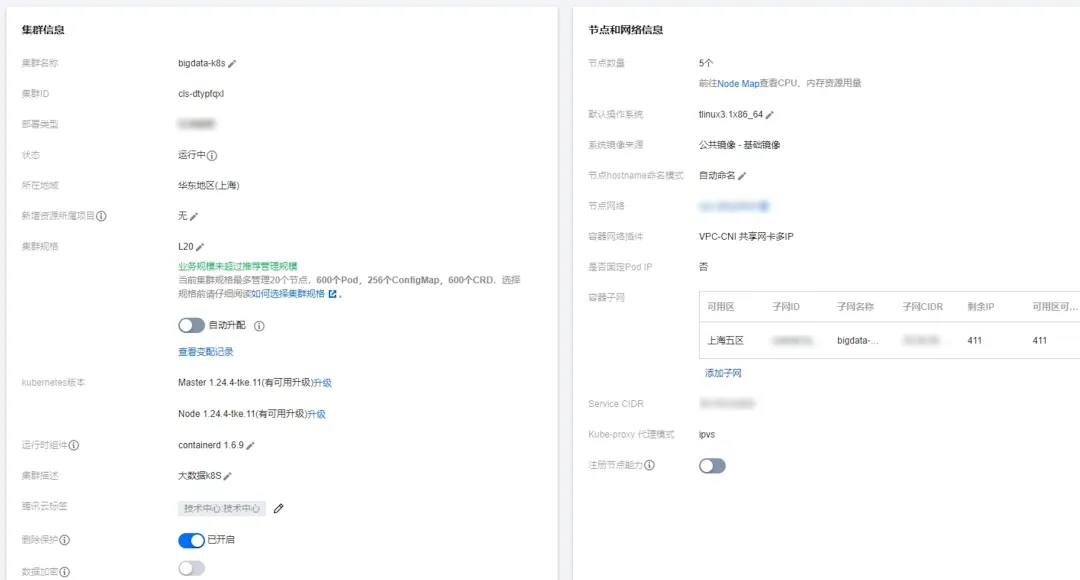
另外,我们还有两台原生节点,主要用于部署 StreamPark、Dolphinscheduler 以及 Prometheus + Grafana。集群信息相关截图如下:
3.2. 安装 StreamPark
我们采用�的是 StreamPark 2.1.4 最新的稳定版本,该版本修复了一些 Bug,并增加了一些新的特性,如支持 Flink 1.18、Jar 任务支持通过 pom 或者上传依赖等。
虽然 StreamPark 支持 Docker 和 Kubernetes 部署,但是出于节省时间和对所有大数据组件需要进行顶层设计容器化的考虑,我们当前选择了在云上的 CVM 上进行 StreamPark 的快速搭建,以下是 StreamPark 的安装部署脚本:
#使用 root 用户进入安装目录(需先有 java 环境)和 k8s 环境同一个网段!!!可以省事
cd /data
#下载二进制安装包
wget https://dlcdn.apache.org/incubator/streampark/2.1.4/apache-streampark_2.12-2.1.4-incubating-bin.tar.gz
#与提供的值进行比较、保证包的完成性
sha512sum apache-streampark_2.12-2.1.2-incubating-bin.tar.gz #解压缩
tar -xzvf apache-streampark_2.12-2.1.2-incubating-bin.tar.gz #改名
mv apache-streampark_2.12-2.1.2-incubating-bin streampark_2.12-2.1.2 #创建软链
ln -s streampark_2.12-2.1.2 streampark
#修改数据库配置
vim /data/streampark/conf/application-mysql.ymlspring:
datasource:
username: root
password: xxxxx
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://10.16.x.x:3306/streampark_k8s?...
# 修改 streampark 核心配置 可以修改下端口(因为 k8s nodeport 端口范围 30000-32767) 故可以配置这个范围 省去端口对外开发再配置 或者账号密码 我们存储用 cos 故不配置 hdfs
vim /data/streampark/conf/application.yml workspace:
local: /data/streampark/streampark_workspace #创建需要的目录
mkdir -p vim /data/streampark/conf/application.yml
#初始化 streampark 的数据库表 要求环境有 mysql 客户端 执行完可以去 mysql 中看下库表是否存在
mysql -u root -p xxxxx < /data/streampark/script/schema/mysql-schema.sql
#添加依赖的 mysql-connector 包 因为 streampark lib下面没有 在 /data/streampark/lib下执行
wget https://repo1.maven.org/maven2/com/mysql/mysql-connector-j/8.0.33/mysql-connector-j-8.0.33.jar
#启动并登陆 可以先验证下 java 环境 java -version 确保没问题 在 /data/streampark/lib下执行
./startup.sh
3.3. 安装 Maven
在 StreamPark 上配置 Flink 任务时可以通过 maven 下载相关依赖,下面是 Maven 的安装配置:
#下载 maven 同 root 用户操作
cd /data && wget https://dlcdn.apache.org/maven/maven-3/3.9.6/binaries/apache-maven-3.9.6-bin.tar.gz
#检验安装包完整
sha512sum apache-maven-3.9.6-bin.tar.gz
#解压 软连
tar -xzvf apache-maven-3.9.6-bin.tar.gz
ln -s apache-maven-3.9.6 maven
# 设置阿里云仓库 maven mirror,加速下载
vim /data/maven/conf/settings.xml
<mirror>
<id>alimaven</id>
<mirrorOf>central</mirrorOf>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/repository/central</url>
</mirror>
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
#环境变量 最后添加
vim /etc/profile
export MAVEN_HOME=/data/maven
PATH=$MAVEN_HOME/bin:$PATH
#生效 验证
source /etc/profile && mvn -version
3.4 安装 Docker
因为 StreamPark 使用 Kubernetes 时,可以使用 Docker 来构建和上传镜像到公司常用的 Harbor 镜像服务中,以下是 Docker 的安装脚本
#卸载旧版本 如果有
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
#下载镜像仓库
wget -O /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo #阿里云docker-ce 镜像
#更新软件包索引
yum makecache
#下载安装
yum install docker-ce docker-ce-cli containerd.io -y # docker-ce 社区版 ee 企业版
#启动 查看
systemctl start docker && docker version
#开机自启
systemctl enable docker
3.5. Kubectl 工具安装
为了方便与 Kubernetes 集群进行交互、进行配置查看、访问日志等,我们还安装了kubectl 工具。安装 kubectl 前,首先需要先从这里获取 Kubernetes 集群的访问凭证,下载方式如下图:
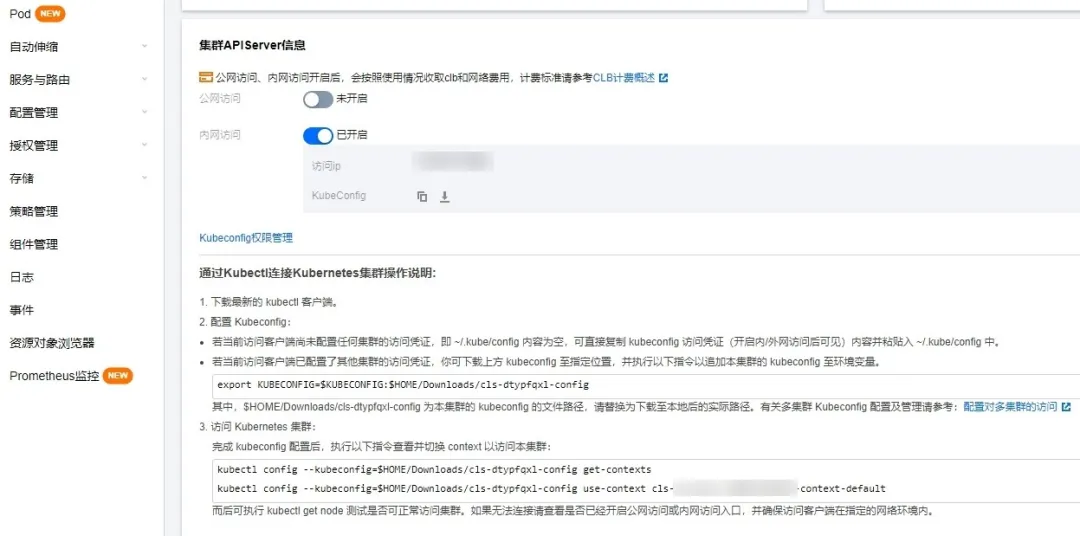
接着下载配置拷贝到 root 用户目录,指定目录并改名:
# 1)创建默认隐藏目录
mkdir -p /root/.kube
# 2)上传 k8s 内网访问凭证
rz cls-dtyxxxxl-config
# 3)修改凭证默认名字
mv cls-dtyxxxxl-config config
# 4)将凭证放到指定位置
mv config /root/.kube
具体安装 kubetcl 客户端命令如下(当然也可以安装 kubectx ,更加方便地去访问多个 kubernetes 集群和切换固定的命名空间):
# 1)下载最新版
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
# 2)添加执行权限
chmod +x kubectl
# 3)移动到常用的工具命令位置
mv ./kubectl /usr/local/bin/kubectl
# 4)可以在 /etc/profile 或者 root用户家目录的 .bashrc 中配置
vim /root/.bashrc
export JAVA_HOME=/usr/local/jdk1.8.0_391
PATH=/usr/local/bin:$JAVA_HOME/bin:$PATH
# 5)验证客户端和集群密钥
kubectl cluster-info
最后,还需要创建一个 Flink 专用的账户凭证(后面会用到):
# 1)创建命名空间
kubectl create namespace flink
# 2)创建 flink 访问 k8s 的账号 记得带命名空间!
kubectl create serviceaccount flink-service-account -n flink
# 3)给该账号绑定容器操作的一些权限 记得带命名空间!!!
kubectl create clusterrolebinding flink-role-binding-flink --clusterrole=edit --serviceaccount=flink:flink-service-account -n flink
3.6. 安装配置 Flink
我们 Kubernetes 环境选择了 Flink1.17-scala2.12 Java11 的镜像,因为当时 Flink 1.18 有些依赖包不好找。
下载并解压 flink-1.17.2-bin-scala_2.12.tgz 安装包,脚本如下:
cd /data && wget https://dlcdn.apache.org/flink/flink-1.17.2/flink-1.17.2-bin-scala_2.12.tgz
#完整性校验
sha512sum flink-1.17.2-bin-scala_2.12.tgz
#解压
tar -xzvf flink-1.17.2-bin-scala_2.12.tgz
#改名
mv flink-1.17.2-bin-scala_2.12 flink-1.17.2
#软连
ln -s flink-1.17.2 flink
#旧二进制包收纳
mv flink-1.17.2-bin-scala_2.12.tgz /data/softbag
至此,我们已经把环境搭建好了,下面继续按步骤详细讲解 StreamPark 的使用。
4. 落地实践 - StreamPark 使用篇
想快速了解 StreamPark 运行作业至 Kubernetes 的读�者,可以观看下面的视频:
//视频链接 (Flink On Kubernetes Application 上手教程)
//视频链接 (Flink On Kubernetes Session 上手教程)
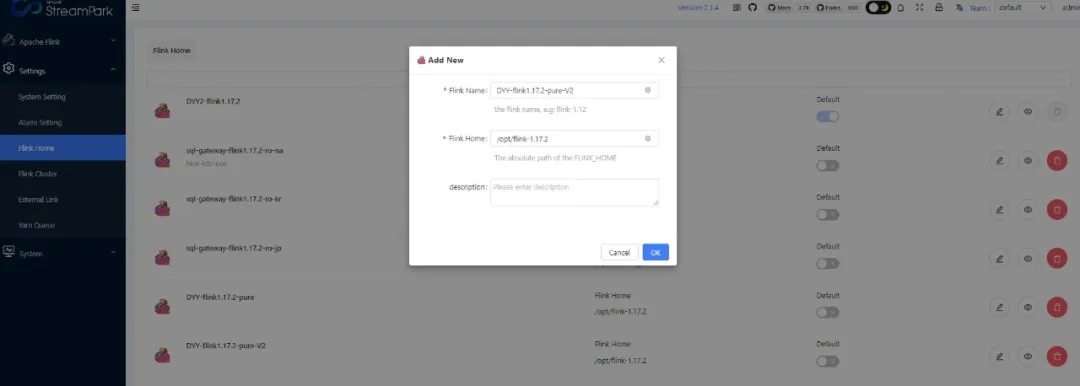
4.1. 配置 Flink Home
登录 StreamPark 之后,切换至 Flink Home 菜单,配置我们在前面解压的 Flink 安装包目录,截图如下:
4.2. 创建 Flink Session
接着切换到 FlinkCluster,Add New 新增一个 Flink 集群:
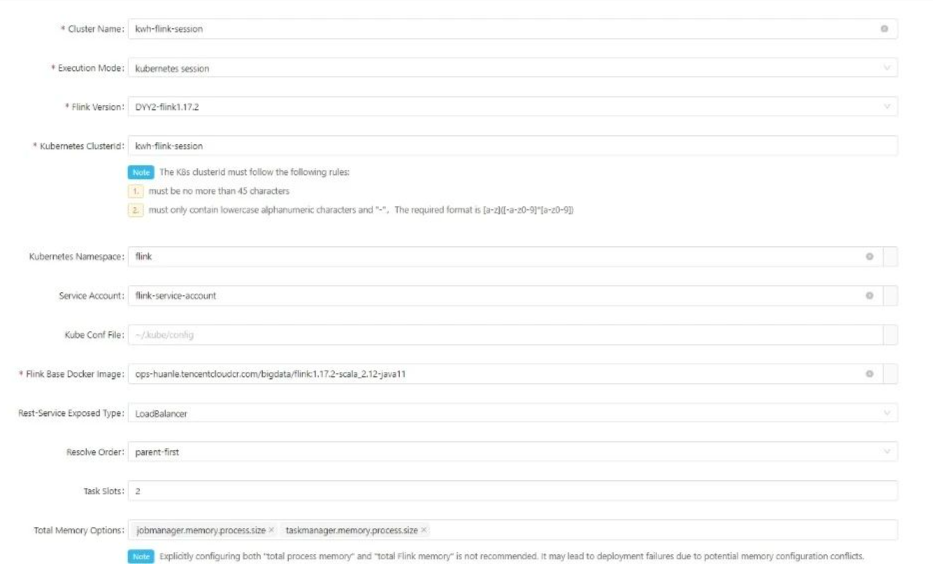
配置详情如下,以下是第一部分的配置内容:
配置详解:集群名字和 Kubernetes 集群 ID 我们通常写一样,填写正确的 Kubernetes 服务账号,这里的镜像使用腾讯云 tcr 中的镜像,并使用 lb 作为对外访问 Flink UI 的方式。这里的槽一般设置为 2,任务并行度一般是 2 的倍数,这样就可以让 Session 集群没有闲置的资源)
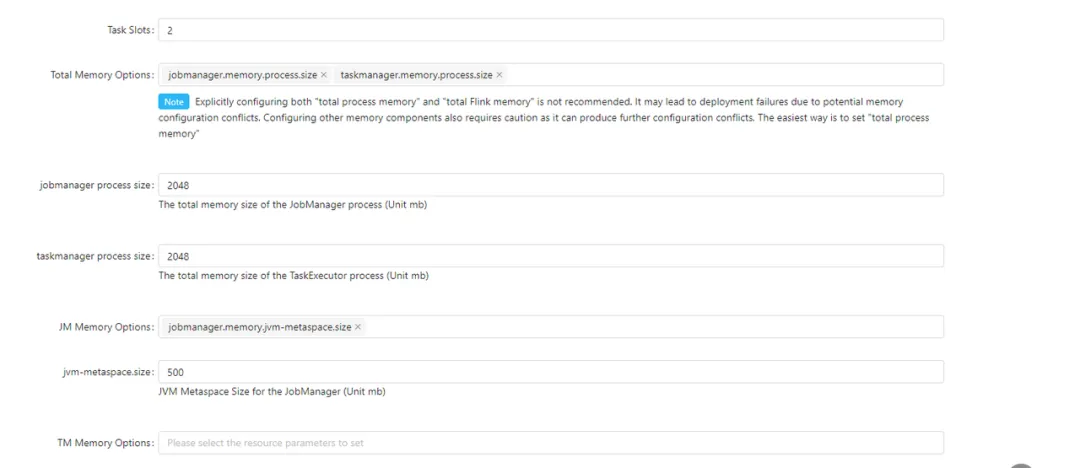
第二部分的配置内容:
配置详解:我们采取��的是 Session 模式,一个 JobManager 管理着很多任务,故资源可以稍微大一些,我们给 2G,经观察可以满足,但是由于任务多,JobManager 的内存分配中 metaspace 消耗比较大,故可以将默认的 256M,改到 500M,经过观察,一个 Session 管理 10 个任务以下,这个配置合理。
TaskManager 内存在 session 配置给出后,在 StreamPark 程序配置页将无法修改,故可以对 Session 项目数据量进行预估,数据量大就可以 把 “CPU : 内存” 调整到 “1 核 : 2G”,当然也可以更大,因为数据处理还有 TaskManager 数量有关,也就是并行度有关,这样基本就可以避免一些 OOM 问题,我们 “1 : 2” Session 集群项目一天处理数据量 60 亿,18 个并行度,仅供参考。默认 cpu: 内存 1 : 1 基本 ok。
最后一部分的内容如下:
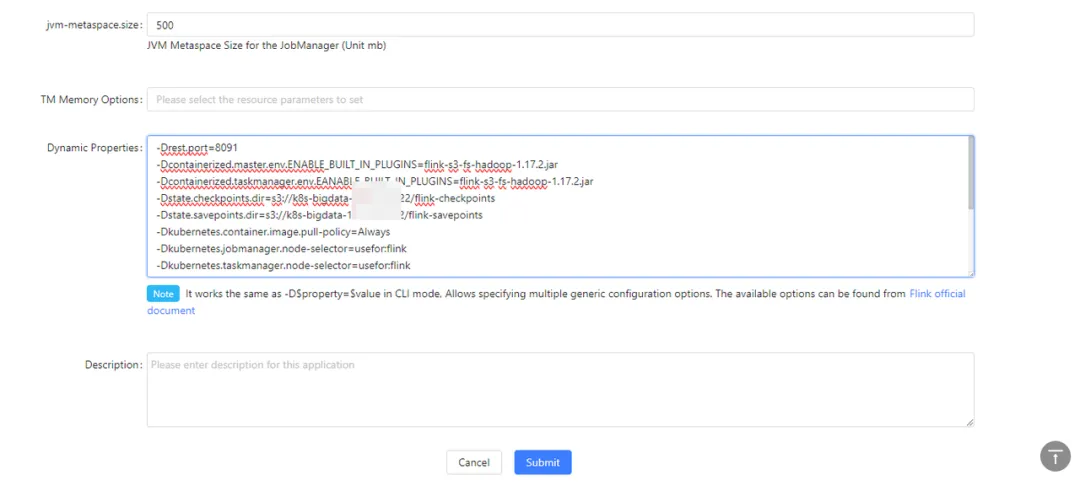
这里贴出具体的文本内容:
#访问方式 复用lb+port lb可以提前创建 不用k8s创建 这样ip固定。复用后更加方便
-Drest.port=8091
-Dkubernetes.rest-service.annotations=service.kubernetes.io/qcloud-share-existed-lb:true,service.kubernetes.io/tke-existed-lbid:lb-iv9ixxxxx
-Dkubernetes.rest-service.exposed.type=LoadBalancer
#cp sp 使用s3协议访问腾讯云cos 插件方式依赖包 s3的cos认证
-Dcontainerized.master.env.ENABLE_BUILT_IN_PLUGINS=flink-s3-fs-hadoop-1.17.2.jar
-Dcontainerized.taskmanager.env.EANABLE_BUILT_IN_PLUGINS=flink-s3-fs-hadoop-1.17.2.jar
-Dstate.checkpoints.dir=s3://k8s-bigdata-xxxxxx/flink-checkpoints
-Dstate.savepoints.dir=s3://k8s-bigdata-xxxxx/flink-savepoints
#k8s中的任务调度策略、节点选择策略,因为flink命名空间是逻辑的,而节点选择策略可以让其跑在flink专用的物理超级节点上去
-Dkubernetes.jobmanager.node-selector=usefor:flink
-Dkubernetes.taskmanager.node-selector=usefor:flink
#开启jobmanager高可用 使用 k8s��实现方式、 使用cos的目录存储 整体就不用hdfs
-Dhigh-availability.type=kubernetes
-Dhigh-availability.storageDir=s3://k8s-bigdata-xxx/flink-recovery
-Dkubernetes.cluster-id=streampark-share-session
-Dkubernetes.jobmanager.replicas=2
#pod镜像拉取策略和flink取消cp的保留 时区
-Dkubernetes.container.image.pull-policy=Always
-Dexecution.checkpointing.externalized-checkpoint-retention=RETAIN_ON_CANCELLATION
-Dtable.local-time-zone=Asia/Shanghai
#镜像拉取缓存加速 详细下文有解释
-Dkubernetes.taskmanager.annotations=eks.tke.cloud.tencent.com/use-image-cache: imc-6iubofdt
-Dkubernetes.jobmanager.annotations=eks.tke.cloud.tencent.com/use-image-cache: imc-6iubofdt
备注:Flink 基础信息的可以配置到 conf 文件中,更多程序通用的建议在 session 中写好,StreamPark 中填写 并行度/cp/sp/容错/main 参数等比较合适。
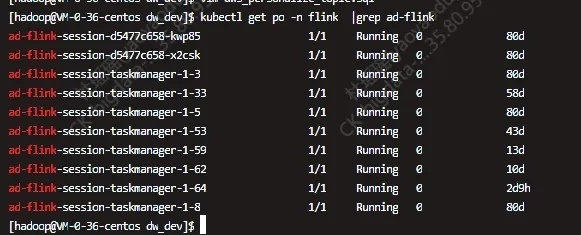
最后启动 Session 集群即可,可以通过 kubectl 命令来查看 Flink kubernetes session 集群是否成功启动:

4.3. 任务配置
这里将继续展示使用 StreamPark 提交3种类型的任务,分别是 SQL任务、Jar任务 以及 Application 模式任务。
- 提交 Flink SQL 任务
Flink Sql 作业的配置截图如下:
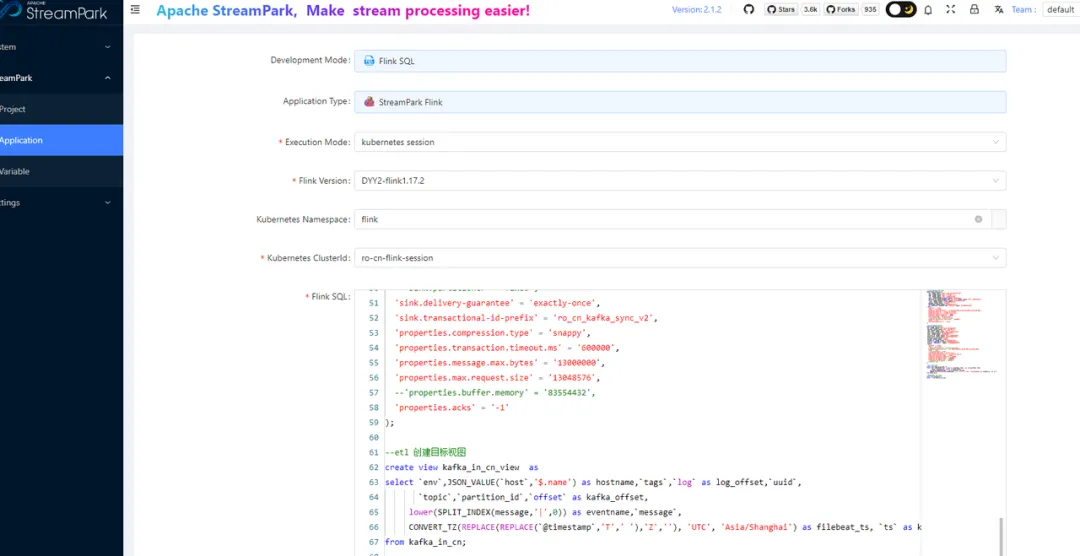
其中的 kubernetes clusterid 填写对应的项目 session 名就行:
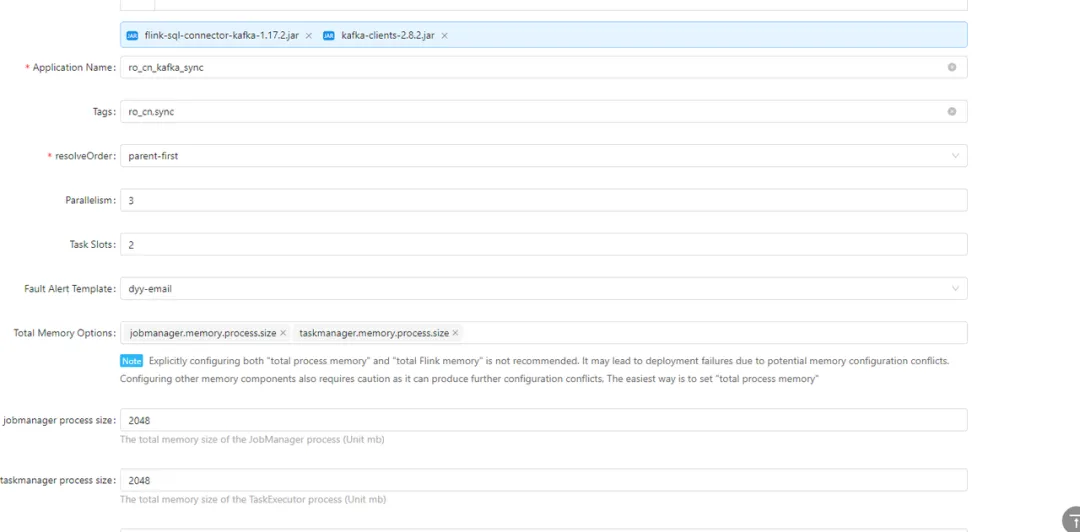
动态参数配置如下:
-Dstate.checkpoints.dir=s3://k8s-bigdata-12xxxxx/flink-checkpoints/ro-cn-sync
-Dstate.savepoints.dir=s3://k8s-bigdata-12xxxxxxx/flink-savepoints/ro-cn-sync
-Dkubernetes.container.image.pull-policy=Always
-Dkubernetes.service-account=flink-service-account
-Dexecution.checkpointing.interval=25s
-Dexecution.checkpointing.mode=EXACTLY_ONCE
-Dtable.local-time-zone=Asia/Shanghai
-Drestart-strategy.fixed-delay.attempts=10
-Drestart-strategy.fixed-delay.delay=3min
- 提交 Flink JAR 任务
Jar 任务基本和 Sql 任务基本一样,配置截图如下:
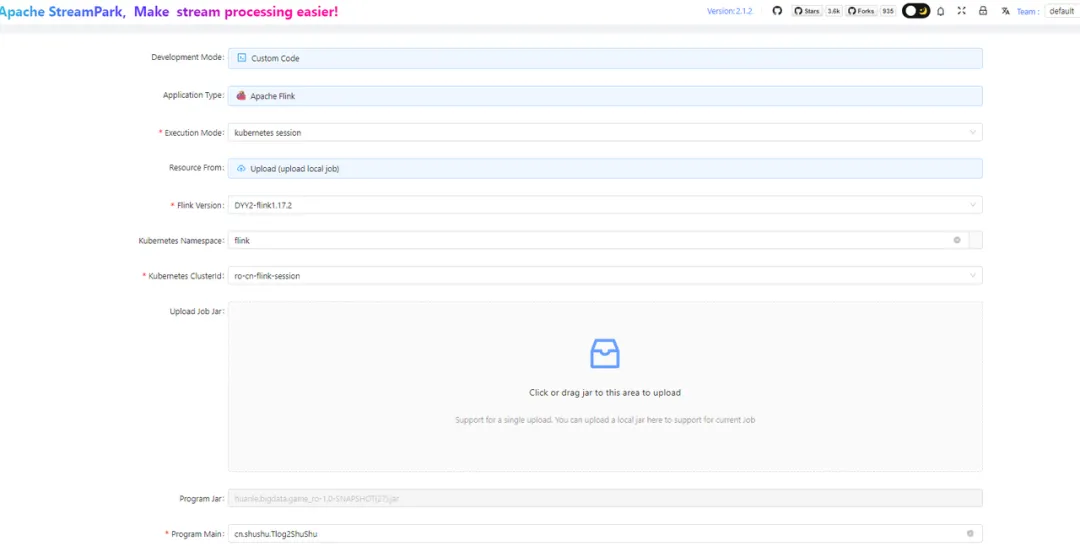
动态参数如下(如果有配置模版,这里就可以更加精简,因为 StreamPark 支持很好的任务复制,故可以写一标准的 Jar 和 SQL 的任务 demo,剩下任务都采用复制,可大大提高任务开发效率):
-Dstate.checkpoints.dir=s3://k8s-bigdata-1xxxx/flink-checkpoints/ro-cn-shushu
-Dstate.savepoints.dir=s3://k8s-bigdata-1xxxx/flink-savepoints/ro-cn-shushu
-Dkubernetes.container.image.pull-policy=Always
-Dkubernetes.service-account=flink-service-account
-Dexecution.checkpointing.interval=60s
-Dexecution.checkpointing.mode=EXACTLY_ONCE
-Dstate.checkpoints.num-retained=2
-Drestart-strategy.type=failure-rate
-Drestart-strategy.failure-rate.delay=3min
-Drestart-strategy.failure-rate.failure-rate-interval=30min
-Drestart-strategy.failure-rate.max-failures-per-interval=8
- 提交 Flink Application 任务
当然也可以部署 Application 模式的任务至 Kubernetes,这里贴上示例,首先是第一部分的配置内容:
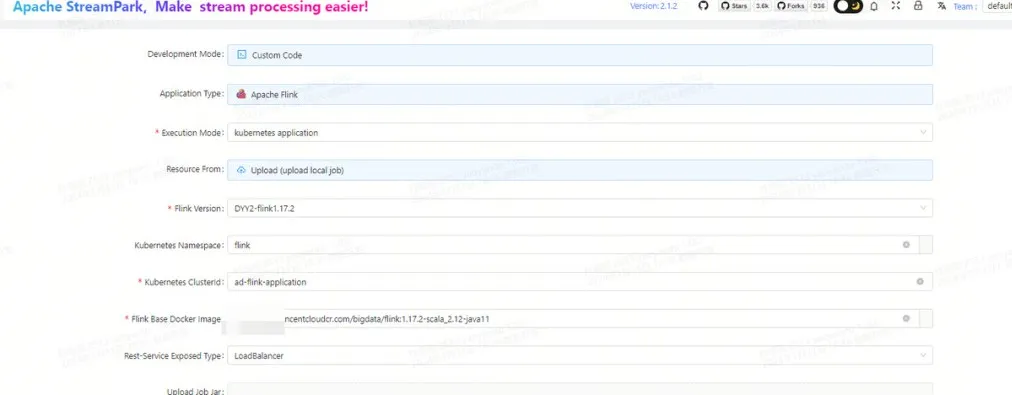
这是第二部分的配置内容如下:
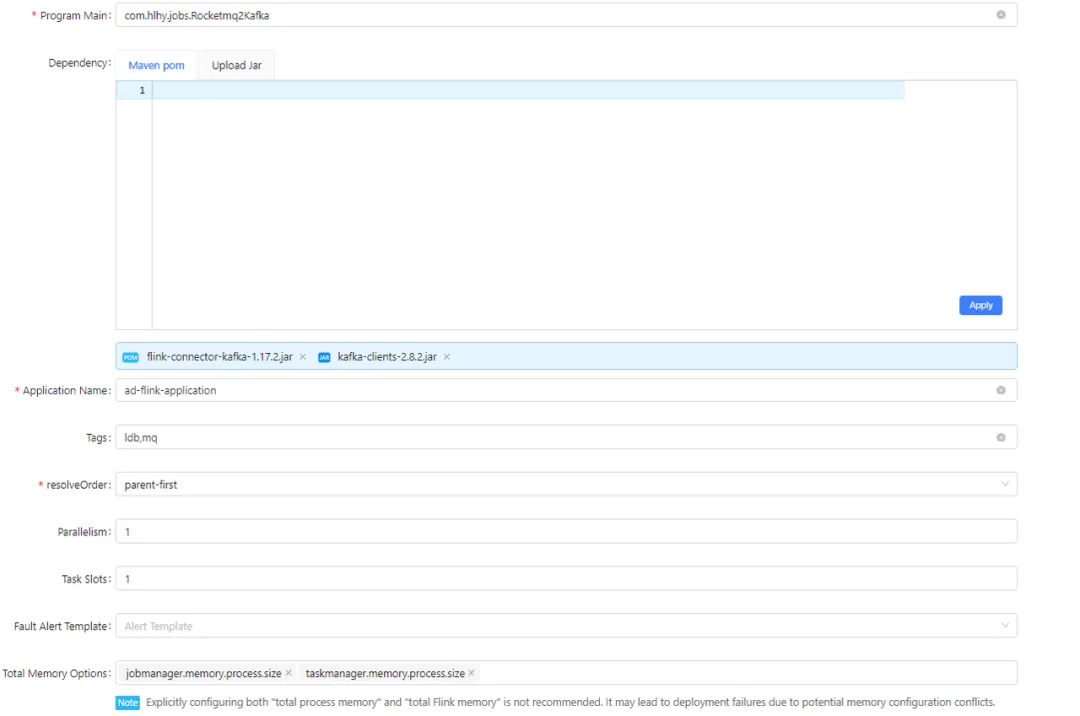
第三部分的配置内容如下:
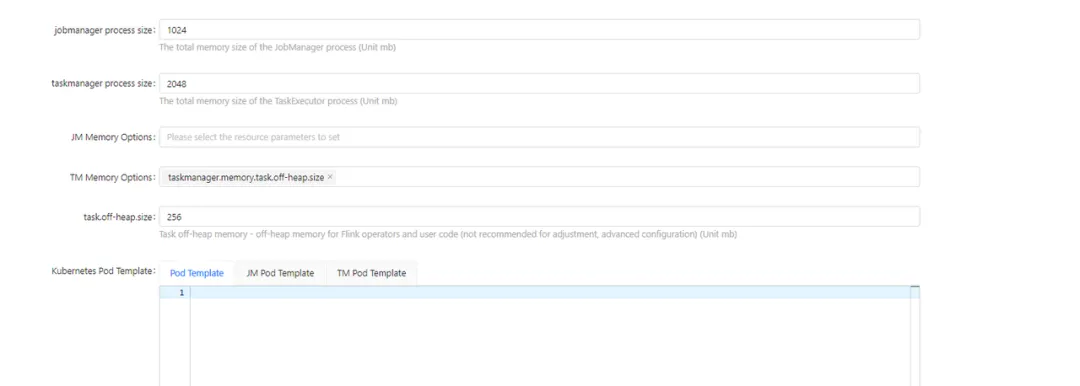
动态参数:
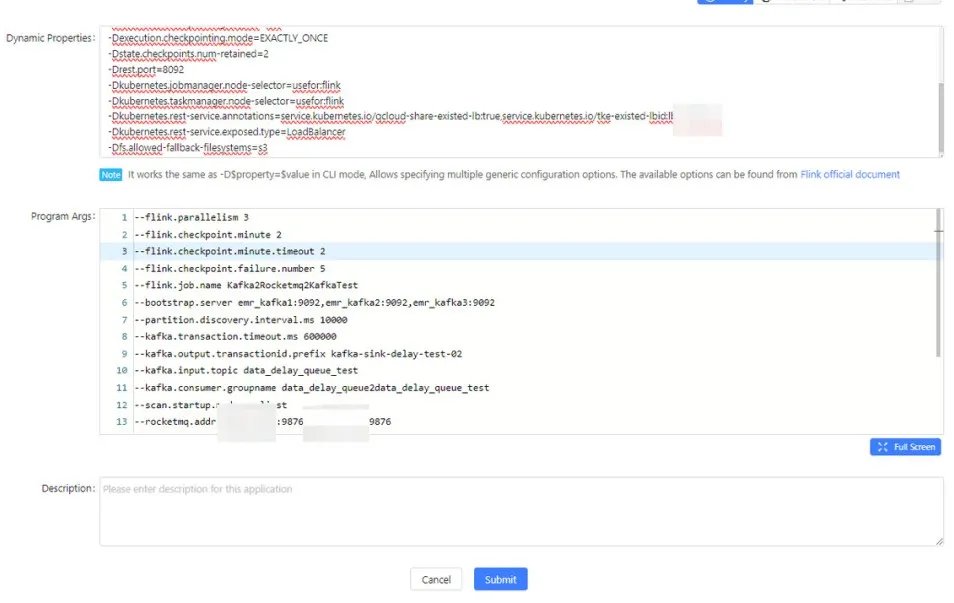
详细的配置内容:
-Dcontainerized.master.env.ENABLE_BUILT_IN_PLUGINS=flink-s3-fs-hadoop-1.17.2.jar
-Dcontainerized.taskmanager.env.ENABLE_BUILT_IN_PLUGINS=flink-s3-fs-hadoop-1.17.2.jar
-Dstate.checkpoints.dir=s3://k8s-bigdata-xxx/flink-checkpoints/Kafka2Rocketmq2Kafka
-Dstate.savepoints.dir=s3://k8s-bigdata-xxx/flink-savepoints/Kafka2Rocketmq2Kafka
-Dkubernetes.container.image.pull-policy=Always
-Dkubernetes.service-account=flink-service-account
-Dexecution.checkpointing.interval=60s
-Dexecution.checkpointing.mode=EXACTLY_ONCE
-Dstate.checkpoints.num-retained=2
-Drest.port=8092
-Dkubernetes.jobmanager.node-selector=usefor:flink
-Dkubernetes.taskmanager.node-selector=usefor:flink
-Dkubernetes.rest-service.annotations=service.kubernetes.io/qcloud-share-existed-lb:true,service.kubernetes.io/tke-existed-lbid:lb-xxx
-Dkubernetes.rest-service.exposed.type=LoadBalancer
-Dfs.allowed-fallback-filesystems=s3
4.4. 构建任务
接着对任务进行构建,这里可以很清晰的看到任务构建的每一步骤:
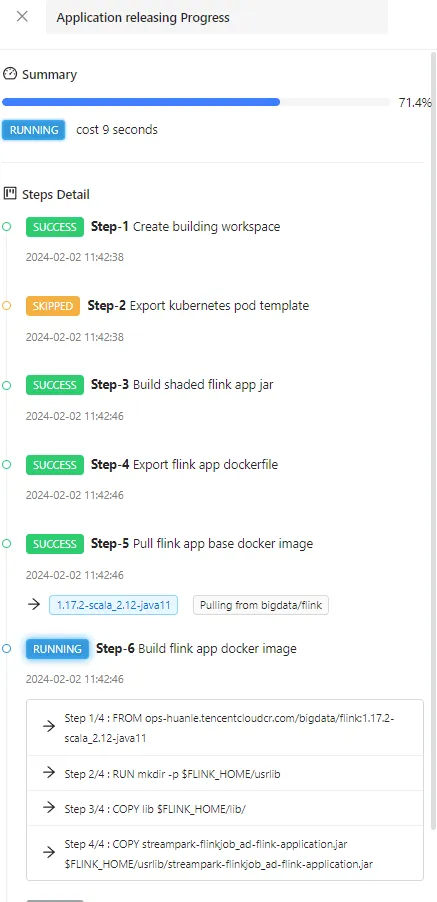
最终可以跑起来观察到任务正在运行:
4.5. 通知告警配置(非必选)
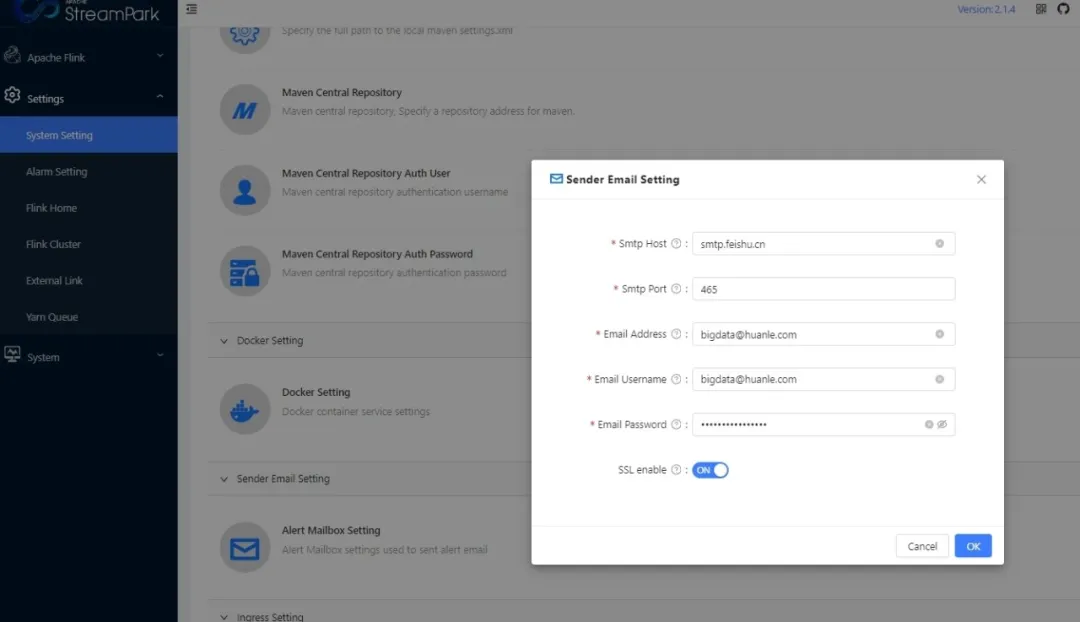
当然 StreamPark 支持多种通知告警方式(例如:邮箱和飞书等),我们使用的是邮箱的方式,直接界面配置即可:
至此,我们已经分享了如何在 StremPark 中成功地去部署运行在 kubernetes 不同类型的 Flink任务,十分的丝滑!
5. 落地实践 - 作业应用场景篇
接下来,继续针对作业进行剖析,从调优、实操等场景中让我们更进一步地去了解 Flink 任务的应用。
5.1. 调优建议
建议一(时区):容器中需要以utc+8方便看日志,我们可以在conf配置中添加如下:
env.java.opts.jobmanager: -Duser.timezone=GMT+08
env.java.opts.taskmanager: -Duser.timezone=GMT+08
建议二(StreamPark变量管理):StreamPark 提供变量管理、让我们可以管理一些配置,提高安全和便捷性:

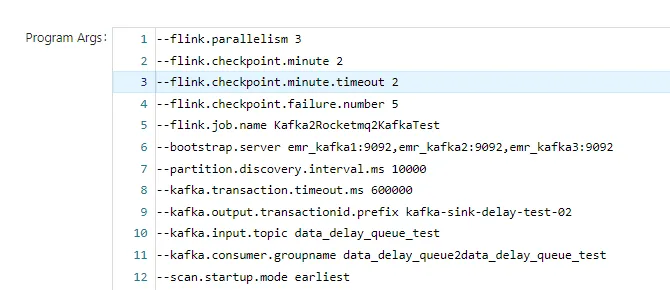
建议三(StreamPark传参):在 on YARN 上使用 Flink自带的工具类传参数,参数难传递到 Flink 环境去,我们也没深究。我们选择通过 StreamPark 传入程序参数,这样在 YARN 和 kubernetes 都可以用,同时在 kubernetes 的 application 和 session 方式也都可以用,变得更加通用且改动方便,强烈推荐!
建议四(使用Session模式):尽管 Yarn-application模式提供了高度的任务隔离,但其每个任务都需要独立的 jobmanager 资源,这导致资源消耗过高。此外,合并任务虽然可以减少资源消耗,但会带来工作量大、数据不稳定等问题。相比之下,session 模式允许任务�在一个 session 中共享一个 jobmanager 资源,这可以最大限度地节约计算资源,虽然它可能存在单点问题,但可以通过使用两个 jobmanager 实例实现高可用性来解决。更重要的是,session 模式还可以更方便地查看因任务失败而产生的日志,有助于提高故障诊断的效率。因此,鉴于其在资源利用、高可用性和任务故障处理方面的优势,选择 session 模式成为了一种更为理想的选择。
5.2. 数据CDC同步
【MySQL → Doris】:下面代码主要演示了 MySQL 数据同步至 Apache Doris 的 Flink sql 流水线:
CREATE TABLE IF NOT EXISTS `login_log_mysql` (
login_log_id bigint not null,
account_id bigint ,
long_account_id string ,
short_account_id string ,
game_code string ,
package_code string ,
channel_id int ,
login_at int ,
login_ip string ,
device_ua string ,
device_id string ,
device_net string ,
device_ratio string ,
device_os string ,
device_carrier string ,
ext string ,
created_at int ,
updated_at int ,
deleted_at int ,
PRIMARY KEY(`login_log_id`)
NOT ENFORCED
) with (
'connector' = 'mysql-cdc',
'hostname' = '10.xxx.xxx.xxx',
'port' = '3306',
'username' = 'http_readxxxxx',
'password' = 'xxxx@)',
'database-name' = 'player_user_center',
-- 'scan.startup.mode' = 'latest-offset',
'scan.startup.mode' = 'earliest-offset',
'table-name' = 'login_log_202[3-9][0-9]{2}',
'server-time-zone' = '+07:00'
);
create table if not EXISTS login_log_doris(
`date` date ,
login_log_id bigint ,
account_id bigint ,
long_account_id string ,
short_account_id string ,
game_code string ,
`package_code` string ,
`channel_id` int ,
login_at string ,
login_ip string ,
device_ua string ,
device_id string ,
device_net string ,
device_ratio string ,
device_os string ,
device_carrier string ,
ext string ,
created_at string ,
updated_at string ,
deleted_at string ,
PRIMARY KEY(`date`,`login_log_id`)
NOT ENFORCED
) WITH (
'connector' = 'doris',
'jdbc-url'='jdbc:mysql://xxx.xx.xx.xx:9030,xxx.xxx.xxx.xxx:9030,xxx.xxx.xxx.xxx:9030',
'load-url'='xxx.xx.xx.xx:8030;xxx.xx.xx.xx:8030;xxx.xx.xx.xx:8030',
'database-name' = 'ro_sea_player_user_center',
'table-name' = 'ods_login_log',
'username' = 'root',
'password' = 'root123',
'sink.semantic' = 'exactly-once',
'sink.max-retries' = '10'
);
create view login_log_flink_trans as
select
to_date(cast(to_timestamp_ltz(login_at,0) as varchar) ) ,
login_log_id ,
account_id ,
long_account_id ,
short_account_id ,
game_code ,
package_code ,
channel_id,
cast(to_timestamp_ltz(login_at,0) as varchar) as login_at,
login_ip ,
device_ua ,
device_id ,
device_net ,
device_ratio ,
device_os ,
device_carrier ,
ext ,
cast(to_timestamp_ltz(created_at,0) as varchar) as created_at,
cast(to_timestamp_ltz(updated_at,0) as varchar) as updated_at,
cast(to_timestamp_ltz(deleted_at,0) as varchar) as deleted_at
from login_log_mysql;
insert into login_log_doris select * from login_log_flink_trans;
CREATE TABLE IF NOT EXISTS `account_mysql` (
account_id bigint ,
open_id string ,
dy_openid string ,
dy_ios_openid string ,
ext string ,
last_channel int ,
last_login_time int ,
last_login_ip string ,
created_at int ,
updated_at int ,
deleted_at string ,
PRIMARY KEY(`account_id`)
NOT ENFORCED
) with (
'connector' = 'mysql-cdc',
'hostname' = 'xxx.xx.xx.xx',
'port' = '3306',
'username' = 'http_readxxxx',
'password' = 'xxxxx@)',
'database-name' = 'player_user_center',
-- 'scan.startup.mode' = 'latest-offset',
'scan.startup.mode' = 'earliest-offset',
'table-name' = 'account_[0-9]+',
'server-time-zone' = '+07:00'
);
create table if not EXISTS account_doris(
`date` date ,
account_id bigint ,
open_id string ,
dy_openid string ,
dy_ios_openid string ,
ext string ,
`last_channel` int ,
last_login_time string ,
last_login_ip string ,
created_at string ,
updated_at string ,
deleted_at string ,
PRIMARY KEY(`date`,`account_id`)
NOT ENFORCED
) WITH (
'connector' = 'doris',
'jdbc-url'='jdbc:mysql://xxx.xx.xx.xx:9030,xxx.xx.xx.xx:9030,xxx.xx.xx.xx:9030',
'load-url'='xxx.xx.xx.xx:8030;xxx.xx.xx.xx:8030;xxx.xx.xx.xx:8030',
'database-name' = 'ro_sea_player_user_center',
'table-name' = 'ods_account_log',
'username' = 'root',
'password' = 'root123',
'sink.semantic' = 'exactly-once',
'sink.max-retries' = '10'
);
create view account_flink_trans as
select
to_date(cast(to_timestamp_ltz(created_at,0) as varchar) ) ,
account_id ,
open_id ,
dy_openid ,
dy_ios_openid ,
ext ,
last_channel,
cast(to_timestamp_ltz(last_login_time,0) as varchar) as last_login_time,
last_login_ip ,
cast(to_timestamp_ltz(created_at,0) as varchar) as created_at,
cast(to_timestamp_ltz(updated_at,0) as varchar) as updated_at,
deleted_at
from account_mysql;
insert into account_doris select * from account_flink_trans;
【游戏数据同步】:将海外 filebeat 采集的 kafka 数据拉到国内 kafka,并进行处理元数据加工:
--创建hmt 的kafka source 表
CREATE TABLE kafka_in (
`env` STRING comment '游戏环境 hdf /qc/cbt/obt/prod',
`host` STRING comment '日志所在游戏服务器',
`tags` STRING comment '日志标签 normal | fix',
`log` STRING comment '日志所在文件及偏移量',
`topic` STRING METADATA VIRTUAL comment 'kafka的topic',
`partition_id` BIGINT METADATA FROM 'partition' VIRTUAL comment '日志所在的kafka分区',
`offset` BIGINT METADATA VIRTUAL comment 'kafka分区的偏移量',
`uuid` STRING comment 'filebeat生成的uuid',
`message` STRING comment 'tlog信息',
`@timestamp` STRING comment 'filebeat采集时间',
`ts` TIMESTAMP(3) METADATA FROM 'timestamp' comment 'kafka存储消息时间'
) WITH (
'connector' = 'kafka',
'topic' = 'ro_sea_tlog',
'properties.bootstrap.servers' = 'sea-kafka-01:9092,sea-kafka-02:9092,sea-kafka-03:9092',
'properties.group.id' = 'streamx-ro-sea-total',
'properties.client.id' = 'streamx-ro-sea-total',
'properties.session.timeout.ms' = '60000',
'properties.request.timeout.ms' = '60000',
'scan.startup.mode' = 'group-offsets',
--'scan.startup.mode' = 'earliest-offset',\
'properties.fetch.max.bytes' = '123886080',
'properties.max.partition.fetch.bytes' = '50388608',
'properties.fetch.max.wait.ms' = '2000',
'properties.max.poll.records' = '1000',
'format' = 'json',
'json.ignore-parse-errors' = 'false'
);
--创建emr 的kafka 正式表
CREATE TABLE kafka_out_sea (
`env` STRING comment '游戏环境 qc/cbt/obt/prod',
`hostname` STRING comment '日志所在游戏服务器',
`tags` STRING comment '日志标签 normal | fix',
`log_offset` STRING comment '日志所在文件及偏移量',
`uuid` STRING comment 'filebeat生成的uuid',
`topic` STRING comment 'kafka的topic',
`partition_id` BIGINT comment '日志所在的kafka分区',
`kafka_offset` BIGINT comment 'kafka分区的偏移量',
eventname string comment '事件名',
`message` STRING comment 'tlog信息',
`filebeat_ts` STRING comment 'filebeat采集时间',
`kafka_ts` TIMESTAMP(3) comment 'kafka存储消息时间',
`flink_ts` TIMESTAMP(3) comment 'flink处理的消息时间'
) WITH (
'connector' = 'kafka',
'topic' = 'ro_sea_tlog',
--'properties.client.id' = 'flinkx-ro-sea-prod-v2',
'properties.bootstrap.servers' = 'emr_kafka1:9092,emr_kafka2:9092,emr_kafka3:9092',
'format' = 'json',
--'sink.partitioner'= 'fixed',
'sink.delivery-guarantee' = 'exactly-once',
'sink.transactional-id-prefix' = 'ro_sea_kafka_sync_v10',
'properties.compression.type' = 'zstd',
'properties.transaction.timeout.ms' = '600000',
'properties.message.max.bytes' = '13000000',
'properties.max.request.size' = '13048576',
--'properties.buffer.memory' = '83554432',
'properties.acks' = '-1'
);
--etl 创建目标视图
create view kafka_sea_in_view as
select `env`,JSON_VALUE(`host`,'$.name') as hostname,`tags`,`log` as log_offset,`uuid`,
`topic`,`partition_id`,`offset` as kafka_offset,
lower(SPLIT_INDEX(message,'|',0)) as eventname,`message`,
CONVERT_TZ(REPLACE(REPLACE(`@timestamp`,'T',' '),'Z',''), 'UTC', 'Asia/Bangkok') as filebeat_ts, `ts` as kafka_ts ,CURRENT_TIMESTAMP as flink_ts
from kafka_in;
--写数据到emr sea topic
insert into kafka_out_sea
select * from kafka_sea_in_view ;
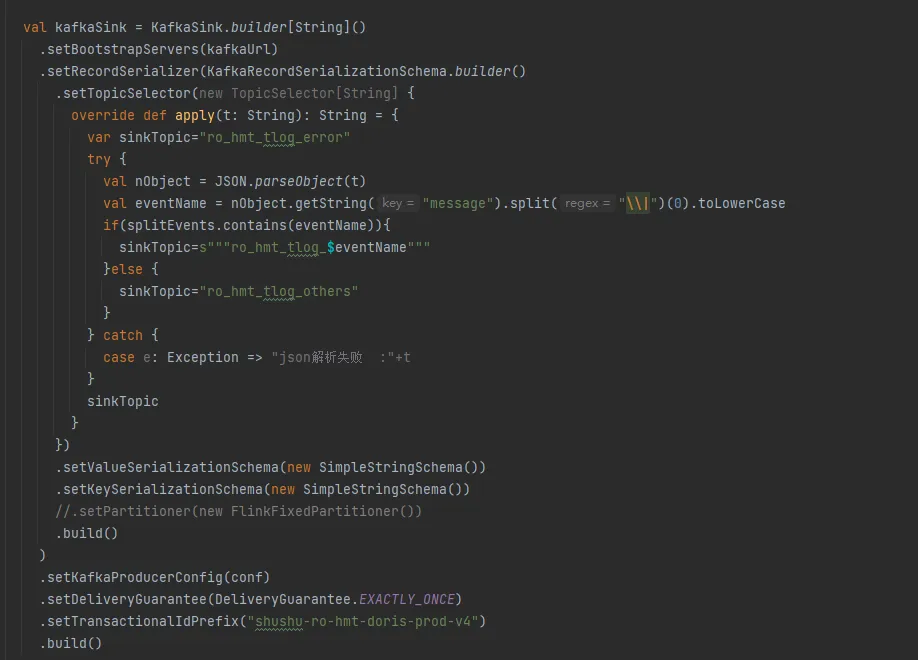
【实时数仓】:分流 Jar 程序和 ods -> dwd sql 加工函数,部分代码截图如下:
以及相关的 Flink sql:
--2 dwd_moneyflow_log
CREATE TABLE kafka_in_money (
`env` STRING comment '游戏环境 qc/cbt/obt/prod',
`hostname` STRING comment '日志所在游戏服务器',
`uuid` STRING comment '日志唯一id',
`message` STRING comment 'tlog信息',
`filebeat_ts` STRING comment 'filebeat采集时间'
) WITH (
'connector' = 'kafka',
'topic' = 'ro_sea_tlog_split_moneyflow',
'properties.bootstrap.servers' = 'emr_kafka1:9092,emr_kafka2:9092,emr_kafka3:9092',
'properties.group.id' = 'flinksql_kafka_in_moneyflow_v2',
'scan.startup.mode' = 'group-offsets',
--'scan.startup.mode' = 'earliest-offset',
'properties.isolation.level' = 'read_committed',
'format' = 'json',
'json.ignore-parse-errors' = 'false'
);
CREATE TABLE kafka_out_money(
`date` string not NULL COMMENT '日期',
`vroleid` int NULL COMMENT '角色ID',
`moneytype` int NULL COMMENT '货币类型',
`env` string NULL COMMENT '游戏环境 hdf /qc/cbt/obt/prod',
`hostname` string NULL COMMENT '日志所在游戏服务器',
`uuid` string NULL COMMENT 'filebeat 采集生成的uuid',
`filebeat_ts` string NULL COMMENT 'filebeat采集时间',
flink_ts string NULL COMMENT 'flink写入的消息时间',
`gamesvrid` int NULL COMMENT '登录游戏服务器编号',
`dteventtime` string NULL COMMENT '游戏事件的时间, 格式 YYYY-MM-DD HH:MM:SS',
`vgameappid` string NULL COMMENT '游戏APPID',
`platid` int NULL COMMENT 'ios 0 /android 1',
`izoneareaid` int NULL COMMENT '针对分区分服的游戏填写分区id,用来唯一标示一个区;非分区分服游戏请填写0',
`vopenid` string NULL COMMENT '用户OPENID号',
`vrolename` string NULL COMMENT '角色姓名',
`jobid` int NULL COMMENT '角色职业 0=巫师 1=……',
`gender` int NULL COMMENT '角色性别 0=男 1=女',
`ilevel` int NULL COMMENT '角色基础等级',
`ijoblevel` int NULL COMMENT '角色职业等级',
`playerfriendsnum` int NULL COMMENT '玩家好友数量',
`chargegold` int NULL COMMENT '角色充值经历(累计充值)',
`iviplevel` int NULL COMMENT '角色VIP等级',
`createtime` string NULL COMMENT '账号创建时间',
`irolece` int NULL COMMENT '战力/评分',
`unionid` int NULL COMMENT '公会ID',
`unionname` string NULL COMMENT '公会名称',
`regchannel` int NULL COMMENT '注册渠道',
`loginchannel` int NULL COMMENT '登录渠道',
`sequence` int NULL COMMENT '用于关联一次动作产生多条不同类型的货币流动日志',
`reason` int NULL COMMENT '行为(货币流动一级原因)',
`subreason` int NULL COMMENT '流向(物品流向定义)',
`imoney` int NULL COMMENT '货币变更数量',
`aftermoney` int NULL COMMENT '动作后的金钱数',
`afterboundmoney` int NULL COMMENT '动作后的绑定金钱数',
`addorreduce` int NULL COMMENT '增加或减少: 0是增加; 1是减少',
`serialnum` string NULL COMMENT '流水号',
`sourceid` int NULL COMMENT '渠道号',
`cmd` string NULL COMMENT '命令字',
`orderid` string NULL COMMENT '订单id(包含喵果增加和喵果减少,也包含现金充值订单id)',
`imoneytype` int NULL COMMENT '货币类型2',
`distincid` string NULL COMMENT '访客ID',
`deviceuid` string NULL COMMENT '设备ID',
`guildjob` int NULL COMMENT '公会职位',
`regtime` string NULL COMMENT '账号注册时间'
) WITH (
'connector' = 'doris',
'jdbc-url'='jdbc:mysql://xxx:9030,xxx:9030,xxx:9030',
'load-url'='xx:8030;xxx:8030;xxx:8030',
'database-name' = 'ro_sea',
'table-name' = 'dwd_moneyflow_log',
'username' = 'root',
'password' = 'root123',
'sink.semantic' = 'exactly-once'
);
create view kafka_out_money_view1 as
select IF(to_date(SPLIT_INDEX(message,'|',2)) > CURRENT_DATE + interval '1' day,CURRENT_DATE,to_date(SPLIT_INDEX(message,'|',2))) as `date`,
`env`,`hostname` as hostname,`uuid`,
try_cast(SPLIT_INDEX(message,'|',1) as int) as gamesvrid ,
SPLIT_INDEX(message,'|',2) as dteventtime ,
SPLIT_INDEX(message,'|',3) as vgameappid ,
try_cast(SPLIT_INDEX(message,'|',4) as int) as platid ,
try_cast(SPLIT_INDEX(message,'|',5) as int) as izoneareaid ,
SPLIT_INDEX(message,'|',6) as vopenid ,
try_cast(SPLIT_INDEX(message,'|',7) as int) as vroleid ,
SPLIT_INDEX(message,'|',8) as vrolename ,
try_cast(SPLIT_INDEX(message,'|',9) as int) as jobid ,
try_cast(SPLIT_INDEX(message,'|',10) as int) as gender ,
try_cast(SPLIT_INDEX(message,'|',11) as int) as ilevel ,
try_cast(SPLIT_INDEX(message,'|',12) as int) as ijoblevel ,
try_cast(SPLIT_INDEX(message,'|',13) as int) as playerfriendsnum ,
try_cast(SPLIT_INDEX(message,'|',14) as int) as chargegold ,
try_cast(SPLIT_INDEX(message,'|',15) as int) as iviplevel ,
SPLIT_INDEX(message,'|',16) as createtime ,
try_cast(SPLIT_INDEX(message,'|',17) as int) as irolece ,
try_cast(SPLIT_INDEX(message,'|',18) as int) as unionid ,
SPLIT_INDEX(message,'|',19) as unionname ,
try_cast(SPLIT_INDEX(message,'|',20) as int) as regchannel ,
try_cast(SPLIT_INDEX(message,'|',21) as int) as loginchannel ,
try_cast(SPLIT_INDEX(message,'|',22) as int) as `sequence` ,
try_cast(SPLIT_INDEX(message,'|',23) as int) as `reason` ,
try_cast(SPLIT_INDEX(message,'|',24) as int) as subreason ,
try_cast(SPLIT_INDEX(message,'|',25) as int) as moneytype ,
try_cast(SPLIT_INDEX(message,'|',26) as int) as imoney ,
try_cast(SPLIT_INDEX(message,'|',27) as int) as aftermoney ,
try_cast(SPLIT_INDEX(message,'|',28) as int) as afterboundmoney ,
try_cast(SPLIT_INDEX(message,'|',29) as int) as addorreduce ,
SPLIT_INDEX(message,'|',30) as serialnum ,
try_cast(SPLIT_INDEX(message,'|',31) as int) as sourceid ,
SPLIT_INDEX(message,'|',32) as `cmd` ,
SPLIT_INDEX(message,'|',33) as orderid ,
try_cast(SPLIT_INDEX(message,'|',34) as int) as imoneytype ,
SPLIT_INDEX(message,'|',35) as distincid ,
SPLIT_INDEX(message,'|',36) as deviceuid ,
try_cast(SPLIT_INDEX(message,'|',37) as int) as guildjob ,
SPLIT_INDEX(message,'|',38) as regtime ,
filebeat_ts,CURRENT_TIMESTAMP as flink_ts
from kafka_in_money;
insert into kafka_out_money
select
cast(`date` as varchar) as `date`,
`vroleid`,
`moneytype`,
`env`,
`hostname`,
`uuid`,
`filebeat_ts`,
cast(`flink_ts` as varchar) as flink_ts,
`gamesvrid`,
`dteventtime`,
`vgameappid`,
`platid`,
`izoneareaid`,
`vopenid`,
`vrolename`,
`jobid`,
`gender`,
`ilevel`,
`ijoblevel`,
`playerfriendsnum`,
`chargegold`,
`iviplevel`,
`createtime`,
`irolece`,
`unionid`,
`unionname`,
`regchannel`,
`loginchannel`,
`sequence`,
`reason`,
`subreason`,
`imoney`,
`aftermoney`,
`afterboundmoney`,
`addorreduce`,
`serialnum`,
`sourceid`,
`cmd`,
`orderid`,
`imoneytype`,
`distincid`,
`deviceuid`,
`guildjob`,
`regtime`
from kafka_out_money_view1;
【广告系统】:使用 Flink SQL 将一行日志数据进行切分解析出各个字段的数据并完成业务计算:
CREATE TABLE IF NOT EXISTS ods_adjust_in (
log STRING
) WITH (
'connector' = 'kafka',
'topic' = 'ad_adjust_callback',
'properties.bootstrap.servers' = 'emr_kafka1:9092,emr_kafka2:9092,emr_kafka3:9092',
'properties.group.id' = 'ods_adjust_etl_20231011',
'properties.max.partition.fetch.bytes' = '4048576',
'scan.startup.mode' = 'group-offsets',
'properties.isolation.level' = 'read_committed',
'format' = 'raw'
);
CREATE TABLE IF NOT EXISTS ods_af_in (
log STRING
) WITH (
'connector' = 'kafka',
'topic' = 'ad_af_callback',
'properties.bootstrap.servers' = 'emr_kafka1:9092,emr_kafka2:9092,emr_kafka3:9092',
'properties.max.partition.fetch.bytes' = '4048576',
'properties.group.id' = 'ods_af_etl_20231011',
'scan.startup.mode' = 'group-offsets',
'properties.isolation.level' = 'read_committed',
'format' = 'raw'
);
CREATE TABLE IF NOT EXISTS ods_mmp_out (
`date` DATE,
`mmp_type` STRING,
`app_id` STRING,
`event_name` STRING,
`event_time` TIMESTAMP(3),
`mmp_id` STRING,
`distinct_id` STRING,
`open_id` STRING,
`account_id` STRING,
`os_name` STRING, -- platform
`country_code` STRING,
`install_time` TIMESTAMP(3),
`bundle_id` STRING,
`media` STRING,
`channel` STRING,
`campaign` STRING,
`campaign_id` STRING,
`adgroup` STRING,
`adgroup_id` STRING,
`ad` STRING,
`ad_id` STRING,
`flink_ts` TIMESTAMP(3) comment 'flink处理的消息时间',
`device_properties` STRING,
`log` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'ods_mmp_log',
'properties.bootstrap.servers' = 'emr_kafka1:9092,emr_kafka2:9092,emr_kafka3:9092',
'scan.topic-partition-discovery.interval'='60000',
'properties.group.id' = 'mmp2etl-out',
'format' = 'json'
);
INSERT INTO ods_mmp_out
SELECT
`date`
,'Adjust' as `mmp_type`
,`app_token` as `app_id`
,`event_name`
,`event_time`
,`adid` as `mmp_id`
,`distinct_id`
,`open_id`
,`account_id`
,`os_name`
,`country_code`
,`install_time`
,'' as `bundle_id`
,'' as `media`
,`network` as `channel`
,`campaign`
,REGEXP_EXTRACT(`campaign`, '([\\(=])([a-z0-9]+)', 2) as `campaign_id`
,`adgroup`
,REGEXP_EXTRACT(`adgroup`, '([\\(=])([a-z0-9]+)', 2) as `adgroup_id`
,`creative` as `ad`
,REGEXP_EXTRACT(`creative`, '([\\(=])([a-z0-9]+)', 2) as `ad_id`
,`flink_ts`
,`device_properties`
,`log`
FROM (
SELECT
to_date(FROM_UNIXTIME(cast(JSON_VALUE(log,'$.created_at') as bigint))) as `date`
,JSON_VALUE(log,'$.app_token') as `app_token`
,JSON_VALUE(log,'$.adid') as `adid`
,LOWER(REPLACE( TRIM( COALESCE(JSON_VALUE(log,'$.event_name'), JSON_VALUE(log,'$.activity_kind')) ), ' ', '_')) as `event_name`
,TO_TIMESTAMP(FROM_UNIXTIME(cast(JSON_VALUE(log,'$.created_at') as bigint))) as `event_time`
,TO_TIMESTAMP(FROM_UNIXTIME(cast(JSON_VALUE(log,'$.installed_at') as bigint))) as `install_time`
,LOWER(CASE WHEN (JSON_VALUE(log,'$.network_name') = 'Unattributed') THEN COALESCE(JSON_VALUE(log,'$.fb_install_referrer_publisher_platform'),'facebook') ELSE JSON_VALUE(log,'$.network_name') END) AS `network`
,LOWER(CASE WHEN (JSON_VALUE(log,'$.network_name') = 'Unattributed') THEN (concat(JSON_VALUE(log,'$.fb_install_referrer_campaign_group_name'), '(', JSON_VALUE(log,'$.fb_install_referrer_campaign_group_id'), ')')) ELSE JSON_VALUE(log,'$.campaign_name') END) AS `campaign`
,LOWER(CASE WHEN (JSON_VALUE(log,'$.network_name') = 'Unattributed') THEN (concat(JSON_VALUE(log,'$.fb_install_referrer_campaign_name'), '(', JSON_VALUE(log,'$.fb_install_referrer_campaign_id'), ')')) ELSE JSON_VALUE(log,'$.adgroup_name') END) AS `adgroup`
,LOWER(CASE WHEN (JSON_VALUE(log,'$.network_name') = 'Unattributed') THEN (concat(JSON_VALUE(log,'$.fb_install_referrer_adgroup_name'), '(', JSON_VALUE(log,'$.fb_install_referrer_adgroup_id'), ')')) ELSE JSON_VALUE(log,'$.creative_name') END) AS `creative`
,JSON_VALUE(log,'$.os_name') as `os_name`
,JSON_VALUE(log,'$.country_code') as `country_code`
,JSON_VALUE(JSON_VALUE(log,'$.publisher_parameters'), '$.ta_distinct_id') as `distinct_id`
,JSON_VALUE(JSON_VALUE(log,'$.publisher_parameters'), '$.open_id') as `open_id`
,JSON_VALUE(JSON_VALUE(log,'$.publisher_parameters'), '$.ta_account_id') as `account_id`
,CURRENT_TIMESTAMP as `flink_ts`
,JSON_OBJECT(
'ip' VALUE JSON_VALUE(log,'$.ip')
,'ua' VALUE JSON_VALUE(log,'$.ua')
,'idfa' VALUE JSON_VALUE(log,'$.idfa')
,'idfv' VALUE JSON_VALUE(log,'$.idfv')
,'gps_adid' VALUE JSON_VALUE(log,'$.gps_adid')
,'android_id' VALUE JSON_VALUE(log,'$.android_id')
,'mac_md5' VALUE JSON_VALUE(log,'$.mac_md5')
,'oaid' VALUE JSON_VALUE(log,'$.oaid')
,'gclid' VALUE JSON_VALUE(log,'$.gclid')
,'gbraid' VALUE JSON_VALUE(log,'$.gbraid')
,'dcp_wbraid' VALUE JSON_VALUE(log,'$.dcp_wbraid')
) as `device_properties`
,`log`
FROM ods_adjust_in
WHERE COALESCE(JSON_VALUE(log,'$.activity_kind'), JSON_VALUE(log,'$.event_name')) not in ('impression', 'click')
)
UNION ALL
SELECT
to_date(CONVERT_TZ(JSON_VALUE(log,'$.event_time'), 'UTC', 'Asia/Shanghai')) as `date`
,'AppsFlyer' as `mmp_type`
,JSON_VALUE(log,'$.app_id') as `app_id`
,LOWER(REPLACE( TRIM(JSON_VALUE(log,'$.event_name') ), ' ', '-')) as `event_name`
,TO_TIMESTAMP(CONVERT_TZ(JSON_VALUE(log,'$.event_time'), 'UTC', 'Asia/Shanghai')) as `event_time`
,JSON_VALUE(log,'$.appsflyer_id') as `mmp_id`
,JSON_VALUE(JSON_VALUE(log,'$.custom_data'), '$.ta_distinct_id') as `distinct_id`
,JSON_VALUE(JSON_VALUE(log,'$.custom_data'), '$.open_id') as `open_id`
,JSON_VALUE(JSON_VALUE(log,'$.custom_data'), '$.ta_account_id') as `account_id`
,LOWER(JSON_VALUE(log,'$.platform')) AS `os_name`
,LOWER(JSON_VALUE(log,'$.country_code')) as `country_code`
,TO_TIMESTAMP(CONVERT_TZ(JSON_VALUE(log,'$.install_time'), 'UTC', 'Asia/Shanghai')) as `install_time`
,LOWER(JSON_VALUE(log,'$.bundle_id')) AS `bundle_id`
,LOWER(JSON_VALUE(log,'$.media_source')) AS `media`
,LOWER(JSON_VALUE(log,'$.af_channel')) AS `channel`
,CONCAT(LOWER(JSON_VALUE(log,'$.campaign')), ' (', LOWER(JSON_VALUE(log,'$.af_c_id')), ')') AS `campaign`
,LOWER(JSON_VALUE(log,'$.af_c_id')) AS `campaign_id`
,CONCAT(LOWER(JSON_VALUE(log,'$.af_adset')), ' (', LOWER(JSON_VALUE(log,'$.af_adset_id')), ')') AS `adgroup`
,LOWER(JSON_VALUE(log,'$.af_adset_id')) AS `adgroup_id`
,CONCAT(LOWER(JSON_VALUE(log,'$.af_ad')), ' (', LOWER(JSON_VALUE(log,'$.af_ad_id')), ')') AS `ad`
,LOWER(JSON_VALUE(log,'$.af_ad_id')) AS `ad_id`
,CURRENT_TIMESTAMP as `flink_ts`
,JSON_OBJECT(
'ip' VALUE JSON_VALUE(log,'$.ip')
,'ua' VALUE JSON_VALUE(log,'$.user_agent')
,'idfa' VALUE JSON_VALUE(log,'$.idfa')
,'idfv' VALUE JSON_VALUE(log,'$.idfv')
,'gps_adid' VALUE JSON_VALUE(log,'$.advertising_id')
,'android_id' VALUE JSON_VALUE(log,'$.android_id')
,'oaid' VALUE JSON_VALUE(log,'$.oaid')
) as `device_properties`
,`log`
FROM ods_af_in;
数据上报:类似于神策
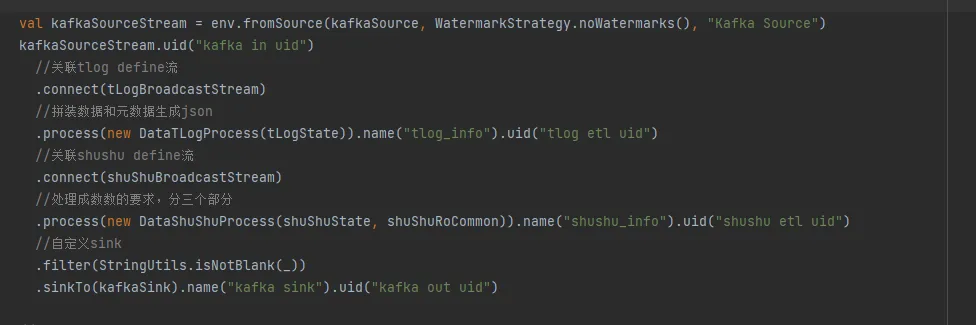
6. 落地实践 - 腾讯云环境篇
本文的 Flink 任务是运行在腾讯的 kubernetes 环境,其中包括一些相关的知识点,这里就不再详述了,例如:
-
镜像同步:harbor 配置自动同步镜像到腾讯云镜像服务 TCR 中。
-
镜像配置:如免密拉取、缓存加速。
-
Flink webui 外网访问:需要从外网lb购买以便于访问 Flink UI。
-
环境打通:因为 kubernetes 集群主要是一个偏封闭的内网计算环境、与各系统网络、安全组、权限、路由等都需要很好的配置和测试,才能让任务真正比较好��的跑在该生产环境。
-
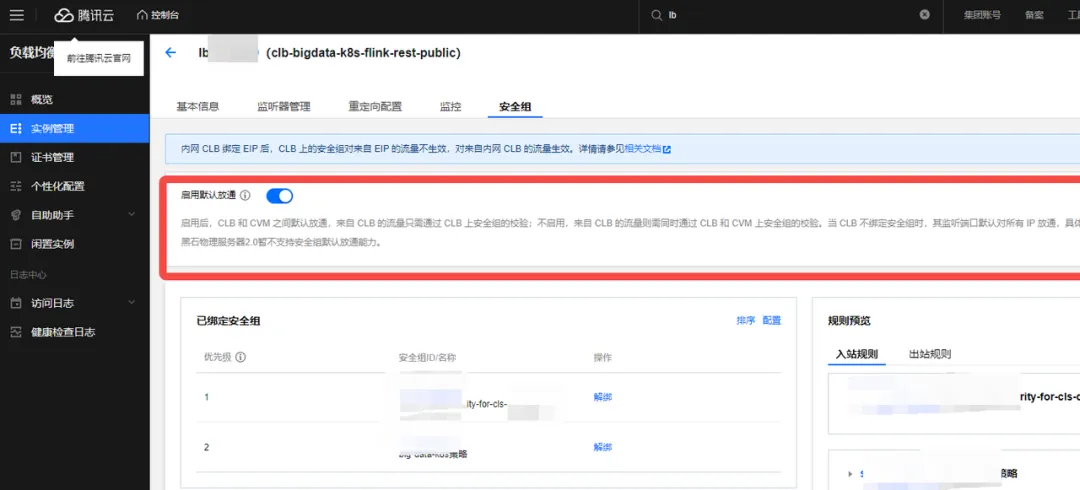
安全组配置:为了实现海外游戏实时数据的拉取处理和写入国内 Kafka 集群,确保数据流程的平稳,我们使用专线并且通过给 kubernetes Flink超级节点开通专线外网访问权来实现。
相关截图:
7. 收益与期望
使用 Apache StreamPark 之后,给我们最大的感受就是 StreamPark 用起来十分地简单,通过简单的配置就能很快地把 Flink 任务部署到任意的集群,且可以实时的去监控并管理成千上万的作业,十分的 nice!收益如下:
-
大量的实时任务通过 StreamPark 很快速地就迁移到了 Kubernetes,下掉 YARN 后,早期混部的 Apache Doris 集群没有资源争抢后,变得十分稳定。
-
补数据时,可快速借用 TKE 中超级节点的能力,通过 StreamPark 平台,很容易进行上千个 pod 的一分钟弹缩,补数特别高效。
-
技术栈变得更加先进和统一。大数据时代的一堆组件,变的越来越高效和统一。目前欢乐大数据已经完成了 Doris、Flink、Spark、Hive、Grafana、Prometheus 等一系列组件的 Kubernetes 云原生化,运维起来更加简单和高效,StreamPark 在 Flink 容器化进程中起到了很大的作用。
-
StreamPark 平台操作简单、功能完备、性能稳定、社区响应积极,真正让流处理作业开发越来越简单,为我们带来了很多便利,让我们更加专注于业务,点赞~
在这里,我们也期望 StreamPark 能做得越来越好,这里提出了一些优化的建议:
-
支持 Operator 部署:期望 Flink on kubernetes 支持 operator 部署方式,因为其可以自定义资源类型、指定调用顺序、监控指标等等好处。
-
支持 autoscaler:因为实时流任务有业务高峰和波谷、特别周么活动、数据量翻倍、人为周期性调整并行度不是很合适。故结合 Kubernetes、期待 StreamPark 早日完成 operator 方式创建 Flink 集群、在 Flink 1.17以上、就可以比较好的设置阈值、利用自动弹缩、实现高峰期弹更多资源处理数据、低谷期收缩资源节约成本、非常期待。
-
程序报错逻辑:当前 Flink 任务设置了固定次数或者比率重试,但当前 StreamPark 邮件告警特别频繁、不是期待的任务失败一次进行一次告警,故希望其进一步提升。
最后,我们衷心地感谢 Apache StreamPark 社区在我们使用 StreamPark 时提供的无私帮助。他们专业的服务精神和以用户为本的态度,使我们得以更加高效、流畅地运用这一强大框架。期望 StreamPark 越来越好,成为新晋 Apache 项目的典范!