**摘要:**本文「 StreamPark 一站式计算利器在海博科技的生产实践,助力智慧城市建设 」作者是海博科技大数据架构师王庆焕,主要内容为:
- 选择 StreamPark
- 快速上手
- 应用场景
- 功能扩展
- 未来期待
海博科技是一家行业领先的人工智能物联网产品和解决方案公司。目前在公共安全、智慧城市、智慧制造领域,为全国客户提供包括算法、软件和硬件产品在内的全栈式整体解决方案。
01. 选择 Apache StreamPark™
海博科技自 2020 年开始使用 Flink SQL 汇聚、处理各类实时物联数据。随着各地市智慧城市建设步伐的加快,需要汇聚的各类物联数据的数据种类、数据量也不断增加,导致线上维护的 Flink SQL 任务越来越多,一个专门的能够管理众多 Flink SQL 任务的计算平台成为了迫切的需求。
在体验对比了 Apache Zeppelin 和 StreamPark 之后,我们选择了 StreamPark 作为公司的实时计算平台。相比 Apache Zeppelin, StreamPark 并不出名。但是在体验了 StreamPark 发行的初版,阅读其设计文档后,我们发现其基于 一站式 设计的思想,能够覆盖 Flink 任务开发的全生命周期,使得配置、开发、部署、运维全部在一个平台即可完成。我们的开发、运维、测试的同学可以使用 StreamPark 协同工作,低代码 + 一站式 的设计思想坚定了我们使用 StreamPark 的信心。
//视频链接( StreamX 官方视频)
02. 落地实践
1. 快速上手
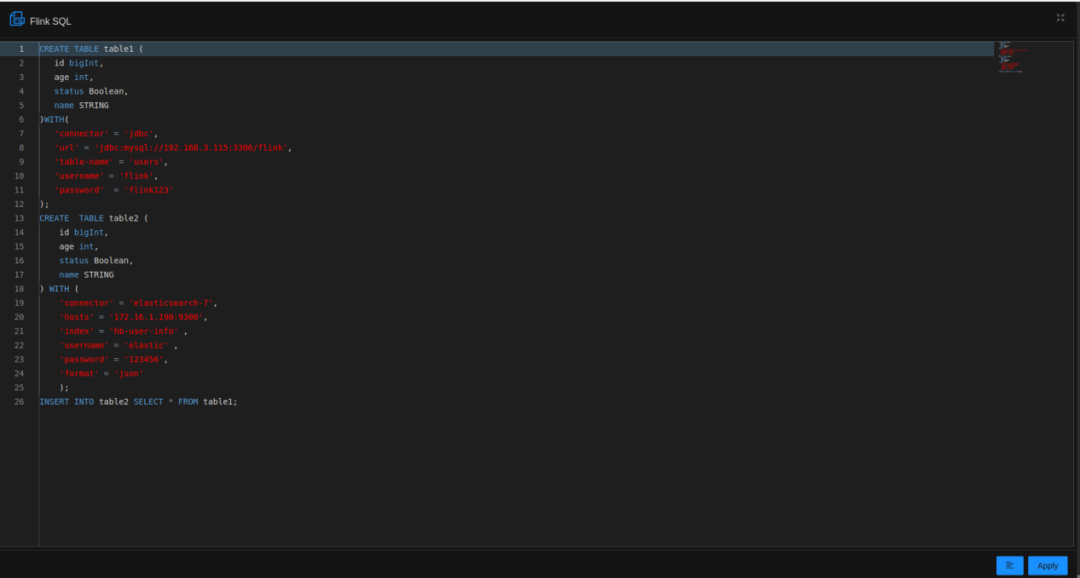
使用 StreamPark 完成一个实时汇聚任务就像把大象放进冰箱一样简单,仅需三步即可完成:
- 编辑 SQL
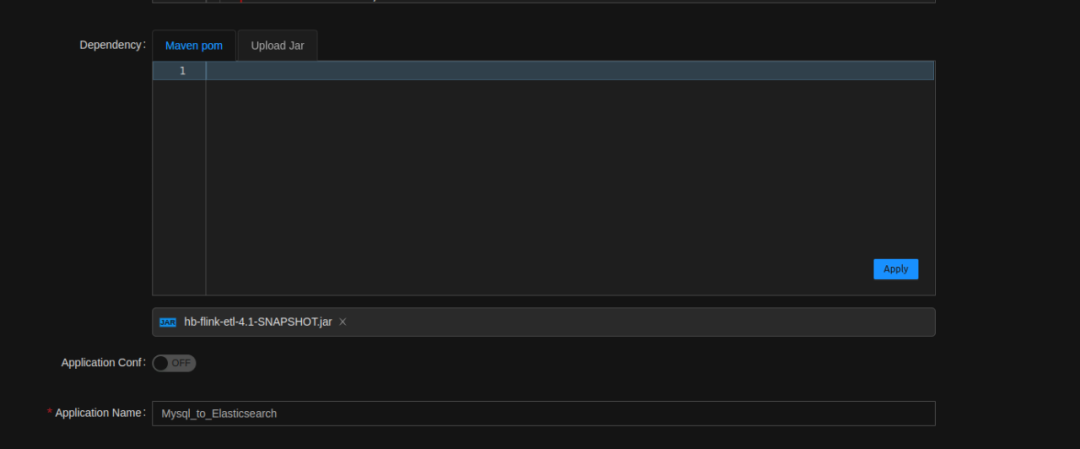
- 上传依赖包
- 部署运行
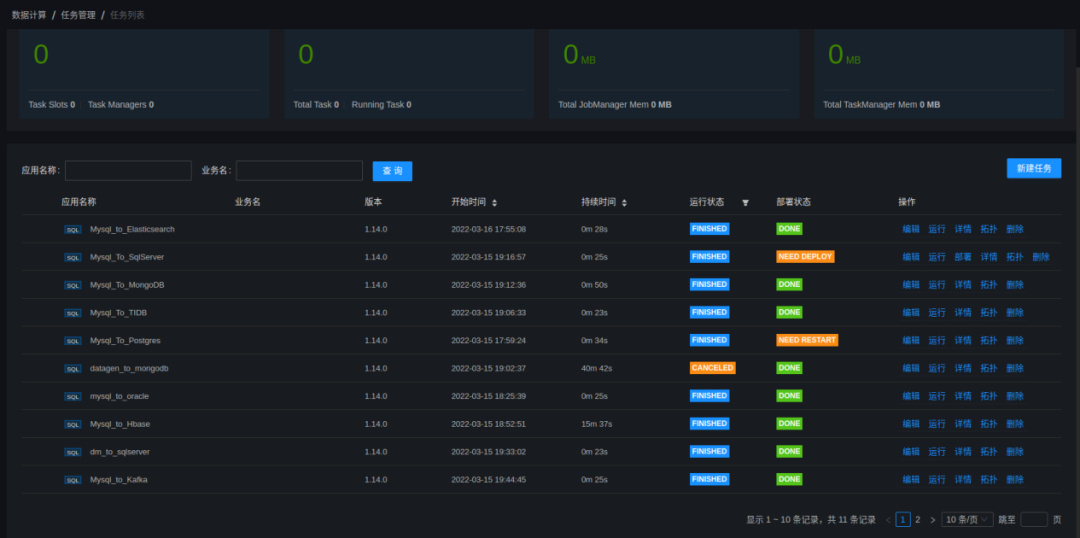
仅需上述三步,即可完成 Mysql 到 Elasticsearch 的汇聚任务,大大提升数据接入效率。
2. 生产实践
StreamPark 在海博主要用于运行实时 Flink SQL任务: 读取 Kafka 上的数据,进行处理输出至 Clickhouse 或者 Elasticsearch 中。
从2021年10月开始,公司逐渐将 Flink SQL 任务迁移至 StreamPark 平台来集中管理,承载我�司实时物联数据的汇聚、计算、预警。
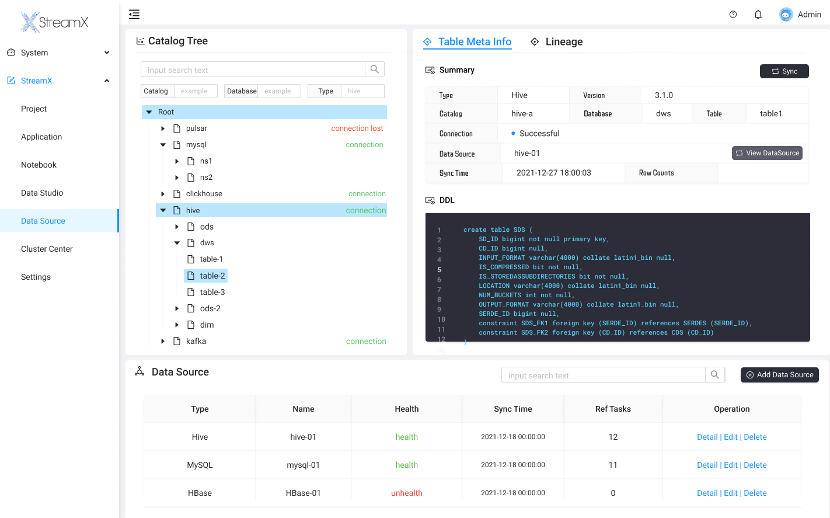
截至目前,StreamPark 已在多个政府、公安生产环境进行部署,汇聚处理城市实时物联数据、人车抓拍数据。以下是在某市专网部署的 StreamPark 平台截图 :
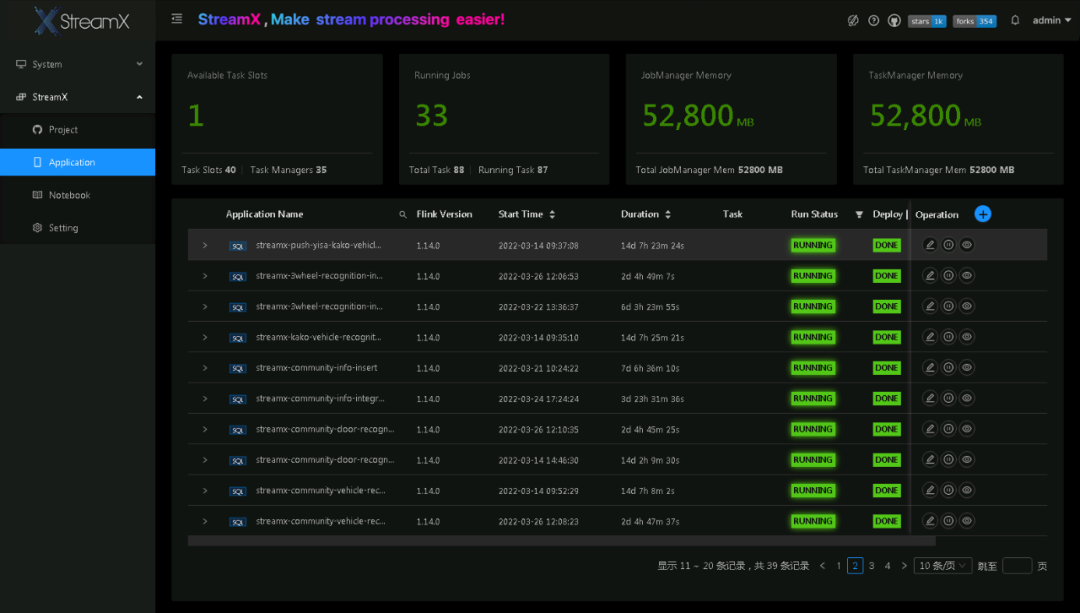
03. 应用场景
1. 实时物联感知数据汇聚
汇聚实时的物联感知数据,我们直接使用 StreamPark 开发 Flink SQL 任务,针对 Flink SQL 未提供的方法,StreamPark 也支持 Udf 相关功能,用户通过 StreamPark 上传 Udf 包,即可在 SQL 中调用相关 Udf,实现更多复杂的逻辑操作。
“SQL+UDF” 的方式,能够满足我们绝大部分的数据汇聚场景,如果后期业务变动,也只需要在 StreamPark 中修改 SQL 语句,即可完成业务变更与上线。

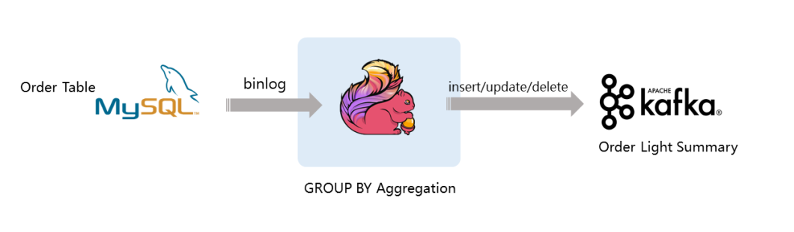
2. Flink CDC数据库同步
为了实现各类数据库与数据仓库之前的同步,我们使用 StreamPark 开发 Flink CDC SQL 任务。借助于 Flink CDC 的能力,实现了 Oracle 与 Oracle 之间的数据同步, Mysql/Postgresql 与 Clickhouse 之间的数据同步。
3. 数据分析模型管理
针对无法使用 Flink SQL 需要开发 Flink 代码的任务,例如: 实时布控模型、离线数据分析模型,StreamPark 提供了 Custom code 的方式,允许用户上传可执行的 Flink Jar 包并运行。
目前,我们已经将人员,车辆等 20 余类分析模型上传至 StreamPark,交由 StreamPark 管理运行。
综上: 无论是 Flink SQL 任务还是 Custome code 任务,StreamPark 均提供了很好的支持,满足各种不同的业务场景。 但是 StreamPark 缺少任务调度的能力,如果你需要定期调度任务, StreamPark 目前无法满足。社区成员正在努力开发调度相关的模块,在即将发布的 1.2.3 中 会支持任务调度功能,敬请期待。
04. 功能扩展
Datahub 是 Linkedin 开发的一个元数据管理平台,提供了数据源管理、数据血缘、数据质量检查等功能。海博科技基于 StreamPark 和 Datahub 进行了二次开发,实现了数据表级/字段级的血缘功能。通过数据血缘功能,帮助用户检查 Flink SQL 的字段血缘关系。�并将血缘关系保存至Linkedin/Datahub 元数据管理平台。
//两个视频链接(基于 StreamX 开发的数据血缘功能)
05. 未来期待
目前,StreamPark 社区的 Roadmap 显示 StreamPark 1.3.0 将迎来全新的 Workbench 体验、统一的资源管理中心 (JAR/UDF/Connectors 统一管理)、批量任务调度等功能。这也是我们非常期待的几个全新功能。
Workbench 将使用全新的工作台式的 SQL 开发风格,选择数据源即可生成 SQL,进一步提升 Flink 任务开发效率。统一的 UDF 资源中心将解决当前每个任务都要上传依赖包的问题。批量任务调度功能将解决当前 StreamPark 无法调度任务的遗憾。
下图是 StreamPark 开发者设计的原型图,敬请期待。