
导读:本文主要介绍天眼查在实时计算业务近千个 Flink 作业运维时面临作业开发和管理上的挑战,通过引入 Apache StreamPark 来解决这些挑战,介绍了在引入 StreamPark 落地过程中遇到的一些问题以及如何解决这些问题并成功落地,最后极大地降低运维成本,显著地提升人效。
Github: https://github.com/apache/streampark
欢迎关注、Star、Fork,参与贡献
供稿单位 | 北京天眼查
文章作者 | 李治霖
文章整理 | 杨林伟
内容校对 | 潘月鹏
天眼查是中国领先的商业查询平台。自 2014 年创立以来,天眼查持续保持高速增长,行业渗透率超过 77%,月活跃用户数高达 3500 万,累计用户数 6 亿+,“天眼一下”已成为商业领域的超级符号,是首批获得央行备案企业征信资质的公司之一。经过公司多年深耕,平台共收录全国 3.4 亿、全球 6.4 亿社会实体,1000 多种商查信息维度实时更新,成为企业客户和个人用户商业查询的首选品牌。

本文将介绍天眼查实时计算业务面临的挑战,如何通过 Apache StreamPark 平台来解决这些挑战,以及带来的显著效益和未来��规划。
业务背景与挑战
天眼查有着庞大的用户基础和多样的业务维度,我们通过 Apache Flink® 这一强大的实时计算引擎,为用户提供更优质的产品和服务体验,我们的实时计算业务主要涵盖以下几个场景:
-
实时数据 ETL 处理和数据传输。
-
C 端维度数据统计,包括用户行为、PV/UV 分析。
-
C 端业务数据与工商信息、风险信息、产权、股权、股东、案件等信息的实时关联分析。
随着天眼查业务的快速发展,实时作业目前已增至 800 +,未来很快会上千,面对这么大体量的作业、在开发和管理上都遇到了挑战,大致如下:
-
作业运维困难:作业覆盖多个 Flink 版本,多版本 Flink 作业的运行和升级因 API 变动而成本高昂,且作业提交和参数调优依赖于复杂脚本,极大增加了维护难度和成本。
-
作业开发低效:从本地 IDE 调试到测试环境部署,需经过编译、文件传输和命令执行等繁琐步骤,耗时且影响效率。
-
缺乏自动重试机制:实时业务的多表关联操作易受网络和 IO 波动影响,导致 Flink 程序故障,需手动或额外程序介入恢复,增加了开发和维护成本。
-
维护成本高昂:缺少集中化的日志、版本控制和配置管理工具,随着任务量上升,维护大量 JAR 包、提交脚本和 Flink 客户端配置变得日益复杂。

StreamPark 落地实践
为了解决上述问题,我司决定引入 StreamPark。我们在 StreamPark 项目刚开源的时候就开始关注,当时项目名还是 StreamX,此后也在一直密切关注着项目的发展,见证了其从开源到加入 Apache 软件基金会孵化的过程,其社区活跃度、用户口碑、发版次数等各项表现都很不错,有大量企业的真实使用案例,这增强了我们对 StreamPark 信心,因此引入 StreamPark 是自然而然的事情,我们尤其关注以下可以解决我们痛点的能力:
-
Git 式项目管理:为作业提供了便捷的版本控制和部署流程。
-
强大的作业运维能力:显著提升了作业的管理和维护效率。
-
精确的秒级告警系统:提供了实时监控和快速响应能力。
-
一站式任务开发平台:为开发、测试和部署提供有力保障
1. Git 式项目管理
天眼查 90% 以上都是 JAR 作业,管理几百个JAR 作业是很头疼的问题,为了方便维护和管理先前我们通过 “开发人员名称-项目名称-模块-环境” 进行命名 JAR 文件名,这样带来了另一个问题,没办法直观区分要维护的作业在那个模块,如果非 owner 维护此作业得通过项目文档和代码来查看逻辑,需要找到项目代码与对应分支、作业的启动脚本等,这样大幅度增加开发人员工作量。
在 StreamPark 中我们惊喜地发现有项目管理功能,类似于 Git 集成,可以很好的解决了我们的痛点,我们通过简化的命名规范,实现了项目、人员、分支和环境的隔离。现在,我们能够瞬间定位到任意作业的代码和文档,极大提高了作业的可维护性和开发效率,显著提升了我们的运维效率。
2. 秒级精确告警和自动运维
下面是我们一个 Flink 线上的任务,在查询过程中访问第三方端时,发生 Connection Time out 等错误(备注:本身 Flink 设置重启策略间隔重启三次,但最终还是失败)
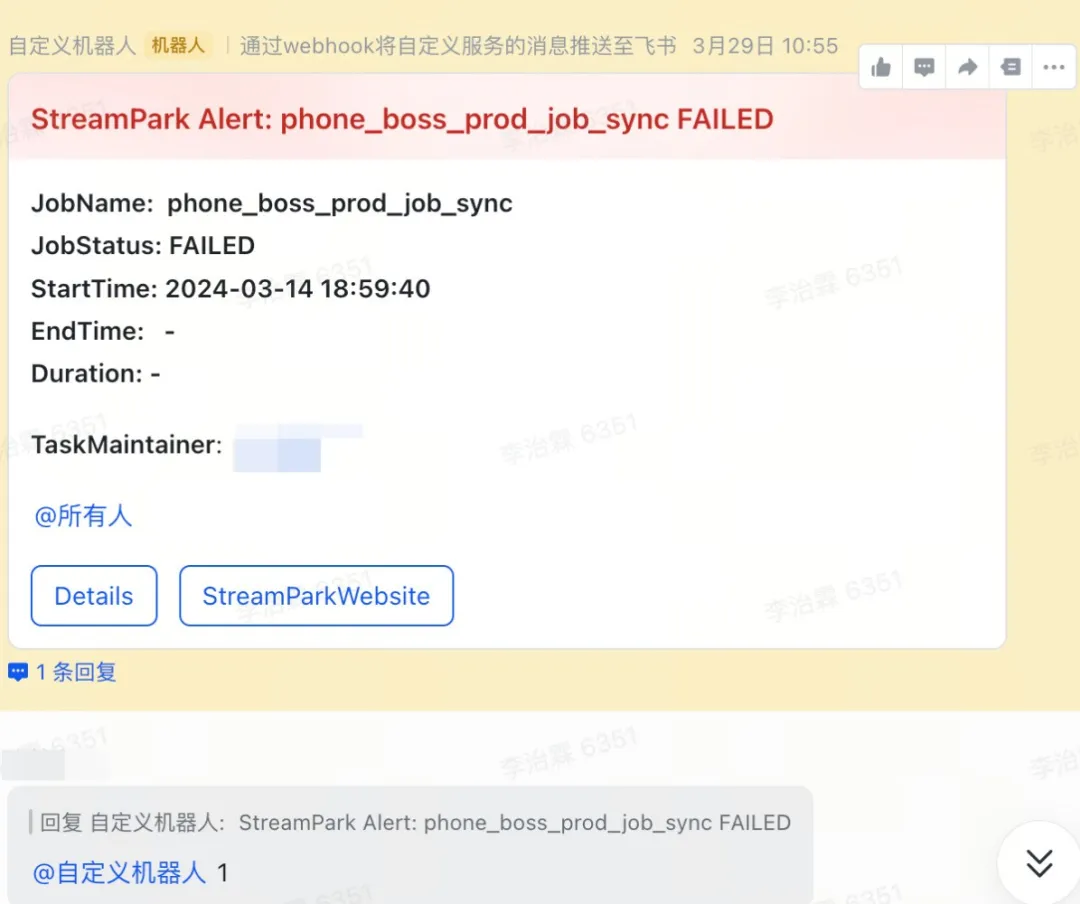
如上图,当收到任务告警时,我们开发同学在群里回复 1 的时候,我们发现作业已经成功被 StreamPark 拉起,只用不到 15 秒就完成了作业的重新提交和运行!
3. 平台用户权限管控
StreamPark 提供了一套完善的权限管理机制,使得我们可以在 StreamPark 平台上对作业和用户进行精细的权限管理,有效避免了因用户权限过大而可能发生的误操作,减少了对作业运行稳定性和环境配置准确性的影响,对于企业级用户来说,这样的管理机制是非常必要的。

4. Flink SQL 在线开发
对于许多开发场景中需要提交 Flink SQL 作业的情况,现在我们可以完全摆脱在 IDEA 中编写代码的繁琐步骤。只需使用 StreamPark 平台,就能轻松实现 Flink SQL 作业的开发,以下是一个简单的案例。

5. 完善的作业管理能力
StreamPark 还有更加完善的作业操作记录,对于一些提交时异常的作业,现可完全通过平台化查看失败日志,包括历史日志信息等。

当然,StreamPark 还��为我们提供了更加完善且友好的任务管理界面,可以直观地看到任务的运行情况。
我们企业内部实时项目是高度抽象化代码开发的作业,每次开发新作业只需要修改一些外部传入的参数即可,通过 StreamPark 复制作业功能让我们告别了很多重复性工作,只需要在平台上复制已有作业,略微修改程序运行参数就可以提交一个新的作业!

当然还有更多,这里就不一一列举了,StreamPark 在使用上足够的简单易用,分钟内即可上手使用,功能上足够的专注可靠,引入 StreamPark 以来解决了我们管理 Flink 作业面临的难题,带来了实实在在的方便,显著地提高了人效,给主创团队一个大大的赞!
遇到的问题
在 StreamPark 落地实践中,我们也遇到了一些问题,这里记录下来,期望给社区的用户带来一些输入和参考。
华为云与开源 Hadoop 存在兼容问题
我们的作业都是 Flink on Yarn 模式,部署在华为�云。在使用 StreamPark 部署作业的过程中发现作业可以成功部署到华为 Hadoop 集群,但是获取作业状态信息时请求 Yarn ResourceManager 被拒绝,我们及时和社区沟通,寻求解决方案,并且记录了 issue: https://github.com/apache/streampark/issues/3566
最后在社区 PMC 成员华杰老师和华为云同学的协助下,成功解决了问题:由于云产品本身内部的安全认证机制导致 StreamPark 无法正常访问云 ResourceManager。
解决方案 (仅供参考 - 根据不同环境添加不同依赖)
将 STREAMPARK_HOME/lib 目录中 HADOOP 相关两个包删除:
hadoop-client-api-3.3.4.jar
hadoop-client-runtime-3.3.4.jar
替换以下华为云 HADOOP 依赖:
commons-configuration2-2.1.1.jar
commons-lang-2.6.0.wso2v1.jar
hadoop-auth-3.1.1-hw-ei-xxx.jar
hadoop-common-3.1.1-hw-ei-xxx.jar
hadoop-hdfs-client-3.1.1-hw-ei-xxx.jar
hadoop-plugins-8.1.2-xxx.jar
hadoop-yarn-api-3.1.1-hw-ei-xxx.jar
hadoop-yarn-client-3.1.1-hw-ei-xxx.jar
hadoop-yarn-common-3.1.1-hw-ei-xxx.jar
httpcore5-h2-5.1.5.jar
jaeger-core-1.6.0.jar
mysql-connector-java-8.0.28.jar
opentracing-api-0.33.0.jar
opentracing-noop-0.33.0.jar
opentracing-util-0.33.0.jar
protobuf-java-2.5.0.jar
re2j-1.7.jar
stax2-api-4.2.1.jar
woodstox-core-5.0.3.jar
其他 BUG
在深入使用的过程中,我们也发现了一些问题。为了更好地改善与优化 StreamPark 的功能,我们提出了一些具体的建议和解决方案,例如:
-
依赖冲突:加载 Flink 依赖时出现冲突的解决(详见:Pull Request #3568)。
-
服务稳定性:拦截用户程序 JVM 退出,防止 StreamPark 平台因用户程序异常退出(详见:Pull Request #3659)。
-
资源优化:为减轻资源负担,限制 StremaPark 构建项目的并发数,通过配置参数来控制项目最大构建数量(详见:Pull Request #3696)。
带来的收益
Apache StreamPark 为我们带来了显著的收益,主要体现在其一站式服务能力,使得业务开发人员能够在一个统一的平台上完成 Flink 作业的开发、编译、提交和管理。极大地节省了我们在 Flink 作业开发和部署上的时间,显著地提升了开发效率,并实现了从用户权限管理到 Git 部署、任务提交、告警、自动恢复的全流程自动化,有效解决了 Apache Flink® 运维的复杂性。
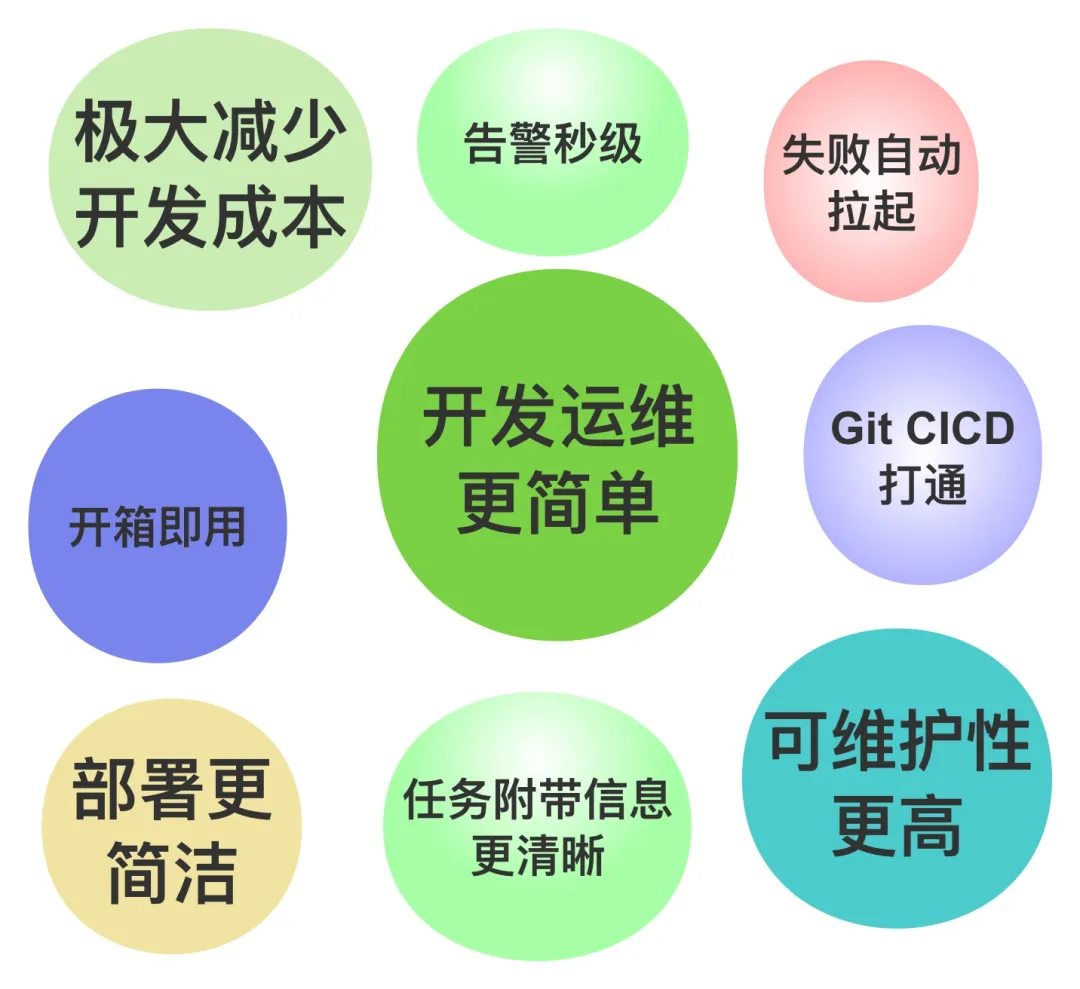
目前在天眼查平台,StreamPark 带来的具体成效包括:
-
实时作业上线和测试部署流程简化了 70% 。
-
实时作业的运维成本降低了 80%,开发人员可以更专注于代码逻辑 。
-
告警时效性提高了 5倍 以上,从分钟级降低到秒级,实现了 5秒内 感知并处理任务异常。
-
对于任务失败,StreamPark 能够自动恢复,无需人工干预。
-
通过 GitLab 与 StreamPark 的集成,简化了编译项目和作业提交流程,大幅降低了开发和维护成本。
未来规划
未来我们计划将内部自研实时计算平台上部署的 300+ Flink 作业和其他方式维护的 500+ Flink 作业全部迁移至 StreamPark 进行统一管理维护,后续遇到一些可优化或可增强功能点,我们会及时与社区开发人员沟通并回馈贡献社区,让 StreamPark 变得更易用、更好用。
在本文的最后,我们衷心感谢 Apache Streampark 社区,特别是 PMC 成员华杰老师,在我们使用 StreamPark 过程中持续地跟进,提供了宝贵的技术支持,我们深刻感受到 Apache StreamPark 社区认真的态度和热情。同时也非常感谢华为云同学在云部署上支持与问题排查。
我们期待未来与 StreamPark 社区继续合作,共同推动实时计算技术的发展,期望 StreamPark 在未来做得越来越好,早日毕业成为新晋 Apache 项目的代表!