
**导读:**本文主要介绍作为供应链物流服务商海程邦达在数字化转型过程中采用 Paimon + StreamPark 平台实现流式数仓的落地方案。我们以 Apache StreamPark 流批一体平台提供了一个易于上手的生产操作手册,以帮助用户提交 Flink 任务并迅速掌握 Paimon 的使用方法。
- 公司业务情况介绍
- 大数据技术痛点以及选型
- 生产实践
- 问题排查分析
- 未来规划
01 公司业务情况介绍
海程邦达集团一直专注于供应链物流领域,通过打造优秀的国际化物流平台,为客户提供端到端一站式智慧型供应链物流服务。集团现有员工 2000 余人,年营业额逾 120 亿人民币,网络遍及全球 200 余个港口,在海内外有超 80 家分、子公司,助力中国企业与世界互联互通。
业务背景
随着公司规模的不断扩大和业务复杂性的增加,为了��更好地实现资源优化和流程改进,公司运营与流程管理部需要实时监控公司的业务运转情况,以确保业务流程的稳定性和高效性。
公司运营与流程管理部负责监督公司各类业务流程的执行,包括海运、空运、铁运各个大区和事业部的订单量,大客户的订单量,航线订单量,关务、仓储、陆运各个操作站点的委托量,公司当天各个大区和事业部实际收入和支出情况等。通过对这些流程的监控和分析,公司能够识别出潜在的问题和瓶颈,提出改进措施和建议,以优化公司运营效率。
实时数仓架构:
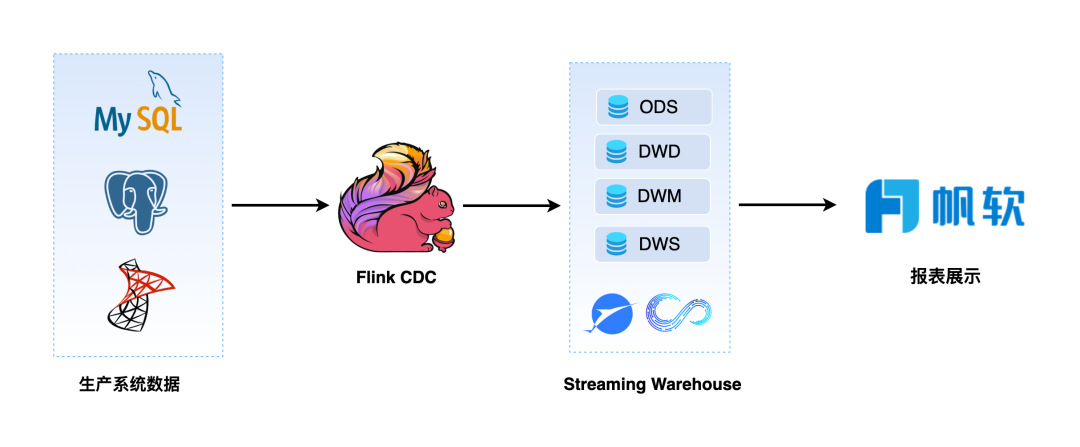
当前系统要求直接从生产系统收集实时数据,但存在多个数据源需要进行关联查询,而帆软报表在处理多个数据源时展示不够友好,且无法再次聚合多个数据源。定时查询生产系统会给生产系统数据库带来压力,影响生产系统的稳定运行。因此,我们需要引入一个可以通过 Flink CDC 技术实现流式处理的数仓,以解决实时数据处理的问题。这个数仓需要能够从多个数据源收集实时数据并在此基础上实现复杂的关联 SQL 查询、机器学习等操作,并且可以避免不定时查询生产系统,从而减轻生产系统的压力,保障生产系统的稳定运行。
02 大数据技术痛点以及选型
海程邦达大数据团队建立以来一直以高效运维工具或平台来实现对人员的高效配置,优化重复劳动,手工作业。
在离线批数处理已能够支持集团基础驾驶舱和管理报表的情况下,集团运管部门提出了业务要实时统计订单数量,操作单量的需求,财务部门有现金流实时展示的需求,在这样的背景下,基于大数据的流批一体方案势在必行。
虽然大数据部门已经使用了 Apache Doris 来实现湖仓一体的存储和计算,此前已在 Doris 社区发表湖仓一体建设的文章,但是有些问题有待解决,流式数据存储无法复用、中间层数据不可查、做不到实时聚合计算问题。
按照架构演进时间排序,近几年通用的架构解决方案如下:
hadoop架构
传统数仓和互联网数仓的分界点,在互联网早期的时候,大家对于数据分析的要求也不高,主要是做实时性不高的报表、支撑决策,对应的离线数据分析方案就产生了。
**优点:**数据类型支持丰富,支持海量运算,机器配置要求低,时效性低,容错
**缺点:**不支持实时;运维复杂;查询优化器不如 MPP,响应慢
选型依据:不支持实时;运维复杂,不符合人员精简配置原则;性能差
lambda架构
Lambda 架构是��由 Storm 的作者 Nathan Marz 提出的一个实时大数据处理框架。Marz 在 Twitter 工作期间开发了著名的实时大数据处理框架 Apache Storm ,Lambda 架构是其根据多年进行分布式大数据系统的经验总结提炼而成。
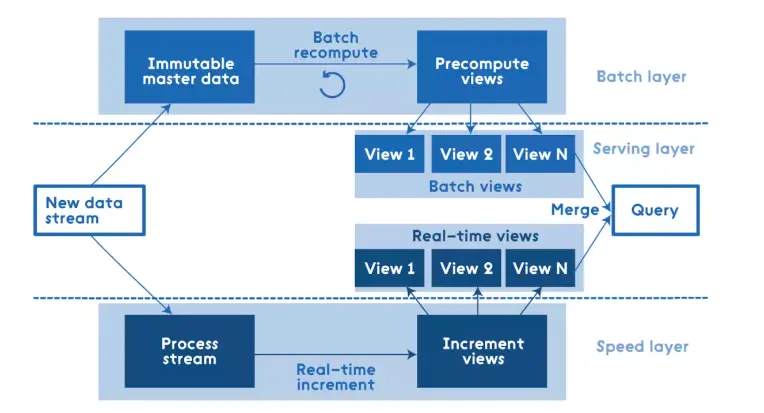
数据流处理分为 ServingLayer、SpeedLayer、BatchLayer 三层:
- Batch层: 对离线数据进行处理,最后提供 view 服务给到业务;
- Speed层: 对实时增量数据进行处理,最后提供 view 服务给到业务;
- Serving层: 响应用户的请求,实现离线和增量数据的聚合计算,并最终提供服务;
优点是:离线和实时分开计算,使用两套框架,架构稳定
缺点是:离线和实时数据很难保持一致性,运维人员需要维护两套框架三层架构,开发人员需要写三套代码
选型依据:数据一致性不可控;运维、开发工作量大,不符合人员精简配置的原则;
kappa架构
kappa 架构只用一套数据流处理架构来解决离线和实时数据,用实时流来解决所有问题,旨在提供快速可靠的查询访问结果。它非常适合各种数据处理工作负载,包括连续数据管道、实时数据处理、机器学习模型和实时数据分析、物联网系统以及许多其他具有单一技术堆栈的用例。
它通常使用流处理引擎实现,例如Apache Flink、Apache Storm、Apache Kinesis、 Apache Kafka,旨在处理大量数据流并提供快速可靠的查询访问结果。
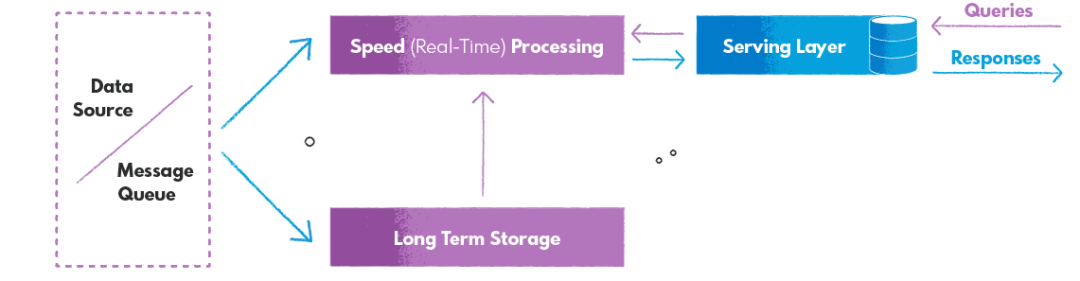
**优点是:**单数据流处理框架
**缺点是:**虽然它的架构相对 lamabda 架构简单,但是流式处理框架的设置和维护相对复杂,不具备真正意义上的离线数据处理能力;流平台中存储大数据成本高昂
选型依据:离线数据处理能力需要保留,控制成本
Iceberg
为此我们也调研了 Apache Iceberg ,它的快照功能一定程度上能够实现流批一体,但是它的问题是基于 kafka 做的实时表中间层不可查或者无法复用已经存在的表,对 kafka 有强依赖,需要利用 kafka 将中间结果写到 iceberg 表,增加了系统的复杂度和可维护性。
选型依据:无 kafka 实时架构已落地,中间数据无法实现可查可复用
流式数仓(kappa架构的延续)
海程邦达大数据团队自 FTS0.3.0 版本开始参与流式数仓建设,旨在进一步降低数据处理框架的复杂度和人员的精简配置,前期的宗旨是既然是趋势就要参与进来,过程中不断学习精进,向最前沿的技术靠拢,团队一致认为有坑就踩坑,摸着石头也要过河,好在经��过几个版本的迭代,在社区的高效配合下,最开始出现的问题也慢慢得以解决
流式数仓架构如下:
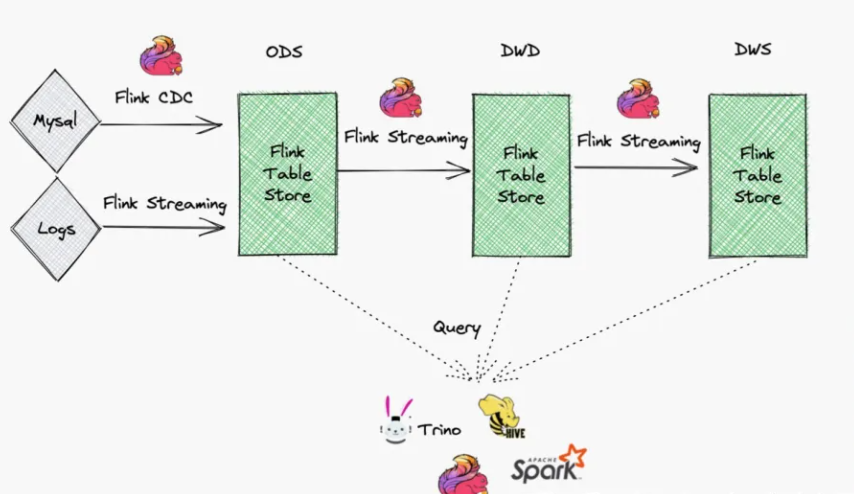
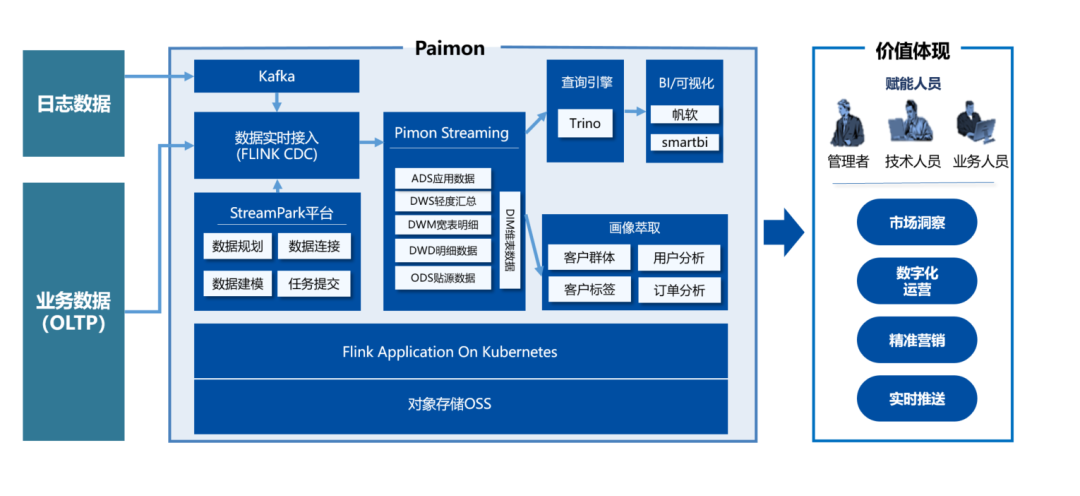
延续了 kappa 架构的特点,一套流处理架构,好处在与,底层 Paimon 的技术支撑使得数据在全链路可查,数仓分层架构得以复用,同时兼顾了离线和实时的处理能力,减少存储和计算的浪费
03 生 产 实 践
本方案采用 Flink Application On K8s 集群,Flink CDC 实时摄取业务系统关系型数据库数据,通过 StreamPark 任务平台提交 Flink + Paimon Streaming Data Warehouse 任务, 最后采用 Trino 引擎接入 Finereport 提供服务和开发人员的查询。Paimon 底层存储支持 S3 协议,因为公司大数据服务依赖于阿里云所以使用对象存储OSS作为数据文件系统。
StreamPark 是一个实时计算平台,与 Paimon 结合使用其强大功能来处理实时数据流。此平台提供以下主要功能:
**实时数据处理:**StreamPark 支持提交实时数据流任务,能够实时获取、转换、过滤和分析数据。这对于需要快速响应实时数据的应用非常重要,例如实时监控、实时推荐和实时风控等领域。
**可扩展性:**可以高效处理大规模实时数据,具备良好的可扩展性。可以在分布式计算环境中运行,并能够自��动处理并行化、故障恢复和负载均衡等问题,以确保高效且可靠地处理数据。
**Flink 集成:**基于 Apache Flink 构建,利用 Flink 的强大流处理引擎来实现高性能和鲁棒性。用户可以充分利用 Flink 的特性和生态系统,如广泛的连接器、状态管理和事件时间处理等。
**易用性:**提供了直观的图形界面和简化的 API,可以轻松地构建和部署数据处理任务,而无需深入了解底层技术细节。
通过在 StreamPark 平台上提交 Paimon 任务,我们可以建立一个全链路实时流动、可查询和分层可复用的 Pipline。
主要采用组件版本如下:
- flink-1.16.0-scala-2.12
- paimon-flink-1.16-0.4-20230424.001927-40.jar
- apache-streampark_2.12-2.0.0
- kubernetes v1.18.3
环境构建
下载 flink-1.16.0-scala-2.12.tar.gz 可以在 flink官网 下载对应版本的安装包到StreamPark 部署服务器
#解压
tar zxvf flink-1.16.0-scala-2.12.tar.gz
#修改 flink-conf 配置文件并启动集群
jobmanager.rpc.address: localhost
jobmanager.rpc.port: 6123
jobmanager.bind-host: localhost
jobmanager.memory.process.size: 4096m
taskmanager.bind-host: localhost
taskmanager.host: localhost
taskmanager.memory.process.size: 4096m
taskmanager.numberOfTaskSlots: 4
parallelism.default: 4
akka.ask.timeout: 100s
web.timeout: 1000000
#checkpoints&&savepoints
state.checkpoints.dir: file:///opt/flink/checkpoints
state.savepoints.dir: file:///opt/flink/savepoints
execution.checkpointing.interval: 2min
#当作业手动取消/暂停时,将会保留作业的 Checkpoint 状态信息
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
state.backend: rocksdb
#已完成的CP保存个数
state.checkpoints.num-retained: 2000
state.backend.incremental: true
execution.checkpointing.checkpoints-after-tasks-finish.enabled: true
#OSS
fs.oss.endpoint: oss-cn-zhangjiakou-internal.aliyuncs.com
fs.oss.accessKeyId: xxxxxxxxxxxxxxxxxxxxxxx
fs.oss.accessKeySecret: xxxxxxxxxxxxxxxxxxxxxxx
fs.oss.impl: org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem
jobmanager.execution.failover-strategy: region
rest.port: 8081
rest.address: localhost
建议可以在本地添加 FLINK_HOME 方便在上 k8s 之前本地排查问题使用
vim /etc/profile
#FLINK
export FLINK_HOME=/data/src/flink-1.16.0-scala-2.12
export PATH=$PATH:$FLINK_HOME/bin
source /etc/profile
在 StreamPark 添加 Flink conf:
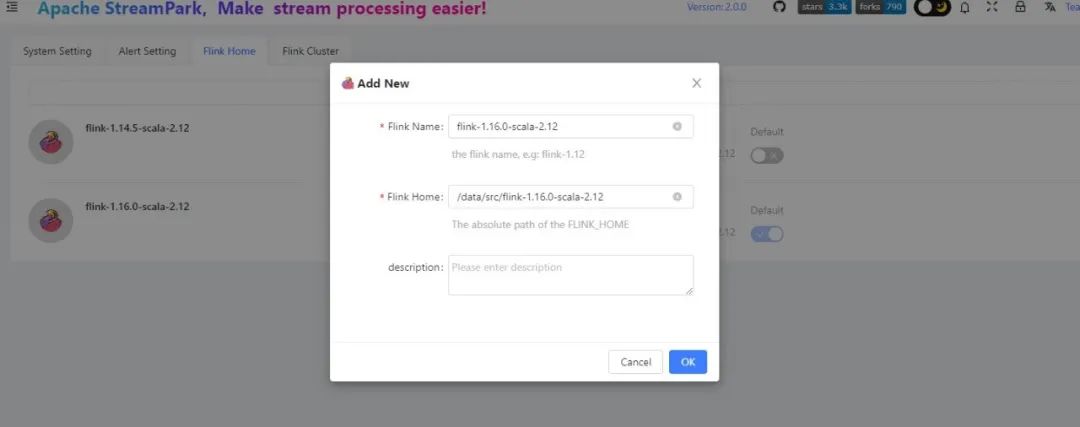
构建 Flink 1.16.0 基础镜像从 dockerhub拉取对应版本的镜像
#拉取镜像
docker pull flink:1.16.0-scala_2.12-java8
#打上 tag
docker tagflink:1.16.0-scala_2.12-java8 registry-vpc.cn-zhangjiakou.aliyuncs.com/xxxxx/flink:1.16.0-scala_2.12-java8
#push 到公司仓库
docker pushregistry-vpc.cn-zhangjiakou.aliyuncs.com/xxxxx/flink:1.16.0-scala_2.12-java8
创建 Dockerfile 文件 & target 目录将 flink-oss-fs-hadoop JAR包放置在该目录 Shaded Hadoop OSS file system jar 包下载地址:
https://repository.apache.org/snapshots/org/apache/paimon/paimon-oss/
.
├── Dockerfile
└── target
└── flink-oss-fs-hadoop-1.16.0.jar
touch Dockerfile
mkdir target
#vim Dockerfile
FROM registry-vpc.cn-zhangjiakou.aliyuncs.com/xxxxx/flink:1.16.0-scala_2.12-java8
RUN mkdir /opt/flink/plugins/oss-fs-hadoop
COPY target/flink-oss-fs-hadoop-1.16.0.jar /opt/flink/plugins/oss-fs-hadoop
build 基础镜像
docker build -t flink-table-store:v1.16.0 .
docker tag flink-table-store:v1.16.0 registry-vpc.cn-zhangjiakou.aliyuncs.com/xxxxx/flink-table-store:v1.16.0
docker push registry-vpc.cn-zhangjiakou.aliyuncs.com/xxxxx/flink-table-store:v1.16.0
接下来准备 Paimon jar 包,可以在 Apache Repository 下载对应版本,需要注意的是要和 flink 大版本保持一致
使用 Apache StreamPark™ 管理作业
前提条件:
- Kubernetes 客户端连接配置
- Kubernetes RBAC 配置
- 容器镜像仓库配置 (案例中使用的是阿里云镜像免费版)
- 创建挂载 checkpoint/savepoint 的 pvc 资源
Kubernetes 客户端连接配置:
将 k8s master节点~/.kube/config 配置直接拷贝到 StreamPark 服务器的目录,之后在 StreamPark 服务器执行以下命令显示 k8s 集群 running 代表权限和网络验证成功。
kubectl cluster-info
Kubernetes RBAC 配置,创建 streampark 命名空间:
kubectl create ns streampark
使用 default 账户创建 clusterrolebinding 资源:
kubectl create secret docker-registry streamparksecret
--docker-server=registry-vpc.cn-zhangjiakou.aliyuncs.com
--docker-username=xxxxxx
--docker-password=xxxxxx -n streampark```
容器镜像仓库配置:
案例中使用阿里云容器镜像服务ACR,也可以��使用自建镜像服务harbor代替。
创建命名空间 StreamPark (安全设置需要设置为私有)
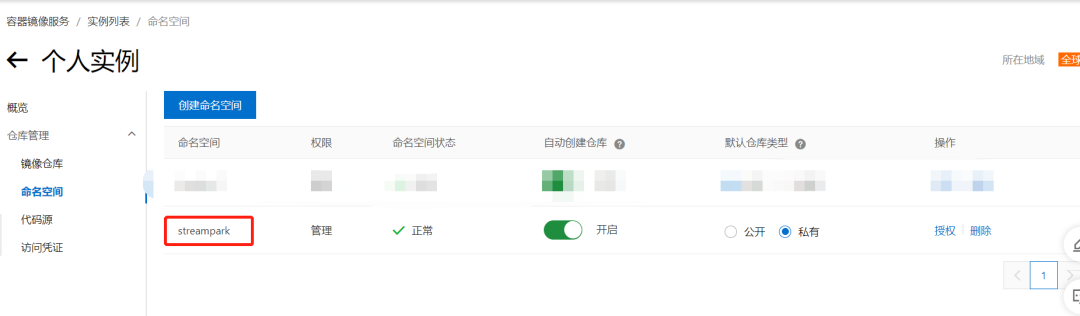
在 StreamPark 配置镜像仓库,任务构建镜像会推送到镜像仓库
创建 k8s secret 密钥用来拉取 ACR 中的镜像 streamparksecret 为密钥名称 自定义
kubectl create secret docker-registry streamparksecret
--docker-server=registry-vpc.cn-zhangjiakou.aliyuncs.com
--docker-username=xxxxxx
--docker-password=xxxxxx -n streampark
创建挂载 checkpoint/savepoint 的 pvc 资源,基于阿里云的对象存储OSS做K8S的持久化
OSS CSI 插件:
可以使用 OSS CSI 插件来帮助简化存储管理。您可以使用 csi 配置创建 pv,并且 pvc、pod 像往常一样定义,yaml 文件参考: https://bondextest.oss-cn-zhangjiakou.aliyuncs.com/ossyaml.zip
配置要求:
- 创建具有所需 RBAC 权限的服务帐户,参考:
https://github.com/kubernetes-sigs/alibaba-cloud-csi-driver/blob/master/docs/oss.md
kubectl -f rbac.yaml
- 部署OSS CSI 插件
kubectl -f oss-plugin.yaml
- 创建 CP&SP 的 PV
kubectl -f checkpoints_pv.yaml kubectl -f savepoints_pv.yaml
- 创建 CP&SP 的 PVC
kubectl -f checkpoints_pvc.yaml kubectl -f savepoints_pvc.yaml
配置好依赖环境,接下来我们就开始使用 Paimon 进行流式数仓的分层开发。
案例
统计海运空运实时委托单量
任务提交:初始化 Paimon catalog 配置
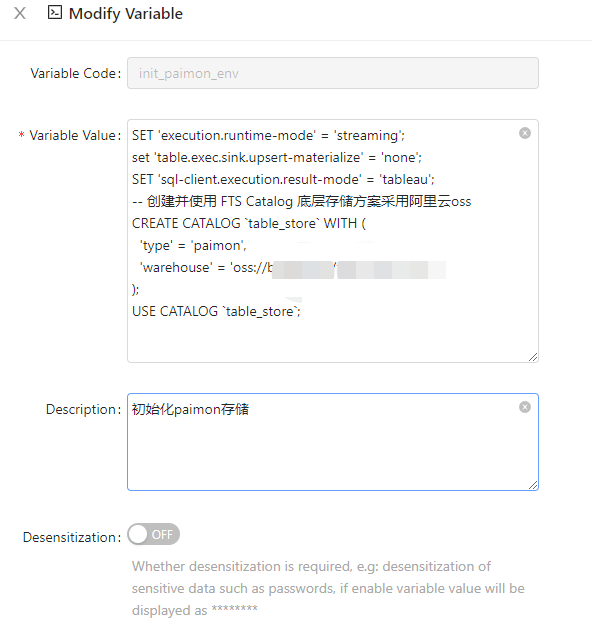
SET 'execution.runtime-mode' = 'streaming';
set 'table.exec.sink.upsert-materialize' = 'none';
SET 'sql-client.execution.result-mode' = 'tableau';
-- 创建并使用 FTS Catalog 底层存储方案采用阿里云oss
CREATE CATALOG `table_store` WITH (
'type' = 'paimon',
'warehouse' = 'oss://xxxxx/xxxxx' #自定义oss存储路径
);
USE CATALOG `table_store`;
一个任务同时抽取 postgres、mysql、sqlserver 三种数据库的表数据写入到 Paimon
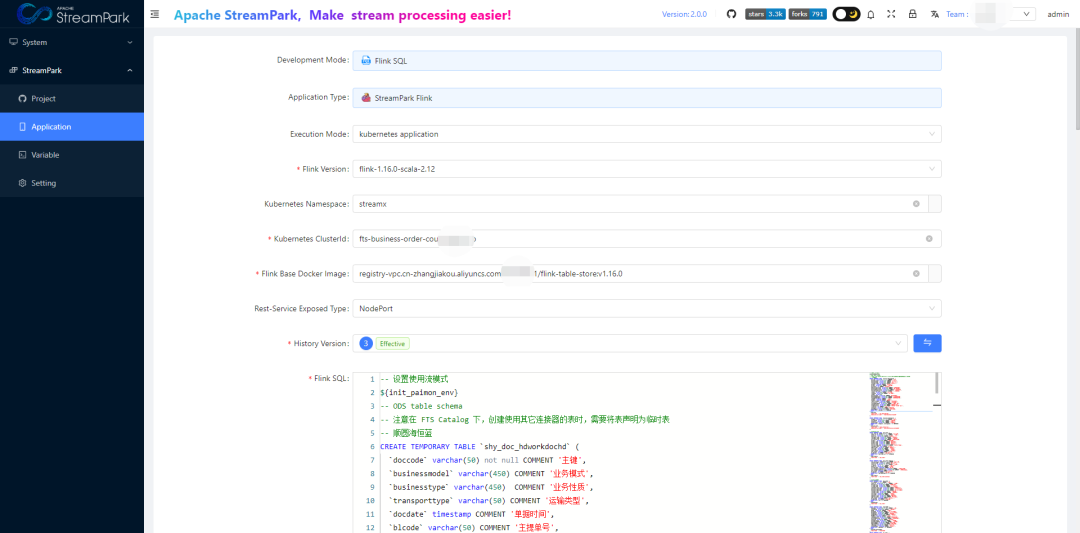
信息如下:
Development Mode:Flink SQL
Execution Mode :kubernetes application
Flink Version :flink-1.16.0-scala-2.12
Kubernetes Namespace :streampark
Kubernetes ClusterId :(任务名自定义即可)
#上传到阿里云镜像仓库的基础镜像
Flink Base Docker Image :registry-vpc.cn-zhangjiakou.aliyuncs.com/xxxxx/flink-table-store:v1.16.0
Rest-Service Exposed Type:NodePort
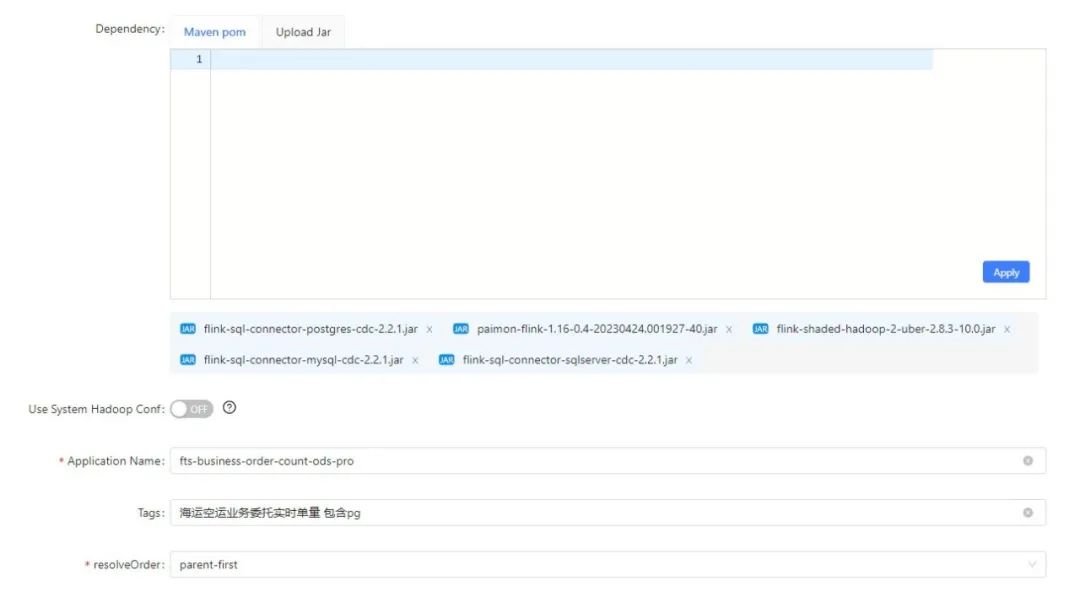
#paimon基础依赖包:
paimon-flink-1.16-0.4-20230424.001927-40.jar
flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
#flinkcdc依赖包下载地址:
https://github.com/ververica/flink-cdc-connectors/releases/tag/release-2.2.0
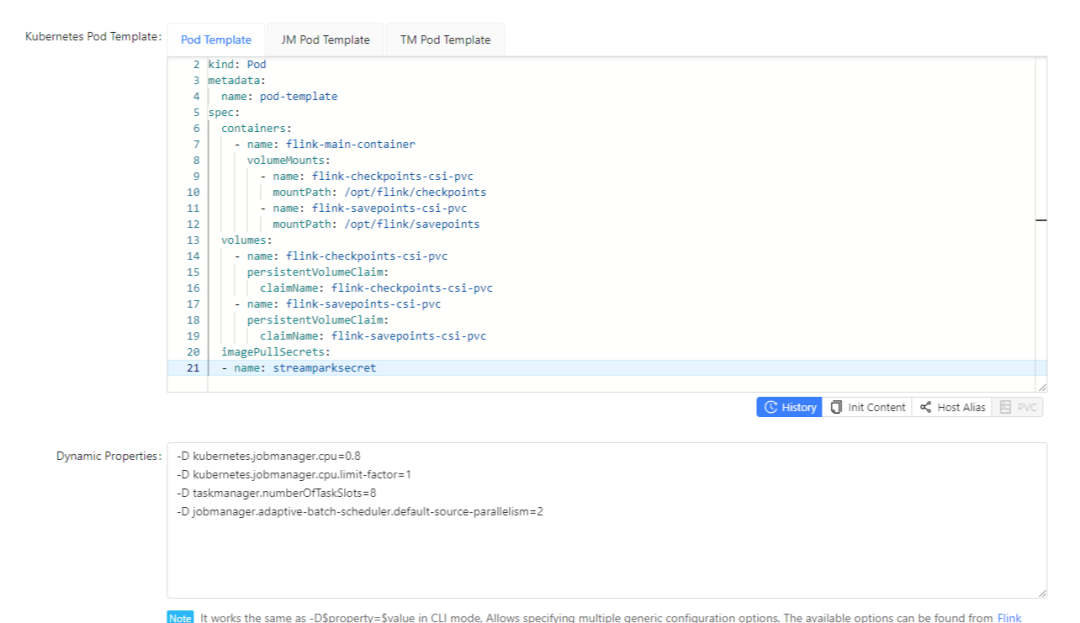
pod template:
apiVersion: v1
kind: Pod
metadata:
name: pod-template
spec:
containers:
- name: flink-main-container
volumeMounts:
- name: flink-checkpoints-csi-pvc
mountPath: /opt/flink/checkpoints
- name: flink-savepoints-csi-pvc
mountPath: /opt/flink/savepoints
volumes:
- name: flink-checkpoints-csi-pvc
persistentVolumeClaim:
claimName: flink-checkpoints-csi-pvc
- name: flink-savepoints-csi-pvc
persistentVolumeClaim:
claimName: flink-savepoints-csi-pvc
imagePullSecrets:
- name: streamparksecret
Flink sql:
- 构建源表和paimon中ods表的关系,这里就是源表和目标表一对一映射
-- postgre数据库 示例
CREATE TEMPORARY TABLE `shy_doc_hdworkdochd` (
`doccode` varchar(50) not null COMMENT '主键',
`businessmodel` varchar(450) COMMENT '业务模式',
`businesstype` varchar(450) COMMENT '业务性质',
`transporttype` varchar(50) COMMENT '运输类型',
......
`bookingguid` varchar(50) COMMENT '操作编号',
PRIMARY KEY (`doccode`) NOT ENFORCED
) WITH (
'connector' = 'postgres-cdc',
'hostname' = '数据库服务器IP地址',
'port' = '端口号',
'username' = '用户名',
'password' = '密码',
'database-name' = '数据库名',
'schema-name' = 'dev',
'decoding.plugin.name' = 'wal2json',,
'table-name' = 'doc_hdworkdochd',
'debezium.slot.name' = 'hdworkdochdslotname03'
);
CREATE TEMPORARY TABLE `shy_base_enterprise` (
`entguid` varchar(50) not null COMMENT '主键',
`entorgcode` varchar(450) COMMENT '客户编号',
`entnature` varchar(450) COMMENT '客户类型',
`entfullname` varchar(50) COMMENT '客户名称',
PRIMARY KEY (`entguid`,`entorgcode`) NOT ENFORCED
) WITH (
'connector' = 'postgres-cdc',
'hostname' = '数据库服务器IP地址',
'port' = '端口号',
'username' = '用户名',
'password' = '密码',
'database-name' = '数据库名',
'schema-name' = 'dev',
'decoding.plugin.name' = 'wal2json',
'table-name' = 'base_enterprise',
'debezium.snapshot.mode'='never', -- 增量同步(全量+增量忽略该属性)
'debezium.slot.name' = 'base_enterprise_slotname03'
);
-- 根据源表结构在paimon上ods层创建对应的目标表
CREATE TABLE IF NOT EXISTS ods.`ods_shy_jh_doc_hdworkdochd` (
`o_year` BIGINT NOT NULL COMMENT '分区字段',
`create_date` timestamp NOT NULL COMMENT '创建时间',
PRIMARY KEY (`o_year`, `doccode`) NOT ENFORCED
) PARTITIONED BY (`o_year`)
WITH (
'changelog-producer.compaction-interval' = '2m'
) LIKE `shy_doc_hdworkdochd` (EXCLUDING CONSTRAINTS EXCLUDING OPTIONS);
CREATE TABLE IF NOT EXISTS ods.`ods_shy_base_enterprise` (
`create_date` timestamp NOT NULL COMMENT '创建时间',
PRIMARY KEY (`entguid`,`entorgcode`) NOT ENFORCED
)
WITH (
'changelog-producer.compaction-interval' = '2m'
) LIKE `shy_base_enterprise` (EXCLUDING CONSTRAINTS EXCLUDING OPTIONS);
-- 设置作业名,执行作业任务将源表数据实时写入到paimon对应表中
SET 'pipeline.name' = 'ods_doc_hdworkdochd';
INSERT INTO
ods.`ods_shy_jh_doc_hdworkdochd`
SELECT
*
,YEAR(`docdate`) AS `o_year`
,TO_TIMESTAMP(CONVERT_TZ(cast(CURRENT_TIMESTAMP as varchar), 'UTC', 'Asia/Shanghai')) AS `create_date`
FROM
`shy_doc_hdworkdochd` where `docdate` is not null and `docdate` > '2023-01-01';
SET 'pipeline.name' = 'ods_shy_base_enterprise';
INSERT INTO
ods.`ods_shy_base_enterprise`
SELECT
*
,TO_TIMESTAMP(CONVERT_TZ(cast(CURRENT_TIMESTAMP as varchar), 'UTC', 'Asia/Shanghai')) AS `create_date`
FROM
`shy_base_enterprise` where entorgcode is not null and entorgcode <> '';
-- mysql数据库 示例
CREATE TEMPORARY TABLE `doc_order` (
`id` BIGINT NOT NULL COMMENT '主键',
`order_no` varchar(50) NOT NULL COMMENT '订单号',
`business_no` varchar(50) COMMENT 'OMS服务号',
......
`is_deleted` int COMMENT '是否作废',
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '数据库服务器地址',
'port' = '端口号',
'username' = '用户名',
'password' = '密码',
'database-name' = '库名',
'table-name' = 'doc_order'
);
-- 根据源表结构在paimon上ods层创建对应的目标表
CREATE TABLE IF NOT EXISTS ods.`ods_bondexsea_doc_order` (
`o_year` BIGINT NOT NULL COMMENT '分区字段',
`create_date` timestamp NOT NULL COMMENT '创建时间',
PRIMARY KEY (`o_year`, `id`) NOT ENFORCED
) PARTITIONED BY (`o_year`)
WITH (
'changelog-producer.compaction-interval' = '2m'
) LIKE `doc_order` (EXCLUDING CONSTRAINTS EXCLUDING OPTIONS);
-- 设置作业名,执行作业任务将源表数据实时写入到paimon对应表中
SET 'pipeline.name' = 'ods_bondexsea_doc_order';
INSERT INTO
ods.`ods_bondexsea_doc_order`
SELECT
*
,YEAR(`gmt_create`) AS `o_year`
,TO_TIMESTAMP(CONVERT_TZ(cast(CURRENT_TIMESTAMP as varchar), 'UTC', 'Asia/Shanghai')) AS `create_date`
FROM `doc_order` where gmt_create > '2023-01-01';
-- sqlserver数据库 示例
CREATE TEMPORARY TABLE `OrderHAWB` (
`HBLIndex` varchar(50) NOT NULL COMMENT '主键',
`CustomerNo` varchar(50) COMMENT '客户编号',
......
`CreateOPDate` timestamp COMMENT '制单日期',
PRIMARY KEY (`HBLIndex`) NOT ENFORCED
) WITH (
'connector' = 'sqlserver-cdc',
'hostname' = '数据库�服务器地址',
'port' = '端口号',
'username' = '用户名',
'password' = '密码',
'database-name' = '数据库名',
'schema-name' = 'dbo',
-- 'debezium.snapshot.mode' = 'initial' -- 全量增量都抽取
'scan.startup.mode' = 'latest-offset',-- 只抽取增量数据
'table-name' = 'OrderHAWB'
);
-- 根据源表结构在paimon上ods层创建对应的目标表
CREATE TABLE IF NOT EXISTS ods.`ods_airsea_airfreight_orderhawb` (
`o_year` BIGINT NOT NULL COMMENT '分区字段',
`create_date` timestamp NOT NULL COMMENT '创建时间',
PRIMARY KEY (`o_year`, `HBLIndex`) NOT ENFORCED
) PARTITIONED BY (`o_year`)
WITH (
'changelog-producer.compaction-interval' = '2m'
) LIKE `OrderHAWB` (EXCLUDING CONSTRAINTS EXCLUDING OPTIONS);
-- 设置作业名,执行作业任务将源表数据实时写入到paimon对应表中
SET 'pipeline.name' = 'ods_airsea_airfreight_orderhawb';
INSERT INTO
ods.`ods_airsea_airfreight_orderhawb`
SELECT
RTRIM(`HBLIndex`) as `HBLIndex`
......
,`CreateOPDate`
,YEAR(`CreateOPDate`) AS `o_year`
,TO_TIMESTAMP(CONVERT_TZ(cast(CURRENT_TIMESTAMP as varchar), 'UTC', 'Asia/Shanghai')) AS `create_date`
FROM `OrderHAWB` where CreateOPDate > '2023-01-01';
业务表数据实时写入 Paimon ods 表效果如下:
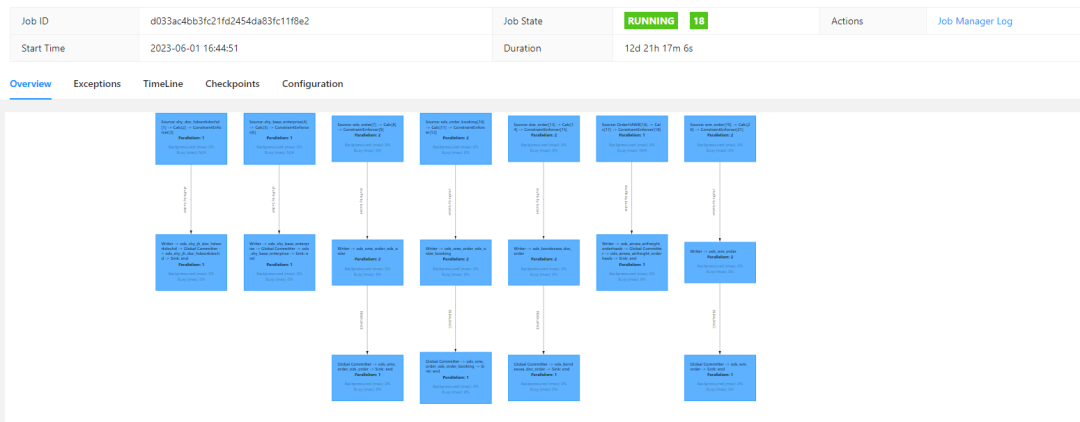
- 将ods层表的数据打宽写入 dwd 层中,这里其实就是将 ods 层相关业务表合并写入dwd 中,这里主要是处理 count_order 字段的值,因为源表中的数据存在逻辑删除和物理删除所以通过 count 函数统计会有问题,所以我们这里采用 sum 聚合来计算单量,每个reference_no对应的count_order是1,如果逻辑作废通过sql将它处理成0,物理删除 Paimon 会自动处理。
dim 维表我们这边直接拿的 doris 里面处理好的维表来使用,维表更新频率低,所以没有在 Paimon 里面进行二次开发。
-- 在paimon-dwd层创建宽表
CREATE TABLE IF NOT EXISTS dwd.`dwd_business_order` (
`reference_no` varchar(50) NOT NULL COMMENT '委托单号主键',
`bondex_shy_flag` varchar(8) NOT NULL COMMENT '区分',
`is_server_item` int NOT NULL COMMENT '是否已经关联订单',
`order_type_name` varchar(50) NOT NULL COMMENT '业务分类',
`consignor_date` DATE COMMENT '统计日期',
`consignor_code` varchar(50) COMMENT '客户编号',
`consignor_name` varchar(160) COMMENT '客户名称',
`sales_code` varchar(32) NOT NULL COMMENT '销售编号',
`sales_name` varchar(200) NOT NULL COMMENT '销售名称',
`delivery_center_op_id` varchar(32) NOT NULL COMMENT '交付编号',
`delivery_center_op_name` varchar(200) NOT NULL COMMENT '交付名称',
`pol_code` varchar(100) NOT NULL COMMENT '起运港代码',
`pot_code` varchar(100) NOT NULL COMMENT '中转港代码',
`port_of_dest_code` varchar(100) NOT NULL COMMENT '目的港代码',
`is_delete` int not NULL COMMENT '是否作废',
`order_status` varchar(8) NOT NULL COMMENT '订单状态',
`count_order` BIGINT not NULL COMMENT '订单数',
`o_year` BIGINT NOT NULL COMMENT '分区字段',
`create_date` timestamp NOT NULL COMMENT '创建时间',
PRIMARY KEY (`o_year`,`reference_no`,`bondex_shy_flag`) NOT ENFORCED
) PARTITIONED BY (`o_year`)
WITH (
-- 每个 partition 下设置 2 个 bucket
'bucket' = '2',
'changelog-producer' = 'full-compaction',
'snapshot.time-retained' = '2h',
'changelog-producer.compaction-interval' = '2m'
);
-- 设置作业名,将ods层的相关业务表合并写入到dwd层
SET 'pipeline.name' = 'dwd_business_order';
INSERT INTO
dwd.`dwd_business_order`
SELECT
o.doccode,
......,
YEAR (o.docdate) AS o_year
,TO_TIMESTAMP(CONVERT_TZ(cast(CURRENT_TIMESTAMP as varchar), 'UTC', 'Asia/Shanghai')) AS `create_date`
FROM
ods.ods_shy_jh_doc_hdworkdochd o
INNER JOIN ods.ods_shy_base_enterprise en ON o.businessguid = en.entguid
LEFT JOIN dim.dim_hhl_user_code sales ON o.salesguid = sales.USER_GUID
LEFT JOIN dim.dim_hhl_user_code op ON o.bookingguid = op.USER_GUID
UNION ALL
SELECT
business_no,
......,
YEAR ( gmt_create ) AS o_year
,TO_TIMESTAMP(CONVERT_TZ(cast(CURRENT_TIMESTAMP as varchar), 'UTC', 'Asia/Shanghai')) AS `create_date`
FROM
ods.ods_bondexsea_doc_order
UNION ALL
SELECT
HBLIndex,
......,
YEAR ( CreateOPDate ) AS o_year
,TO_TIMESTAMP(CONVERT_TZ(cast(CURRENT_TIMESTAMP as varchar), 'UTC', 'Asia/Shanghai')) AS `create_date`
FROM
ods.`ods_airsea_airfreight_orderhawb`
;
flink ui 可以看到 ods 数据经过 paimon 实时 join 清洗到表 dwd_business_order
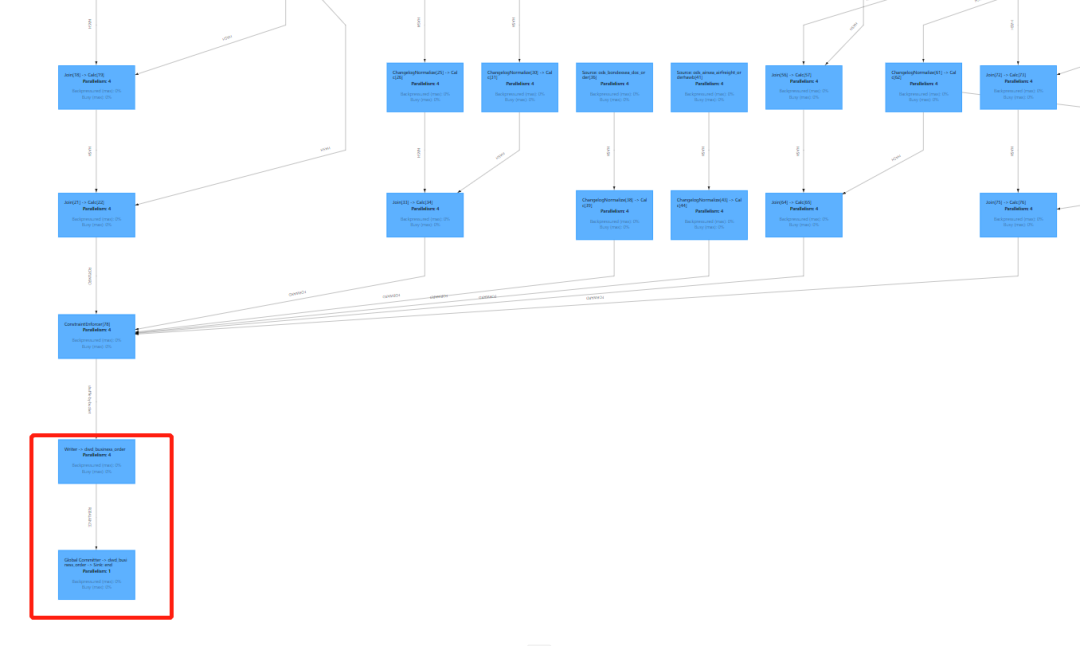
2.将dwd层数据轻度聚合到dwm层中,将相关数据写入dwm.dwm_business_order_count 表中,该表数据会根据主键对聚合字段做 sum,sum_orderCount 字段就是聚合结果,物理删除的数据 sum 时 paimon 会自动处理。
-- 创建dwm层轻度汇总表,根据日期、销售、操作、业务类别、客户、起运港、目的港汇总单量
CREATE TABLE IF NOT EXISTS dwm.`dwm_business_order_count` (
`l_year` BIGINT NOT NULL COMMENT '统计年',
`l_month` BIGINT NOT NULL COMMENT '统计月',
`l_date` DATE NOT NULL COMMENT '统计日期',
`bondex_shy_flag` varchar(8) NOT NULL COMMENT '区分',
`order_type_name` varchar(50) NOT NULL COMMENT '业务分类',
`is_server_item` int NOT NULL COMMENT '是否已经关联订单',
`customer_code` varchar(50) NOT NULL COMMENT '客户编号',
`sales_code` varchar(50) NOT NULL COMMENT '销售编号',
`delivery_center_op_id` varchar(50) NOT NULL COMMENT '交付编号',
`pol_code` varchar(100) NOT NULL COMMENT '起运港代码',
`pot_code` varchar(100) NOT NULL COMMENT '中转港代码',
`port_of_dest_code` varchar(100) NOT NULL COMMENT '目的港代码',
`customer_name` varchar(200) NOT NULL COMMENT '客户名称',
`sales_name` varchar(200) NOT NULL COMMENT '销售名称',
`delivery_center_op_name` varchar(200) NOT NULL COMMENT '交付名称',
`sum_orderCount` BIGINT NOT NULL COMMENT '订单数',
`create_date` timestamp NOT NULL COMMENT '创建时间',
PRIMARY KEY (`l_year`,
`l_month`,
`l_date`,
`order_type_name`,
`bondex_shy_flag`,
`is_server_item`,
`customer_code`,
`sales_code`,
`delivery_center_op_id`,
`pol_code`,
`pot_code`,
`port_of_dest_code`) NOT ENFORCED
) WITH (
'changelog-producer' = 'full-compaction',
'changelog-producer.compaction-interval' = '2m',
'merge-engine' = 'aggregation', -- 使用 aggregation 聚合计算 sum
'fields.sum_orderCount.aggregate-function' = 'sum',
'fields.create_date.ignore-retract'='true',
'fields.sales_name.ignore-retract'='true',
'fields.customer_name.ignore-retract'='true',
'snapshot.time-retained' = '2h',
'fields.delivery_center_op_name.ignore-retract'='true'
);
-- 设置作业名
SET 'pipeline.name' = 'dwm_business_order_count';
INSERT INTO
dwm.`dwm_business_order_count`
SELECT
YEAR(o.`consignor_date`) AS `l_year`
,MONTH(o.`consignor_date`) AS `l_month`
......,
,TO_TIMESTAMP(CONVERT_TZ(cast(CURRENT_TIMESTAMP as varchar), 'UTC', 'Asia/Shanghai')) AS create_date
FROM
dwd.`dwd_business_order` o
;
Flink UI 效果如下 dwd_business_orders 数据聚合写到 dwm_business_order_count:
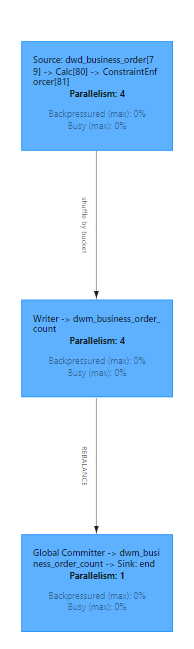
4.将 dwm 层数据聚合到 dws 层中,dws 层是做了更小维度的汇总
-- 创建根据操作人、业务类型聚合当天的单量
CREATE TABLE IF NOT EXISTS dws.`dws_business_order_count_op` (
`l_year` BIGINT NOT NULL COMMENT '统计年',
`l_month` BIGINT NOT NULL COMMENT '统计月',
`l_date` DATE NOT NULL COMMENT '统计日期',
`order_type_name` varchar(50) NOT NULL COMMENT '业务分类',
`delivery_center_op_id` varchar(50) NOT NULL COMMENT '交付编号',
`delivery_center_op_name` varchar(200) NOT NULL COMMENT '交付名称',
`sum_orderCount` BIGINT NOT NULL COMMENT '订单数',
`create_date` timestamp NOT NULL COMMENT '创建时间',
PRIMARY KEY (`l_year`, `l_month`,`l_date`,`order_type_name`,`delivery_center_op_id`) NOT ENFORCED
) WITH (
'merge-engine' = 'aggregation', -- 使用 aggregation 聚合计算 sum
'fields.sum_orderCount.aggregate-function' = 'sum',
'fields.create_date.ignore-retract'='true',
'snapshot.time-retained' = '2h',
'fields.delivery_center_op_name.ignore-retract'='true'
);
-- 设置作业名
SET 'pipeline.name' = 'dws_business_order_count_op';
INSERT INTO
dws.`dws_business_order_count_op`
SELECT
o.`l_year`
,o.`l_month`
,o.`l_date`
,o.`order_type_name`
,o.`delivery_center_op_id`
,o.`delivery_center_op_name`
,o.`sum_orderCount`
,TO_TIMESTAMP(CONVERT_TZ(cast(CURRENT_TIMESTAMP as varchar), 'UTC', 'Asia/Shanghai')) AS create_date
FROM
dwm.`dwm_business_order_count` o
;
Flink UI 效果如下 dws_business_order_count_op 数据写到 dws_business_order_count_op:
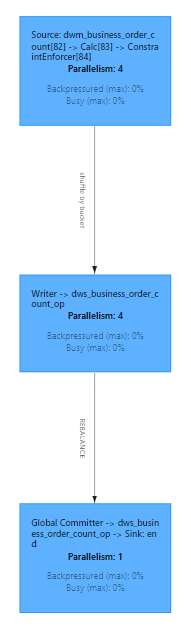
总体数据流转示例
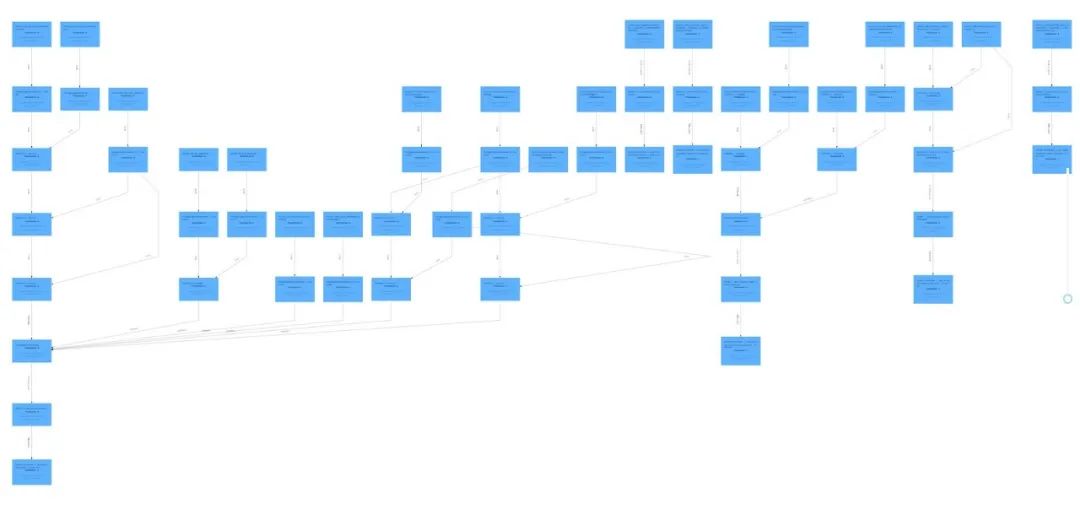
源表:

paimon-ods:

paimon-dwd:

paimon-dwm:
![]()
paimon-dws:

特别提醒 sqlserver 数据库抽取时如果源表数据量过大全量抽取会锁表,建议在业务允许的情况下采用增量抽取。对于全量抽取 sqlserver 可以采用中转的方式 sqlserver 全量数据导入到 mysql,从 mysql 再到 paimon-ods ,后面再通过 sqlserever 做增量抽取。
04 问题排查分析
1. 聚合数据计算不准
sqlserver cdc 采集数据到 paimon 表,说明:
dwd 表:
'changelog-producer' = 'input'
ads 表:
'merge-engine' = 'aggregation',-- 使用 aggregation 聚合计算 sum
'fields.sum_amount.aggregate-function' = 'sum'
ADS 层聚合表采用 agg sum 会出现 dwd 数据流不产生 update_before,产生错误数据流 update_after 比如上游源表 update 10 到 30 dwd 层数据会变更为 30,ads 聚合层数据也�会变更为 30,但是现在变为了 append 数据变成了 10+30=40 的错误数据。
解决办法:
By specifying 'changelog-producer' = 'full-compaction', Table Store will compare the results between full compactions and produce the differences as changelog. The latency of changelog is affected by the frequency of full compactions.
By specifying changelog-producer.compaction-interval table property (default value 30min), users can define the maximum interval between two full compactions to ensure latency. This table property does not affect normal compactions and they may still be performed once in a while by writers to reduce reader costs.
这样能解决上述问题。但是随之而来出现了新的问题。默认 changelog-producer.compaction-interval 是 30min,意味着 上游的改动到 ads 查询要间隔 30min,生产过程中发现将压缩间隔时间改成 1min 或者 2 分钟的情况下,又会出现上述 ADS 层聚合数据不准的情况。
'changelog-producer.compaction-interval' = '2m'
需要在写入 Flink Table Store 时需要配置 table.exec.sink.upsert-materialize= none,避免产生 Upsert 流,以保证 Flink Table Store 中能够保存完整的 changelog,为后续的流读操作做准备。
set 'table.exec.sink.upsert-materialize' = 'none'
2. 相同 sequence.field 导致 dwd 明细宽表无法收到 update 数据更新
mysql cdc 采集数据到 paimon 表
说明:
在 MySQL 源端执��行 update 数据修改成功后,dwd_orders 表数据能同步成功
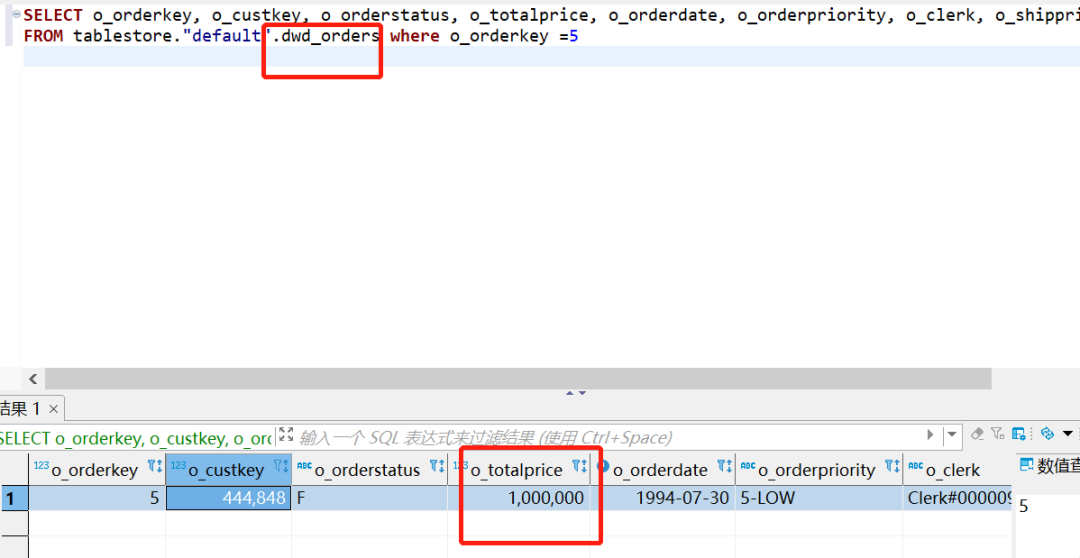
但是查看 dwd_enriched_orders 表数据无法同步,启动流模式查看数据,发现没有数据流向
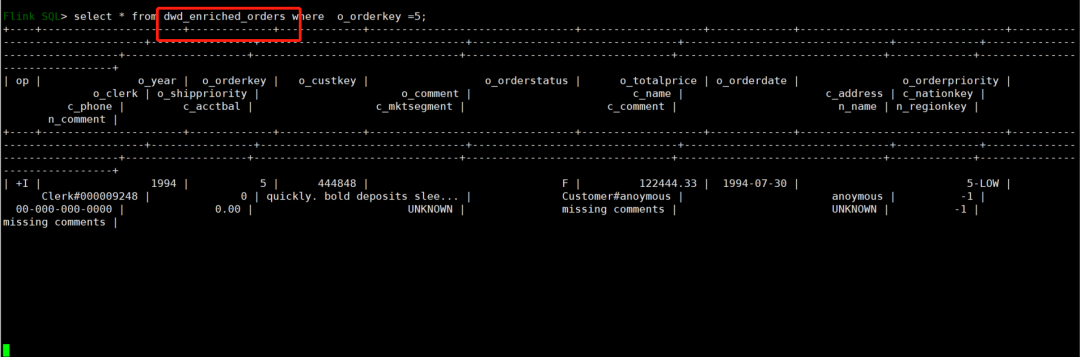
解决:
排查发现是由于配置了参数 'sequence.field' = 'o_orderdate'(使用 o_orderdate 生成 sequence id,相同主键合并时选择 sequence id 更大的记录)导致的,因为在修改价格的时候 o_orderdate 字段时间不变, 继而'sequence.field' 是相同的,导致顺序不确定,所以 ROW1 和 ROW2,它们的 o_orderdate 是一样的,所以在更新时会随机选择,所有将该参数去掉即可,去掉后正常按照输入的先后顺序,自动生成一个 sequence number,不会影响同步结果。
3. Aggregate function 'last_non_null_value' does not support retraction
报错:
Caused by: java.lang.UnsupportedOperationException: Aggregate function 'last_non_null_value' does not support retraction, If you allow this function to ignore retraction messages, you can configure 'fields.${field_name}.ignore-retract'='true'.
可以在官方文档找到解释:
Only sum supports retraction (UPDATE_BEFORE and DELETE), others aggregate functions do not support retraction.
可以理解为:除了 SUM 函数,其他的 Agg 函数都不支持 Retraction,为了避免接收到 DELETE 和 UPDATEBEFORE 消息报错,需要通过给指定字段配 'fields.${field_name}.ignore-retract'='true' 忽略,解决这个报错
WITH (
'merge-engine' = 'aggregation', -- 使用 aggregation 聚合计算 sum
'fields.sum_orderCount.aggregate-function' = 'sum',
'fields.create_date.ignore-retract'='true' #create_date 字段
);
4. paimon任务中断失败
任务异常中断 导致pod挂掉,查看loki日志显示akka.pattern.AskTimeoutException: Ask timed out on
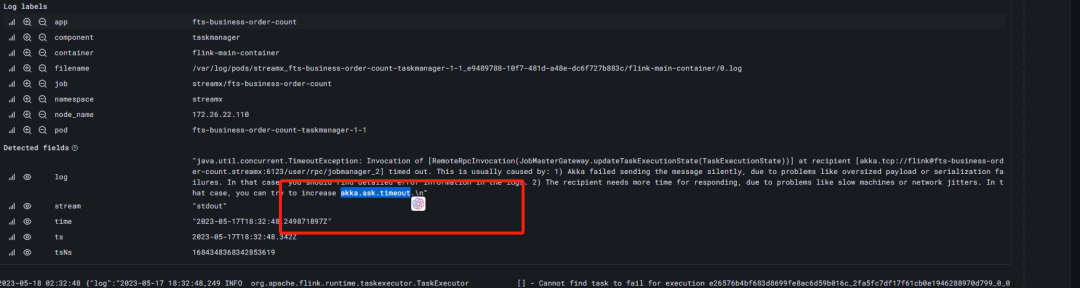
java.util.concurrent.TimeoutException: Invocation of [RemoteRpcInvocation(JobMasterGateway.updateTaskExecutionState(TaskExecutionState))] at recipient [akka.tcp://flink@fts-business-order-count.streampark:6123/user/rpc/jobmanager_2] timed out. This is usually caused by: 1) Akka failed sending the message silently, due to problems like oversized payload or serialization failures. In that case, you should find detailed error information in the logs. 2) The recipient needs more time for responding, due to problems like slow machines or network jitters. In that case, you can try to increase akka.ask.timeout.\n"
初步判断应该是由于以上2个原因导致触发了 akka 的超时机制,那就调整集群的akka超时间配置和进行单个任务拆分或者调大资源配置。
我们这边先看如何进行参数修改:
| key | default | describe |
|---|---|---|
| akka.ask.timeout | 10s | Timeout used for all futures and blocking Akka calls. If Flink fails due to timeouts then you should try to increase this value. Timeouts can be caused by slow machines or a congested network. The timeout value requires a time-unit specifier (ms/s/min/h/d). |
| web.timeout | 600000 | Timeout for asynchronous operations by the web monitor in milliseconds. |
在 conf/flink-conf.yaml 最后增加下面参数:
akka.ask.timeout: 100s
web.timeout:1000000
然后在 streampark 手动刷新下 flink-conf.yaml 验证参数是否同步成功。
5. snapshot no such file or director
发现 cp 出现失败情况
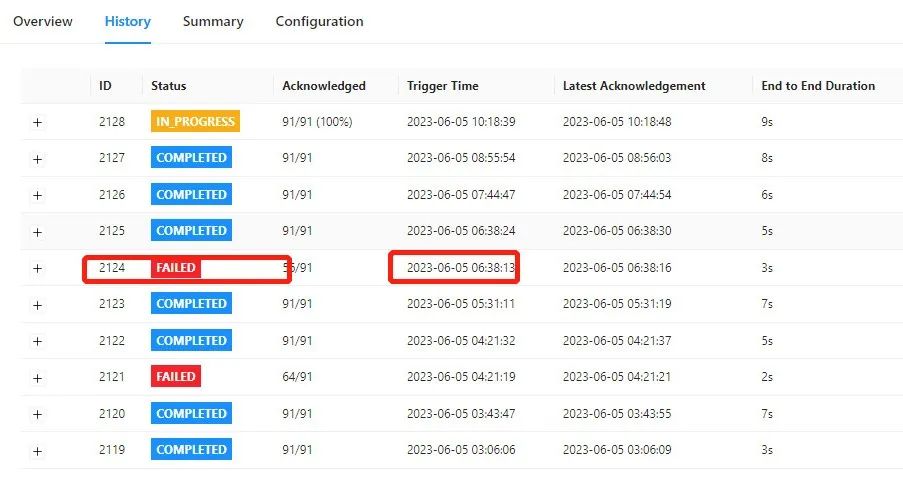
对应时间点日志显示 Snapshot 丢失,任务显示为 running 状态,但是源表 mysql 数据无法写入 paimon ods 表
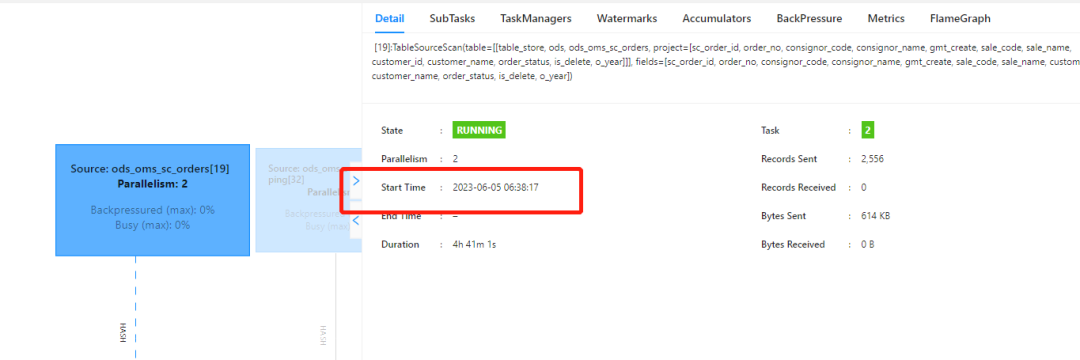
定位cp失败原因为:计算量大,CPU密集性,导致TM内线程一直在processElement,而没有时间做CP
无法读取 Snapshot 原因为:flink 集群资源不够,Writer 和 Committer 产生竞争,Full-Compaction 时读到了已过期部分的不完整的 Snapshot,目前官方针对这个问题已经修复:
https://github.com/apache/incubator-paimon/pull/1308
而解决 cp 失败的解决办法增加并行度,增加 deploymenttaskmanager slot 和 jobmanager cpu
-D kubernetes.jobmanager.cpu=0.8
-D kubernetes.jobmanager.cpu.limit-factor=1
-D taskmanager.numberOfTaskSlots=8
-D jobmanager.adaptive-batch-scheduler.default-source-parallelism=2
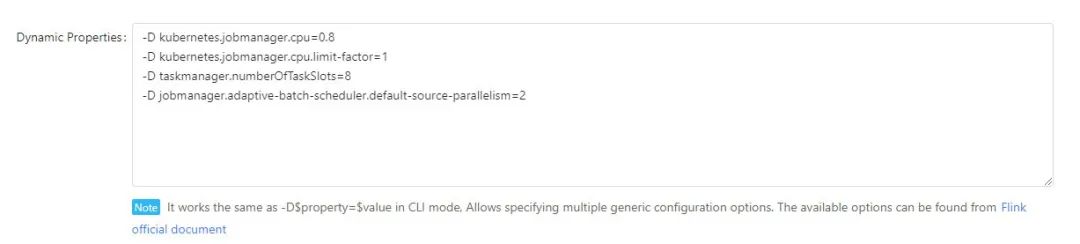
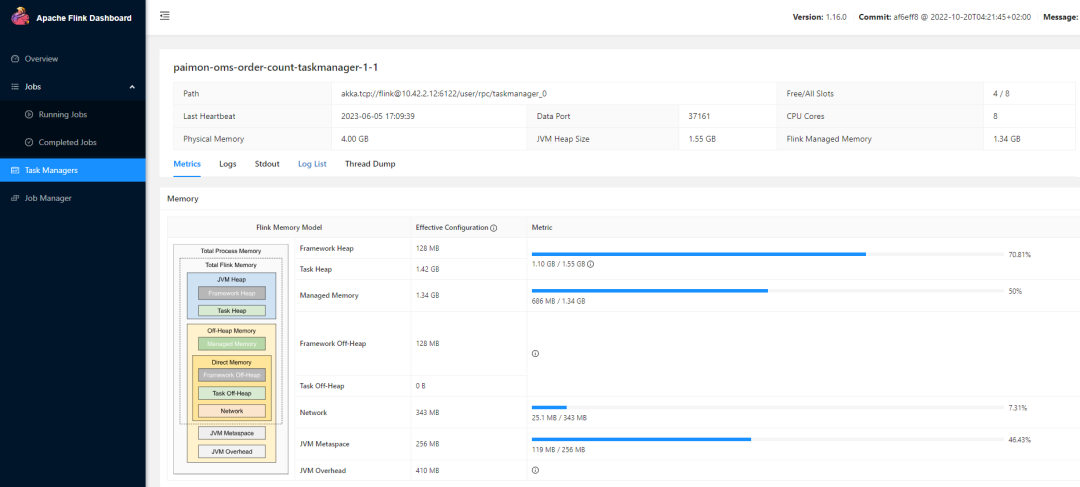
在复杂的实时任务中,可以通过修改动态参数的方式,增加资源。
05 未 来 规 划
- 自建的数据平台 bondata 正在集成 paimon 的元数据信息、数据指标体系、血缘、一键 pipline 等功能,形成海程邦达的数据资产,并将在此基础上展开一站式数据治理
- 后面将基于 trino Catalog接入Doris,实现真正的离线数据和实时数据的one service
- 采用 doris + paimon 的架构方案继续推进集团内部流批一体数仓建设的步伐
在这里要感谢之信老师和 StreamPark 社区在使用 StreamPark + Paimon 过程中的大力支持,在学习使用过程中遇到的问题,都能在第一时间给到解惑并得到解决,我们后面也会积极参与社区的交流和建设,让 paimon 能为更多开发者和企业提供流批一体的数据湖解决方案。