Apache Kafka Connector
Apache Flink 官方提供了 Apache Kafka 的连接器,用于从 Kafka 主题中读取或者向其中写入数据,可提供精确一次的处理语义。
Apache StreamPark 中 KafkaSource 和 KafkaSink 基于官网的 Kafka Connector 进一步封装,屏蔽了很多细节,简化开发步骤,让数据的读取和写入更简单。
依赖
Apache Flink 集成了通用的 Kafka 连接器,它会尽力与 Kafka client 的最新版本保持同步。该连接器使用的 Kafka client 版本可能会在 Flink 版本之间发生变化。当前 Kafka client 向后兼容 0.10.0 或更高版本的 Kafka broker。有关 Kafka 兼容性的更多细节,请参考 Apache Kafka 的官方文档。
<!--必须要导入的依赖-->
<dependency>
<groupId>org.apache.streampark</groupId>
<artifactId>streampark-flink-core</artifactId>
<version>${project.version}</version>
</dependency>
<!--flink-connector-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.12.0</version>
</dependency>
同时在开发阶段,以下的依赖也是必要的:
<!--以下scope为provided的依赖也是必须要导入的-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
Kafka Source (Consumer)
先介绍基于官网的标准的kafka consumer的方式,以下代码摘自 Apache Kafka 官网文档
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "test")
val stream = env.addSource(new FlinkKafkaConsumer[String]("topic", new SimpleStringSchema(), properties))
可以看到一上来定义了一堆kafka的连接信息,这种方式各项参数都是硬编码的方式写死的,非常的不灵敏,下面我们来看看如何用StreamPark接入 kafka的数据,只需要按照规定的格式定义好配置文件然后编写代码即可,配置和代码如下
基础消费示例
kafka.source:
bootstrap.servers: kfk1:9092,kfk2:9092,kfk3:9092
topic: test_user
group.id: user_01
auto.offset.reset: earliest
enable.auto.commit: true
kafka.source这个前缀是固定的,kafka properties相关的参数必须遵守 Apache Kafka 官网文档 对参数key的设置规范
- Scala
- Java
package org.apache.streampark.flink.quickstart
import org.apache.streampark.flink.core.scala.FlinkStreaming
import org.apache.streampark.flink.core.scala.sink.JdbcSink
import org.apache.streampark.flink.core.scala.source.KafkaSource
import org.apache.flink.api.scala._
object kafkaSourceApp extends FlinkStreaming {
override def handle(): Unit = {
val source = KafkaSource().getDataStream[String]()
print(source)
}
}
import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
import org.apache.streampark.flink.core.java.source.KafkaSource;
import org.apache.streampark.flink.core.scala.StreamingContext;
import org.apache.streampark.flink.core.scala.source.KafkaRecord;
import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
public class KafkaSimpleJavaApp {
public static void main(String[] args) {
StreamEnvConfig envConfig = new StreamEnvConfig(args, null);
StreamingContext context = new StreamingContext(envConfig);
DataStream<String> source = new KafkaSource<String>(context)
.getDataStream()
.map((MapFunction<KafkaRecord<String>, String>) KafkaRecord::value);
source.print();
context.start();
}
}
高级配置参数
KafkaSource是基于Flink Kafka Connector封装一个更简单的kafka读取类,构造方法里需要传入StreamingContext,当程序启动时传入配置文件即可,框架会自动解析配置文件,在new KafkaSource的时候会自动的从配置文件中获取相关信息,初始化并返回一个Kafka Consumer,在这里topic下只配置了一个topic,因此在消费的时候不用指定topic直接默认获取这个topic来消费, 这只是一个最简单的例子,更多更复杂的规则和读取操作则要通过.getDataStream()在该方法里传入参数才能实现
我们看看getDataStream这个方法的签名
def getDataStream[T: TypeInformation](topic: java.io.Serializable = null,
alias: String = "",
deserializer: KafkaDeserializationSchema[T],
strategy: WatermarkStrategy[KafkaRecord[T]] = null
): DataStream[KafkaRecord[T]]
参数具体作用如下
| 参数名 | 参数类型 | 作用 | 默认值 |
|---|---|---|---|
topic | Serializable | 一个topic或者一组topic | 无 |
alias | String | 用于区别不同的kafka实例 | 无 |
deserializer | DeserializationSchema | topic里数据的具体解析类 | KafkaStringDeserializationSchema |
strategy | WatermarkStrategy | watermark生成策略 | 无 |
下面我们来看看更多的使用和配置方式
- 消费多个Kafka实例
- 消费多个Topic
- Topic动态发现
- 从指定Offset消费
- 指定KafkaDeserializationSchema
- 指定WatermarkStrategy
消费多个Kafka实例
在框架开发之初就考虑到了多个不同实例的kafka的配置情况.如何来统一配置,并且规范格式呢?在streampark中是这么解决的,假如我们要同时消费两个不同实例的kafka,配置文件定义如下,
可以看到在 kafka.source 下直接放kafka的实例名称(名字可以任意),在这里我们统一称为 alias , alias 必须是唯一的,来区别不同的实例,然后别的参数还是按照之前的规范,
统统放到当前这个实例的 namespace 下即可.如果只有一个kafka实例,则可以不用配置 alias
在写代码消费时注意指定对应的 alias 即可,配置和代码如下
- 配置
- Scala
- Java
kafka.source:
kafka1:
bootstrap.servers: kfk1:9092,kfk2:9092,kfk3:9092
topic: test_user
group.id: user_01
auto.offset.reset: earliest
enable.auto.commit: true
kafka2:
bootstrap.servers: kfk4:9092,kfk5:9092,kfk6:9092
topic: kafka2
group.id: kafka2
auto.offset.reset: earliest
enable.auto.commit: true
//消费kafka1实例的数据
KafkaSource().getDataStream[String](alias = "kafka1")
.uid("kfkSource1")
.name("kfkSource1")
.print()
//消费kafka2实例的数据
KafkaSource().getDataStream[String](alias = "kafka2")
.uid("kfkSource2")
.name("kfkSource2")
.print()
StreamEnvConfig envConfig = new StreamEnvConfig(args, null);
StreamingContext context = new StreamingContext(envConfig);
//消费kafka1实例的数据
DataStream<String> source1 = new KafkaSource<String>(context)
.alias("kafka1")
.getDataStream()
print();
//消费kafka1实例的数据
DataStream<String> source2 = new KafkaSource<String>(context)
.alias("kafka2")
.getDataStream()
.print();
context.start();
java api在编写代码时,一定要将alias等这些参数的设置放到调用.getDataStream()之前
消费多个Topic
配置消费多个topic也很简单,在配置文件topic下配置多个topic名称即可,用,或空格分隔,代码消费处理的时候指定topic参数即可,scala api下如果是消费一个topic,则直接传入topic名称即可,如果要消费多个,传入一个List即可
javaapi通过 topic()方法传入要消费topic的名称,是一个String类型的可变参数,可以传入一个或多个topic名称,配置和代码如下
- 配置
- Scala
- Java
kafka.source:
bootstrap.servers: kfk1:9092,kfk2:9092,kfk3:9092
topic: topic1,topic2,topic3...
group.id: user_01
auto.offset.reset: earliest # (earliest | latest)
...
//消费指定单个topic的数据
KafkaSource().getDataStream[String](topic = "topic1")
.uid("kfkSource1")
.name("kfkSource1")
.print()
//消费一批topic数据
KafkaSource().getDataStream[String](topic = List("topic1","topic2","topic3"))
.uid("kfkSource1")
.name("kfkSource1")
.print()
//消费指定单个topic的数据
DataStream<String> source1 = new KafkaSource<String>(context)
.topic("topic1")
.getDataStream()
.print();
//消费一组topic的数据
DataStream<String> source1 = new KafkaSource<String>(context)
.topic("topic1","topic2")
.getDataStream()
.print();
topic支持配置多个topic实例,每个topic直接用,分隔或者空格分隔,如果topic下配置多个实例,在消费的时必须指定具体的topic名称
Topic 发现
关于kafka的分区动态,默认情况下,是禁用了分区发现的。若要启用它,请在提供的属性配置中为 flink.partition-discovery.interval-millis 设置大于 0,表示发现分区的间隔是以毫秒为单位的
更多详情请参考官网文档
Flink Kafka Consumer 还能够使用正则表达式基于 Topic 名称的模式匹配来发现 Topic,详情请参考官网文档
在StreamPark中提供更简单的方式,具体需要在 pattern下配置要匹配的topic实例名称的正则即可
- 配置
- Scala
- Java
kafka.source:
bootstrap.servers: kfk1:9092,kfk2:9092,kfk3:9092
pattern: ^topic[1-9]
group.id: user_02
auto.offset.reset: earliest # (earliest | latest)
...
//消费正则topic数据
KafkaSource().getDataStream[String](topic = "topic-a")
.uid("kfkSource1")
.name("kfkSource1")
.print()
StreamEnvConfig envConfig = new StreamEnvConfig(args, null);
StreamingContext context = new StreamingContext(envConfig);
//消费通配符topic数据
new KafkaSource<String>(context)
.topic("topic-a")
.getDataStream()
.print();
context.start();
topic和pattern不能同时配置,当配置了pattern正则匹配时,在消费的时候依然可以指定一个确定的topic名称,此时会检查pattern是否匹配当前的topic,如不匹配则会报错
配置开始消费的位置
Flink Kafka Consumer 允许通过配置来确定 Kafka 分区的起始位置,官网文档Kafka 分区的起始位置具体操作方式如下
- scala
- Java
val env = StreamExecutionEnvironment.getExecutionEnvironment()
val myConsumer = new FlinkKafkaConsumer[String](...)
myConsumer.setStartFromEarliest() // 尽可能从最早的记录开始
myConsumer.setStartFromLatest() // 从最新的记录开始
myConsumer.setStartFromTimestamp(...) // 从指定的时间开始(毫秒)
myConsumer.setStartFromGroupOffsets() // 默认的方法
val stream = env.addSource(myConsumer)
...
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
FlinkKafkaConsumer<String> myConsumer = new FlinkKafkaConsumer<>(...);
myConsumer.setStartFromEarliest(); // 尽可能从最早的记录开始
myConsumer.setStartFromLatest(); // 从最新的记录开始
myConsumer.setStartFromTimestamp(...); // 从指定的时间开始(毫秒)
myConsumer.setStartFromGroupOffsets(); // 默认的方法
DataStream<String> stream = env.addSource(myConsumer);
...
在StreamPark中不推荐这种方式进行设定,提供了更方便的方式,只需要在配置里指定 auto.offset.reset 即可
earliest从最早的记录开始latest从最新的记录开始
指定分区Offset
你也可以为每个分区指定 consumer 应该开始消费的具体 offset,只需要按照如下的配置文件配置start.from相关的信息即可
kafka.source:
bootstrap.servers: kfk1:9092,kfk2:9092,kfk3:9092
topic: topic1,topic2,topic3...
group.id: user_01
auto.offset.reset: earliest # (earliest | latest)
start.from:
timestamp: 1591286400000 #指定timestamp,针对所有的topic生效
offset: # 给topic的partition指定offset
topic: topic_abc,topic_123
topic_abc: 0:182,1:183,2:182 #分区0从182开始消费,分区1从183开始,分区2从182开始...
topic_123: 0:182,1:183,2:182
...
指定deserializer
默认不指定deserializer则在内部采用String的方式反序列化topic中的数据,可以手动指定deserializer,这样可以一步直接返回目标DataStream,具体完整代码如下
- Scala
- Java
import org.apache.streampark.common.util.JsonUtils
import org.apache.streampark.flink.core.scala.FlinkStreaming
import org.apache.streampark.flink.core.scala.sink.JdbcSink
import org.apache.streampark.flink.core.scala.source.KafkaSource
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.java.typeutils.TypeExtractor.getForClass
import org.apache.flink.api.scala._
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema
object KafkaSourceApp extends FlinkStreaming {
override def handle(): Unit = {
KafkaSource()
.getDataStream[String](deserializer = new UserSchema)
.map(_.value)
.print()
}
}
class UserSchema extends KafkaDeserializationSchema[User] {
override def isEndOfStream(nextElement: User): Boolean = false
override def getProducedType: TypeInformation[User] = getForClass(classOf[User])
override def deserialize(record: ConsumerRecord[Array[Byte], Array[Byte]]): User = {
val value = new String(record.value())
JsonUtils.read[User](value)
}
}
case class User(name:String,age:Int,gender:Int,address:String)
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
import org.apache.streampark.flink.core.java.source.KafkaSource;
import org.apache.streampark.flink.core.scala.StreamingContext;
import org.apache.streampark.flink.core.scala.source.KafkaRecord;
import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import java.io.Serializable;
import static org.apache.flink.api.java.typeutils.TypeExtractor.getForClass;
public class KafkaSourceJavaApp {
public static void main(String[] args) {
StreamEnvConfig envConfig = new StreamEnvConfig(args, null);
StreamingContext context = new StreamingContext(envConfig);
new KafkaSource<JavaUser>(context)
.deserializer(new JavaUserSchema())
.getDataStream()
.map((MapFunction<KafkaRecord<JavaUser>, JavaUser>) KafkaRecord::value)
.print();
context.start();
}
}
class JavaUserSchema implements KafkaDeserializationSchema<JavaUser> {
private ObjectMapper mapper = new ObjectMapper();
@Override public boolean isEndOfStream(JavaUser nextElement) return false;
@Override public TypeInformation<JavaUser> getProducedType() return getForClass(JavaUser.class);
@Override public JavaUser deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception {
String value = new String(record.value());
return mapper.readValue(value, JavaUser.class);
}
}
class JavaUser implements Serializable {
String name;
Integer age;
Integer gender;
String address;
}
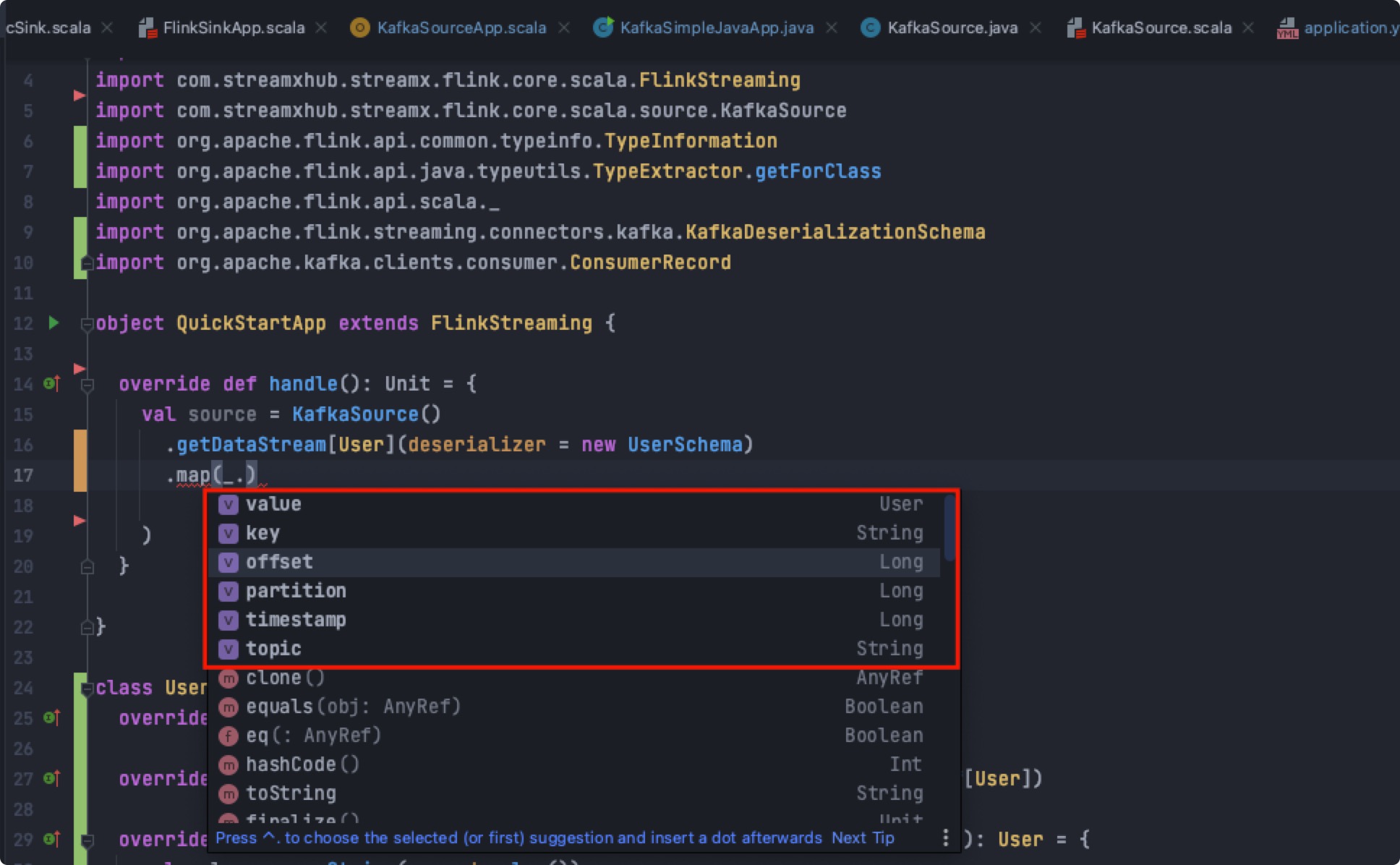
返回记录KafkaRecord
返回的对象被包装在KafkaRecord中,kafkaRecord中有当前的offset,partition,timestamp等诸多有用的信息供开发者使用,其中value即返回的目标对象,如下图:
指定strategy
在许多场景中,记录的时间戳是(显式或隐式)嵌入到记录本身中。此外,用户可能希望定期或以不规则的方式Watermark,例如基于Kafka流中包含当前事件时间的watermark的特殊记录。对于这些情况,Flink Kafka Consumer是允许指定AssignerWithPeriodicWatermarks或AssignerWithPunctuatedWatermarks
在StreamPark中运行传入一个WatermarkStrategy作为参数来分配Watermark,如下面的示例,解析topic中的数据为user对象,user中有个 orderTime 是时间类型,我们以这个为基准,为其分配一个Watermark
- Scala
- Java
import org.apache.streampark.common.util.JsonUtils
import org.apache.streampark.flink.core.scala.FlinkStreaming
import org.apache.streampark.flink.core.scala.source.{KafkaRecord, KafkaSource}
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, WatermarkStrategy}
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.java.typeutils.TypeExtractor.getForClass
import org.apache.flink.api.scala._
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema
import org.apache.kafka.clients.consumer.ConsumerRecord
import java.time.Duration
import java.util.Date
object KafkaSourceStrategyApp extends FlinkStreaming {
override def handle(): Unit = {
KafkaSource()
.getDataStream[User](
deserializer = new UserSchema,
strategy = WatermarkStrategy
.forBoundedOutOfOrderness[KafkaRecord[User]](Duration.ofMinutes(1))
.withTimestampAssigner(new SerializableTimestampAssigner[KafkaRecord[User]] {
override def extractTimestamp(element: KafkaRecord[User], recordTimestamp: Long): Long = {
element.value.orderTime.getTime
}
})
).map(_.value)
.print()
}
}
class UserSchema extends KafkaDeserializationSchema[User] {
override def isEndOfStream(nextElement: User): Boolean = false
override def getProducedType: TypeInformation[User] = getForClass(classOf[User])
override def deserialize(record: ConsumerRecord[Array[Byte], Array[Byte]]): User = {
val value = new String(record.value())
JsonUtils.read[User](value)
}
}
case class User(name: String, age: Int, gender: Int, address: String, orderTime: Date)
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
import org.apache.streampark.flink.core.java.source.KafkaSource;
import org.apache.streampark.flink.core.scala.StreamingContext;
import org.apache.streampark.flink.core.scala.source.KafkaRecord;
import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import java.io.Serializable;
import java.time.Duration;
import java.util.Date;
import static org.apache.flink.api.java.typeutils.TypeExtractor.getForClass;
/**
* @author benjobs
*/
public class KafkaSourceStrategyJavaApp {
public static void main(String[] args) {
StreamEnvConfig envConfig = new StreamEnvConfig(args, null);
StreamingContext context = new StreamingContext(envConfig);
new KafkaSource<JavaUser>(context)
.deserializer(new JavaUserSchema())
.strategy(
WatermarkStrategy.<KafkaRecord<JavaUser>>forBoundedOutOfOrderness(Duration.ofMinutes(1))
.withTimestampAssigner(
(SerializableTimestampAssigner<KafkaRecord<JavaUser>>)
(element, recordTimestamp) -> element.value().orderTime.getTime()
)
)
.getDataStream()
.map((MapFunction<KafkaRecord<JavaUser>, JavaUser>) KafkaRecord::value)
.print();
context.start();
}
}
class JavaUserSchema implements KafkaDeserializationSchema<JavaUser> {
private ObjectMapper mapper = new ObjectMapper();
@Override public boolean isEndOfStream(JavaUser nextElement) return false;
@Override public TypeInformation<JavaUser> getProducedType() return getForClass(JavaUser.class);
@Override public JavaUser deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception {
String value = new String(record.value());
return mapper.readValue(value, JavaUser.class);
}
}
class JavaUser implements Serializable {
String name;
Integer age;
Integer gender;
String address;
Date orderTime;
}
如果watermark assigner依赖于从Kafka读取的消息来上涨其watermark(通常就是这种情况),那么所有主题和分区都需要有连续的消息流。否则, 整个应用程序的watermark将无法上涨 ,所有基于时间的算子(例如时间窗口或带有计时器的函数)也无法运行。单个的Kafka分区也会导致这种反应。考虑设置适当的 idelness timeouts 来缓解这个问题。
Kafka Sink (Producer)
在StreamPark中Kafka Producer 被称为KafkaSink,它允许将消息写入一个或多个Kafka topic中
- Scala
- Java
val source = KafkaSource().getDataStream[String]().map(_.value)
KafkaSink().sink(source)
StreamEnvConfig envConfig = new StreamEnvConfig(args, null);
StreamingContext context = new StreamingContext(envConfig);
DataStream<String> source = new KafkaSource<String>(context)
.getDataStream()
.map((MapFunction<KafkaRecord<String>, String>) KafkaRecord::value);
new KafkaSink<String>(context).sink(source);
context.start();
sink是具体的写入数据的方法,参数列表如下
| 参数名 | 参数类型 | 作用 | 默认值 | 必须 |
|---|---|---|---|---|
stream | DataStream[T] | 要写的数据流 | 无 | yes |
alias | String | kafka的实例别名 | 无 | no |
serializationSchema | SerializationSchema[T] | 写入的序列化器 | SimpleStringSchema | no |
partitioner | FlinkKafkaPartitioner[T] | kafka分区器 | KafkaEqualityPartitioner[T] | no |
容错和语义
启用 Flink 的 checkpointing 后,KafkaSink 可以提供精确一次的语义保证,具体开启checkpointing的设置请参考第二章关于项目配置部分
除了启用 Flink 的 checkpointing,你也可以通过将适当的 semantic 参数传递给 KafkaSink 来选择三种不同的操作模式
- EXACTLY_ONCE 使用 Kafka 事务提供精确一次语义
- AT_LEAST_ONCE 至少一次,可以保证不会丢失任何记录(但是记录可能会重复)
- NONE Flink 不会有任何语义的保证,产生的记录可能会丢失或重复
具体操作如下,只需要在kafka.sink下配置semantic即可
kafka.sink:
bootstrap.servers: kfk1:9092,kfk2:9092,kfk3:9092
topic: kfk_sink
transaction.timeout.ms: 1000
semantic: AT_LEAST_ONCE # EXACTLY_ONCE|AT_LEAST_ONCE|NONE
batch.size: 1
kafka EXACTLY_ONCE 语义说明
Semantic.EXACTLY_ONCE模式依赖于事务提交的能力。事务提交发生于触发 checkpoint 之前,以及从 checkpoint 恢复之后。如果从 Flink 应用程序崩溃到完全重启的时间超过了 Kafka 的事务超时时间,那么将会有数据丢失(Kafka 会自动丢弃超出超时时间的事务)。考虑到这一点,请根据预期的宕机时间来合理地配置事务超时时间。
默认情况下,Kafka broker 将 transaction.max.timeout.ms 设置为 15 分钟。此属性不允许为大于其值的 producer 设置事务超时时间。 默认情况下,FlinkKafkaProducer 将 producer config 中的 transaction.timeout.ms 属性设置为 1 小时,因此在使用 Semantic.EXACTLY_ONCE 模式之前应该增加 transaction.max.timeout.ms 的值。
在 KafkaConsumer 的 read_committed 模式中,任何未结束(既未中止也未完成)的事务将阻塞来自给定 Kafka topic 的未结束事务之后的所有读取数据。 换句话说,在遵循如下一系列事件之后:
- 用户启动了 transaction1 并使用它写了一些记录
- 用户启动了 transaction2 并使用它编写了一些其他记录
- 用户提交了 transaction2
即使 transaction2 中的记录已提交,在提交或中止 transaction1 之前,消费者也不会看到这些记录。这有 2 层含义:
- 首先,在 Flink 应用程序的正常工作期间,用户可以预料 Kafka 主题中生成的记录的可见性会延迟,相当于已完成 checkpoint 之间的平均时间。
- 其次,在 Flink 应用程序失败的情况下,此应用程序正在写入的供消费者读取的主题将被阻塞,直到应用程序重新启动或配置的事务超时时间过去后,才恢复正常。此标注仅适用于有多个 agent 或者应用程序写入同一 Kafka 主题的情况。
注意:Semantic.EXACTLY_ONCE 模式为每个 FlinkKafkaProducer 实例使用固定大小的 KafkaProducer 池。每个 checkpoint 使用其中一个 producer。如果并发 checkpoint 的数量超过池的大小,FlinkKafkaProducer 将抛出异常,并导致整个应用程序失败。请合理地配置最大池大小和最大并发 checkpoint 数量。
注意:Semantic.EXACTLY_ONCE 会尽一切可能不留下任何逗留的事务,否则会阻塞其他消费者从这个 Kafka topic 中读取数据。但是,如果 Flink 应用程序在第一次 checkpoint 之前就失败了,那么在重新启动此类应用程序后,系统中不会有先前池大小(pool size)相关的信息。因此,在第一次 checkpoint 完成前对 Flink 应用程序进行缩容,且并发数缩容倍数大于安全系数 FlinkKafkaProducer.SAFE_SCALE_DOWN_FACTOR 的值的话,是不安全的。
多实例kafka指定alias
如果写时有多个不同实例的kafka需要配置,同样采用alias来区别不用的kafka实例,配置如下:
kafka.sink:
kafka_cluster1:
bootstrap.servers: kfk1:9092,kfk2:9092,kfk3:9092
topic: kfk_sink
transaction.timeout.ms: 1000
semantic: AT_LEAST_ONCE # EXACTLY_ONCE|AT_LEAST_ONCE|NONE
batch.size: 1
kafka_cluster2:
bootstrap.servers: kfk6:9092,kfk7:9092,kfk8:9092
topic: kfk_sink
transaction.timeout.ms: 1000
semantic: AT_LEAST_ONCE # EXACTLY_ONCE|AT_LEAST_ONCE|NONE
batch.size: 1
在写入的时候,需要手动指定alias,注意下scala api和java api在代码上稍有不同,scala直接在sink方法里指定参数,java api则是通过alias()方法来设置,其底层实现是完全一致的
- Scala
- Java
val source = KafkaSource().getDataStream[String]().map(_.value)
KafkaSink().sink(source,alias = "kafka_cluster1")
StreamEnvConfig envConfig = new StreamEnvConfig(args, null);
StreamingContext context = new StreamingContext(envConfig);
DataStream<String> source = new KafkaSource<String>(context)
.getDataStream()
.map((MapFunction<KafkaRecord<String>, String>) KafkaRecord::value);
new KafkaSink<String>(context).alias("kafka_cluster1").sink(source);
context.start();
指定SerializationSchema
Flink Kafka Producer 需要知道如何将 Java/Scala 对象转化为二进制数据。 KafkaSerializationSchema 允许用户指定这样的schema, 相关操作方式和文档请参考官网文档
在KafkaSink里默认不指定序列化方式,采用的是SimpleStringSchema来进行序列化,这里开发者可以显示的指定一个自定义的序列化器,通过serializationSchema参数指定即可,例如,将user对象安装自定义的格式写入kafka
- Scala
- Java
import org.apache.streampark.common.util.JsonUtils
import org.apache.streampark.flink.core.scala.FlinkStreaming
import org.apache.flink.api.common.serialization.SerializationSchema
import org.apache.streampark.flink.core.scala.sink.JdbcSink
import org.apache.streampark.flink.core.scala.source.KafkaSource
import org.apache.flink.api.scala._
object KafkaSinkApp extends FlinkStreaming {
override def handle(): Unit = {
val source = KafkaSource()
.getDataStream[String]()
.map(x => JsonUtils.read[User](x.value))
KafkaSink().sink[User](source, serialization = new SerializationSchema[User]() {
override def serialize(user: User): Array[Byte] = {
s"${user.name},${user.age},${user.gender},${user.address}".getBytes
}
})
}
}
case class User(name: String, age: Int, gender: Int, address: String)
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
import org.apache.streampark.flink.core.java.sink.KafkaSink;
import org.apache.streampark.flink.core.java.source.KafkaSource;
import org.apache.streampark.flink.core.scala.StreamingContext;
import org.apache.streampark.flink.core.scala.source.KafkaRecord;
import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import java.io.Serializable;
public class kafkaSinkJavaApp {
public static void main(String[] args) {
StreamEnvConfig envConfig = new StreamEnvConfig(args, null);
StreamingContext context = new StreamingContext(envConfig);
ObjectMapper mapper = new ObjectMapper();
DataStream<JavaUser> source = new KafkaSource<String>(context)
.getDataStream()
.map((MapFunction<KafkaRecord<String>, JavaUser>) value ->
mapper.readValue(value.value(), JavaUser.class));
new KafkaSink<JavaUser>(context)
.serializer(
(SerializationSchema<JavaUser>) element ->
String.format("%s,%d,%d,%s", element.name, element.age, element.gender, element.address).getBytes()
).sink(source);
context.start();
}
}
class JavaUser implements Serializable {
String name;
Integer age;
Integer gender;
String address;
}
指定SerializationSchema
Flink Kafka Producer 需要知道如何将 Java/Scala 对象转化为二进制数据。 KafkaSerializationSchema 允许用户指定这样的schema, 相关操作方式和文档请参考官网文档
在KafkaSink里默认不指定序列化方式,采用的是SimpleStringSchema来进行序列化,这里开发者可以显示的指定一个自定义的序列化器,通过serializationSchema参数指定即可,例如,将user对象安装自定义的格式写入kafka
- Scala
- Java
import org.apache.streampark.common.util.JsonUtils
import org.apache.streampark.flink.core.scala.FlinkStreaming
import org.apache.flink.api.common.serialization.SerializationSchema
import org.apache.streampark.flink.core.scala.sink.JdbcSink
import org.apache.streampark.flink.core.scala.source.KafkaSource
import org.apache.flink.api.scala._
object KafkaSinkApp extends FlinkStreaming {
override def handle(): Unit = {
val source = KafkaSource()
.getDataStream[String]()
.map(x => JsonUtils.read[User](x.value))
KafkaSink().sink[User](source, serialization = new SerializationSchema[User]() {
override def serialize(user: User): Array[Byte] = {
s"${user.name},${user.age},${user.gender},${user.address}".getBytes
}
})
}
}
case class User(name: String, age: Int, gender: Int, address: String)
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.streampark.flink.core.java.function.StreamEnvConfigFunction;
import org.apache.streampark.flink.core.java.sink.KafkaSink;
import org.apache.streampark.flink.core.java.source.KafkaSource;
import org.apache.streampark.flink.core.scala.StreamingContext;
import org.apache.streampark.flink.core.scala.source.KafkaRecord;
import org.apache.streampark.flink.core.scala.util.StreamEnvConfig;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import java.io.Serializable;
public class kafkaSinkJavaApp {
public static void main(String[] args) {
StreamEnvConfig envConfig = new StreamEnvConfig(args, null);
StreamingContext context = new StreamingContext(envConfig);
ObjectMapper mapper = new ObjectMapper();
DataStream<JavaUser> source = new KafkaSource<String>(context)
.getDataStream()
.map((MapFunction<KafkaRecord<String>, JavaUser>) value ->
mapper.readValue(value.value(), JavaUser.class));
new KafkaSink<JavaUser>(context)
.serializer(
(SerializationSchema<JavaUser>) element ->
String.format("%s,%d,%d,%s", element.name, element.age, element.gender, element.address).getBytes()
).sink(source);
context.start();
}
}
class JavaUser implements Serializable {
String name;
Integer age;
Integer gender;
String address;
}
指定partitioner
KafkaSink允许显示的指定一个kafka分区器,不指定默认使用StreamPark内置的 KafkaEqualityPartitioner 分区器,顾名思义,该分区器可以均匀的将数据写到各个分区中去,scala api是通过partitioner参数来设置分区器,
java api中是通过partitioner()方法来设置的
Flink Kafka Connector中默认使用的是 FlinkFixedPartitioner 分区器,该分区器需要特别注意sink的并行度和kafka的分区数,不然会出现往一个分区写