快速开始
如何使用
在上个章节已经详细介绍了一站式平台 streampark-console 的安装, 本章节看看如果用 streampark-console 快速部署运行一个作业, streampark-console 对标准的 Flink 程序 ( 按照 Flink 官方要求的结构和规范 ) 和用 streampark 开发的项目都做了很好的支持,下面我们使用 streampark-quickstart 来快速开启 streampark-console 之旅
streampark-quickstart 是 StreamPark 开发 Flink 的上手示例程序,具体请查阅:
部署 DataStream 任务
下面的示例演示了如何部署一个 DataStream 应用
部署 FlinkSql 任务
下面的示例演示了如何部署一个 FlinkSql 应用
- 项目演示使用到的 flink sql 如下
CREATE TABLE user_log (
user_id VARCHAR,
item_id VARCHAR,
category_id VARCHAR,
behavior VARCHAR,
ts TIMESTAMP(3)
) WITH (
'connector.type' = 'kafka', -- 使用 kafka connector
'connector.version' = 'universal', -- kafka 版本,universal 支持 0.11 以上的版本
'connector.topic' = 'user_behavior', -- kafka topic
'connector.properties.bootstrap.servers'='kafka-1:9092,kafka-2:9092,kafka-3:9092',
'connector.startup-mode' = 'earliest-offset', -- 从起始 offset 开始读取
'update-mode' = 'append',
'format.type' = 'json', -- 数据源格式为 json
'format.derive-schema' = 'true' -- 从 DDL schema 确定 json 解析规则
);
CREATE TABLE pvuv_sink (
dt VARCHAR,
pv BIGINT,
uv BIGINT
) WITH (
'connector.type' = 'jdbc', -- 使用 jdbc connector
'connector.url' = 'jdbc:mysql://test-mysql:3306/test', -- jdbc url
'connector.table' = 'pvuv_sink', -- 表名
'connector.username' = 'root', -- 用户名
'connector.password' = '123456', -- 密码
'connector.write.flush.max-rows' = '1' -- 默认 5000 条,为了演示改为 1 条
);
INSERT INTO pvuv_sink
SELECT
DATE_FORMAT(ts, 'yyyy-MM-dd HH:00') dt,
COUNT(*) AS pv,
COUNT(DISTINCT user_id) AS uv
FROM user_log
GROUP BY DATE_FORMAT(ts, 'yyyy-MM-dd HH:00');
- 使用到 maven 依赖如下
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.48</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-kafka_2.11</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>1.12.0</version>
</dependency>
- Kafka 模拟发送的数据如下
{"user_id": "543462", "item_id":"1715", "category_id": "1464116", "behavior": "pv", "ts":"2021-02-01T01:00:00Z"}
{"user_id": "662867", "item_id":"2244074","category_id":"1575622","behavior": "pv", "ts":"2021-02-01T01:00:00Z"}
{"user_id": "662867", "item_id":"2244074","category_id":"1575622","behavior": "pv", "ts":"2021-02-01T01:00:00Z"}
{"user_id": "662867", "item_id":"2244074","category_id":"1575622","behavior": "learning flink", "ts":"2021-02-01T01:00:00Z"}
任务启动流程
任务启动流程图如下
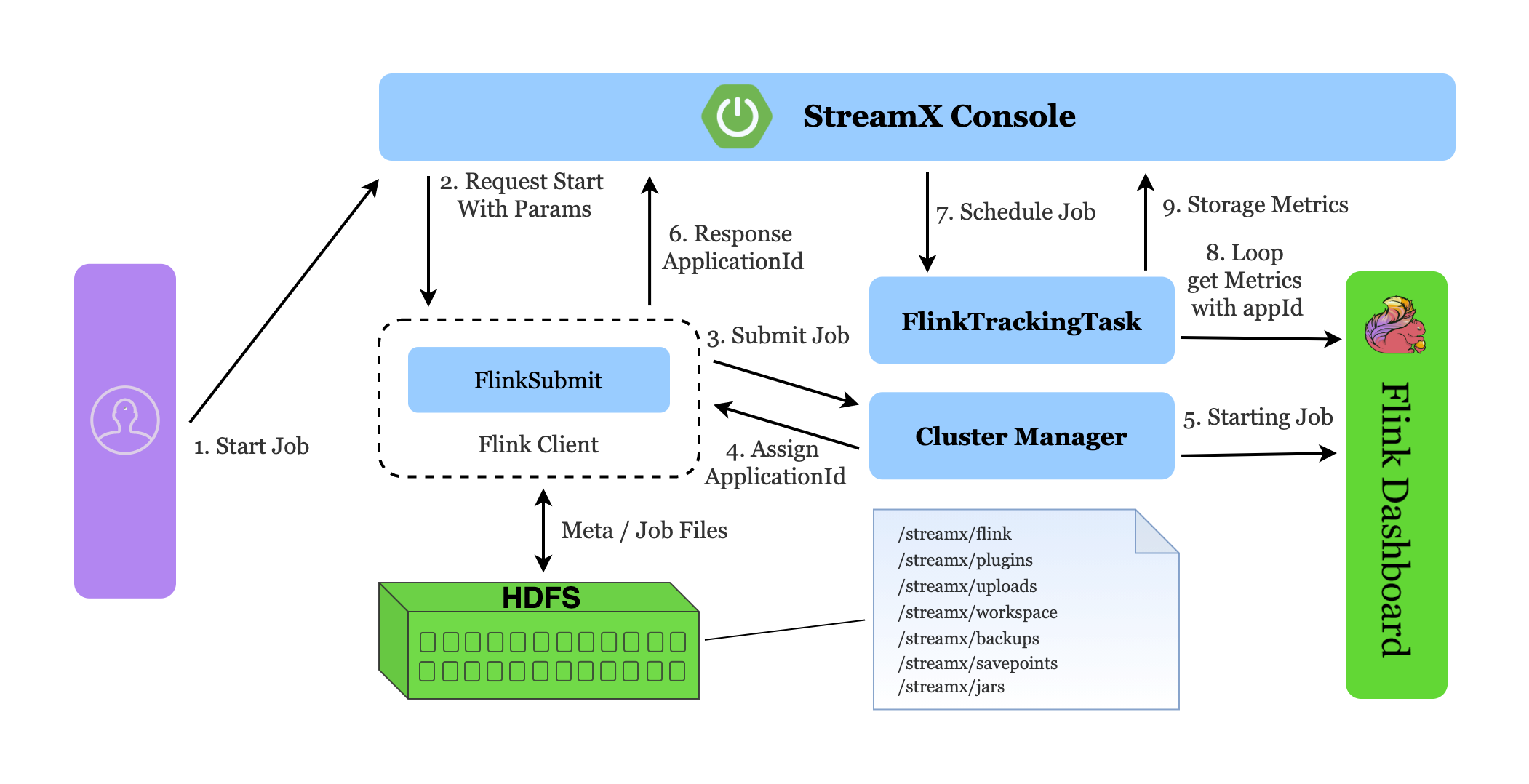
streampark-console 提交任务流程
关于项目的概念,Development Mode,savepoint,NoteBook,自定义 jar 管理,任务发布,任务恢复,参数配置,参数对比,多版本管理等等更多使用教程和文档后续持续更新。..