Apache StreamPark™
一个神奇的框架,让流处理更简单!
🚀 什么是 Apache StreamPark™
实时即未来,在实时处理流域 Apache Spark 和 Apache Flink 是一个伟大的进步,尤其是 Flink 被普遍认为是下一代大数据流计算引擎。
在使用 Flink 和 Spark 时,我们发现从编程模型, 启动配置到运维管理都有很多可以抽象共用的地方。于是,我们将一些好的经验固化下来并结合业内的最佳实践, 通过不断努力诞生了今天的框架:Apache StreamPark。项目的初衷是:让流处理更简单!
使用 StreamPark 开发流处理作业, 可以极大降低学习成本和开发门槛, 让开发者只用关心最核心的业务,StreamPark 规范了项目的配置、鼓励函数式编程、定义了最佳的编程方式,提供了一系列开箱即用的连接器(Connector),标准化了配置、开发、测试、部署、监控、运维的整个过程,提供了 Scala 和 Java 两套接口,并且提供了一个一站式的流处理作业开发管理平台,从流处理作业开发到上线全生命周期都做了支持,是一个一站式的流处理计算平台。
🎉 Features
- Flink 和 Spark 应用程序开发脚手架
- 支持多个版本的 Flink 和 Spark
- 一系列开箱即用的连接器
- 一站式流处理运营平台
- 支持 Catalog / OLAP / Streaming Warehouse 等场景
- ...
🏳🌈 组成部分
Apache StreamPark 核心由 streampark-core 和 streampark-console 组成:
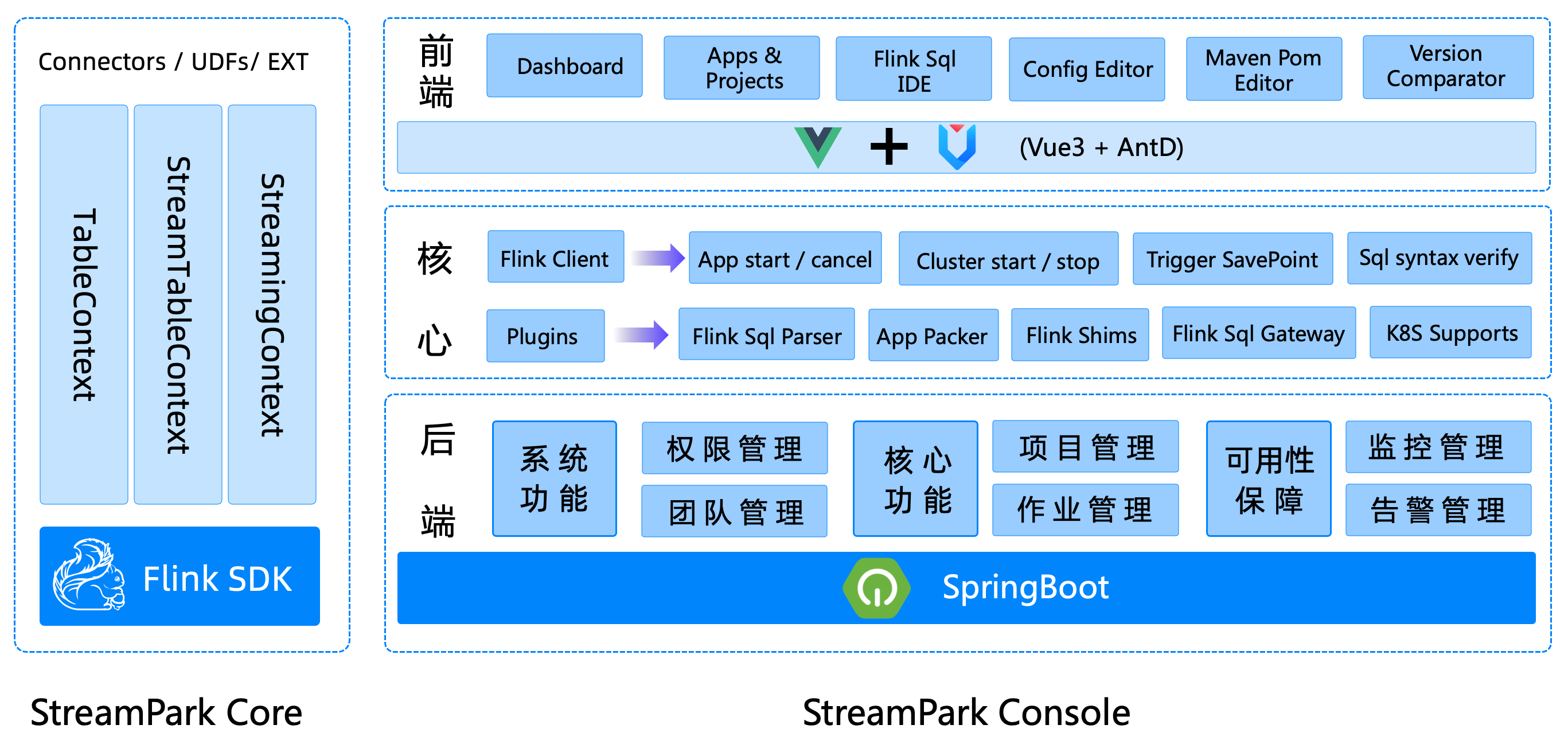
1️⃣ streampark-core
streampark-core 定位是一个开发时框架,关注编码开发,规范了配置文件,按照约定优于配置的方式进行开发,提供了一个开发环境的 RuntimeContext 和一系列开箱即用的连接器,扩展了 DataStream 相关的方法,融合了 DataStream 和 Flink SQL API,简化繁琐的操作、聚焦业务本身,提高开发效率和开发体验。
2️⃣ streampark-console
streampark-console 是一个综合实时数据平台、低代码平台,可以较好的管理 Flink 任务,集成了项目编译、发布、参数配置、启动、保存点、火焰图、Flink SQL 和监控等诸多功能于一体,大大简化了 Flink 任务的日常操作和维护,融合了诸多最佳实践。旧时王谢堂前燕,飞入寻常百姓家。让大公司有能力研发使用的项目,现在人人可以使用,其最终目标是打造成一个实时数仓,流批一体的一站式大数据解决方案,该平台使用了(但不仅限)以下技术:
- Apache Flink
- Apache Spark
- Apache YARN
- Spring Boot
- Mybatis
- Mybatis-Plus
- Vue
- VuePress
- Ant Design of Vue
- ANTD PRO VUE
- xterm.js
- Monaco Editor
- ...
感谢以上优秀的开源项目和很多未提到的优秀开源项目,给予最大的 respect!