编程模型
任何框架都有一些要遵循的规则和约定, 我们只有遵循并掌握了这些规则, 才能更加游刃有余的使用, 使其发挥事半功倍的效果, 我们开发 Flink 作业,其实就是利用 Flink 提供的 API , 按照 Flink 要求的开发方式, 写一个可以执行的(必须有main()函数)的程序, 在程序里接入各种Connector经过一系列的算子操作, 最终将数据通过Connector sink 到目标存储,
我们把这种按照某种约定的规则去逐步编程的方式称之为编程模型, 这一章节我们就来聊聊 StreamPark 的编程模型以及开发注意事项
我们从这几个方面开始入手
- 架构
- 编程模型
- RunTime Context
- 生命周期
- 目录结构
- 打包部署
架构
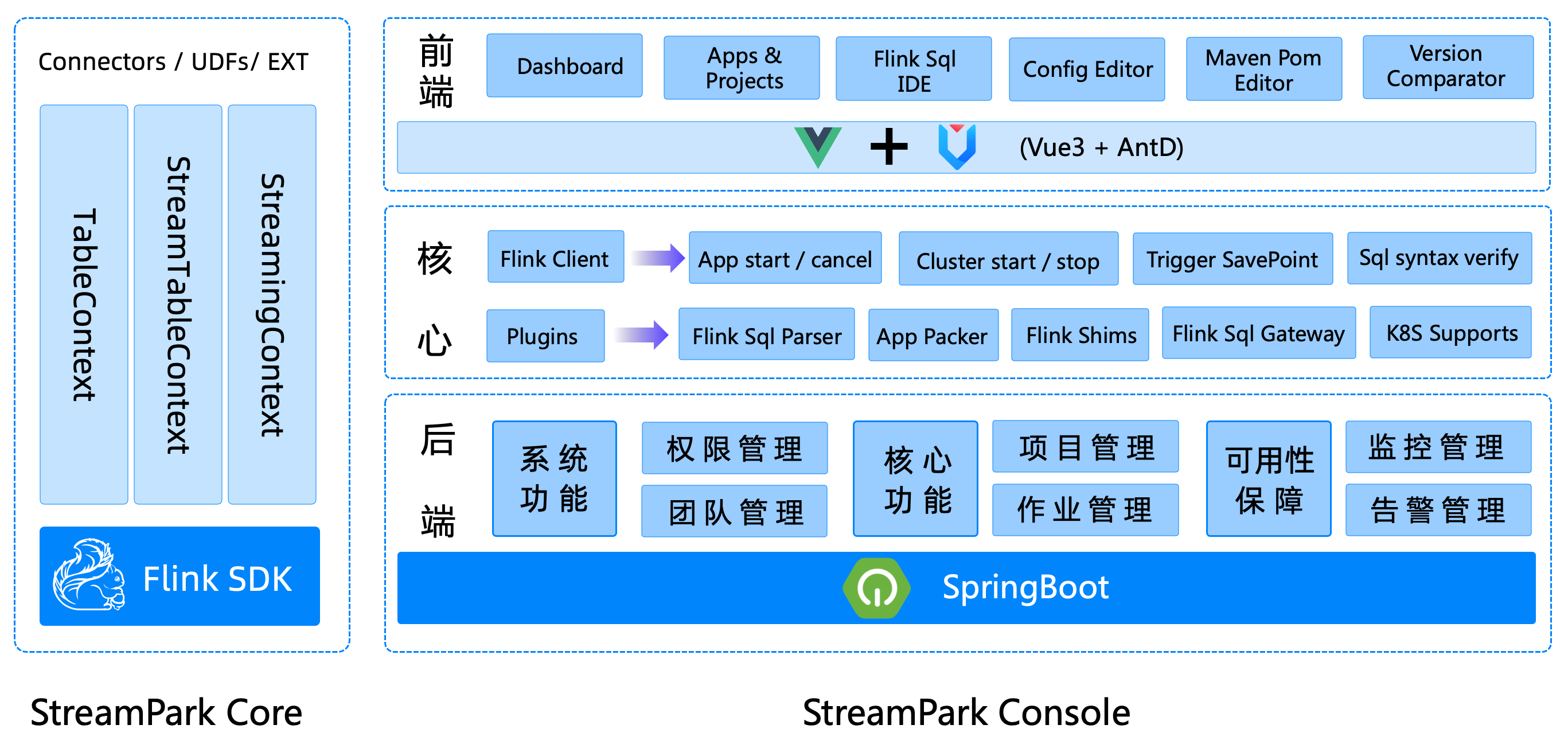
编程模型
streampark-core 定位是编程时框架,快速开发脚手架,专门为简化 Flink 开发而生,开发者在开发阶段会使用到该模块,下面我们来看看 DataStream 和 Flink Sql 用 StreamPark 来开发编程模型是什么样的,有什么规范和要求
DataStream
StreamPark 提供了scala和Java两种 API 来开发 DataStream 程序,具体代码开发如下
- Scala
- Java
import org.apache.streampark.flink.core.scala.FlinkStreaming
import org.apache.flink.api.scala._
object MyFlinkApp extends FlinkStreaming {
override def handle(): Unit = {
...
}
}
public class MyFlinkJavaApp {
public static void main(String[] args) {
StreamEnvConfig JavaConfig = new StreamEnvConfig(args, (environment, parameterTool) -> {
//用户可以给environment设置参数...
System.out.println("environment argument set...");
});
StreamingContext context = new StreamingContext(JavaConfig);
....
context.start();
}
}
用 scala API 开发,程序必须要继承 FlinkStreaming ,继承之后,会强制让开发者实现 handle() 方法,该方法就是用户写代码的入口, 同时 streamingContext 供开发者使用
用 Java API 开发由于语言本身的限制没法省掉 main() 方法,所以会是一个标准的 main() 函数, 需要用户手动创建 StreamingContext,StreamingContext 是非常重要的一个类,稍后会介绍
以上几行 scala 和 Java 代码就是用 StreamPark 开发 DataStream 必不可少的最基本的骨架代码,用 StreamPark 开发 DataStream 程序,从这几行代码开始, Java API 开发需要开发者手动启动任务 start
Flink Sql
TableEnvironment 是用来创建 Table & SQL 程序的上下文执行环境,也是 Table & SQL 程序的入口,Table & SQL 程序的所有功能都是围绕 TableEnvironment 这个核心类展开的。TableEnvironment 的主要职能包括:对接外部系统,表及元数据的注册和检索,执行 SQL 语句,提供更详细的配置选项。
Flink 社区一直在推进 DataStream 的批处理能力,统一流批一体,在 Flink 1.12 中流批一体真正统一运行,诸多历史 API 如: DataSet API, BatchTableEnvironment API 等被废弃,退出历史舞台,官方推荐使用 TableEnvironment 和 StreamTableEnvironment
StreamPark 针对 TableEnvironment 和 StreamTableEnvironment 这两种环境的开发,提供了对应的更方便快捷的 API
TableEnvironment
开发Table & SQL 作业, TableEnvironment 会是 Flink 推荐使用的入口类, 同时能支持 Java API 和 Scala API,下面的代码演示了在 StreamPark 如何开发一个 TableEnvironment 类型的作业
- Scala
- Java
import org.apache.streampark.flink.core.scala.FlinkTable
object TableApp extends FlinkTable {
override def handle(): Unit = {
...
}
}
import org.apache.streampark.flink.core.scala.TableContext;
import org.apache.streampark.flink.core.scala.util.TableEnvConfig;
public class JavaTableApp {
public static void main(String[] args) {
TableEnvConfig tableEnvConfig = new TableEnvConfig(args, null);
TableContext context = new TableContext(tableEnvConfig);
...
context.start("Flink SQl Job");
}
}
以上几行 Scala 和 Java 代码就是用 StreamPark 开发 TableEnvironment 必不可少的最基本的骨架代码,用 StreamPark 开发 TableEnvironment 程序,从这几行代码开始,
Scala API 必须继承 FlinkTable, Java API 开发需要手动构造 TableContext ,需要开发者手动启动任务 start
StreamTableEnvironment
StreamTableEnvironment 用于流计算场景,流计算的对象是 DataStream。相比 TableEnvironment, StreamTableEnvironment 提供了 DataStream 和 Table 之间相互转换的接口,如果用户的程序除了使用 Table API & SQL 编写外,还需要使用到 DataStream API,则需要使用 StreamTableEnvironment。
下面的代码演示了在 StreamPark 如何开发一个 StreamTableEnvironment 类型的作业
- Scala
- Java
package org.apache.streampark.test.tablesql
import org.apache.streampark.flink.core.scala.FlinkStreamTable
object StreamTableApp extends FlinkStreamTable {
override def handle(): Unit = {
...
}
}
import org.apache.streampark.flink.core.scala.StreamTableContext;
import org.apache.streampark.flink.core.scala.util.StreamTableEnvConfig;
public class JavaStreamTableApp {
public static void main(String[] args) {
StreamTableEnvConfig JavaConfig = new StreamTableEnvConfig(args, null, null);
StreamTableContext context = new StreamTableContext(JavaConfig);
...
context.start("Flink SQl Job");
}
}
以上几行 scala 和 Java 代码就是用 StreamPark 开发 StreamTableEnvironment 必不可少的最基本的骨架代码,用 StreamPark 开发 StreamTableEnvironment 程序,从这几行代码开始,Java 代码需要手动构造 StreamTableContext,Java API开发需要开发者手动启动任务start
RunTime Context
RunTime Context — StreamingContext , TableContext , StreamTableContext 是 StreamPark 中几个非常重要三个对象,接下来我们具体看看这三个 Context 的定义和作用
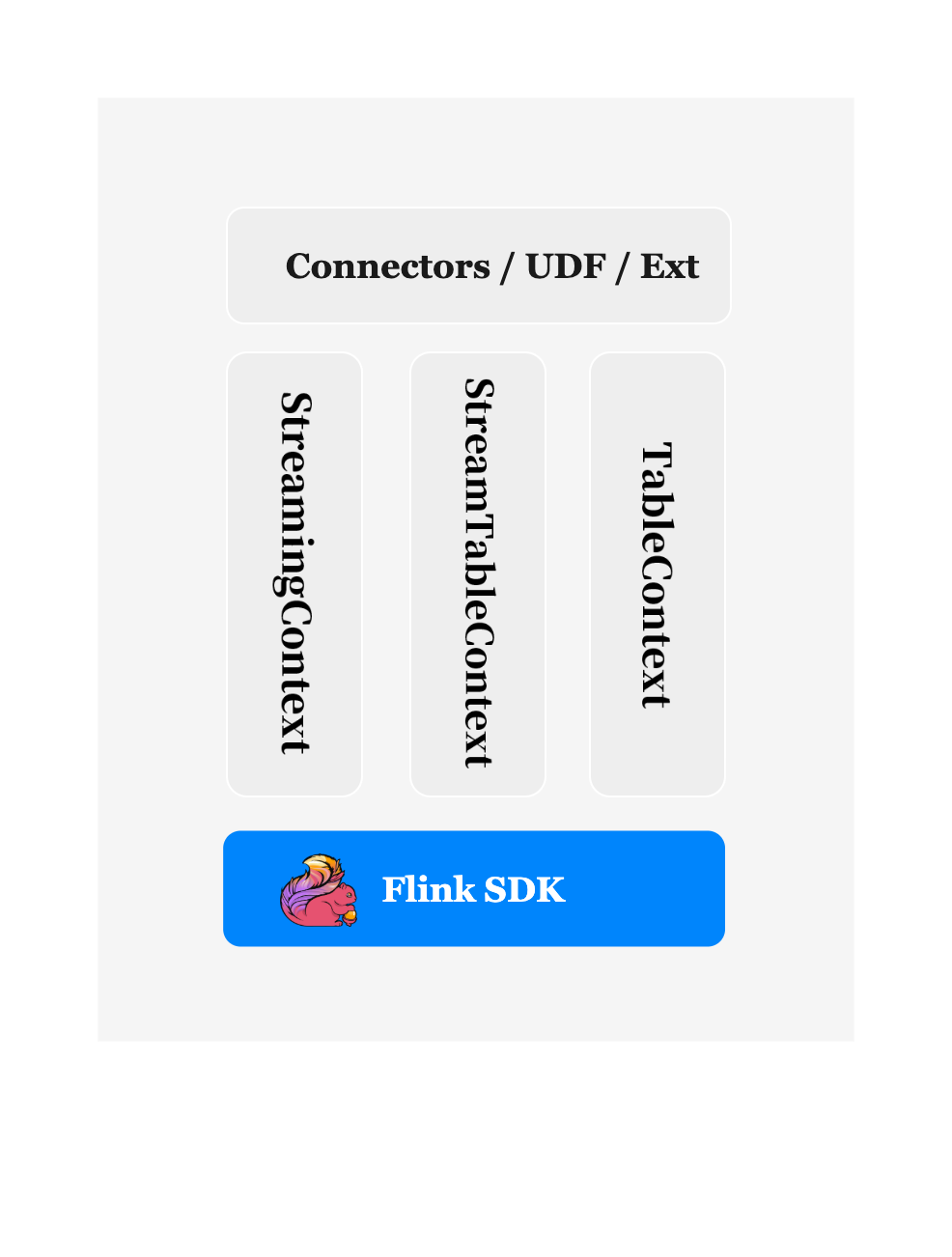
StreamingContext
StreamingContext 继承自 StreamExecutionEnvironment, 在 StreamExecutionEnvironment 的基础之上增加了 ParameterTool ,简单可以理解为:
StreamingContext = ParameterTool + StreamExecutionEnvironment
具体定义如下:
class StreamingContext(val parameter: ParameterTool, private val environment: StreamExecutionEnvironment)
extends StreamExecutionEnvironment(environment.getJavaEnv) {
/**
* for scala
*
* @param args
*/
def this(args: (ParameterTool, StreamExecutionEnvironment)) = this(args._1, args._2)
/**
* for Java
*
* @param args
*/
def this(args: StreamEnvConfig) = this(FlinkStreamingInitializer.initJavaStream(args))
...
}
这个对象非常重要,在 DataStream 作业中会贯穿整个任务的生命周期, StreamingContext 本身继承自 StreamExecutionEnvironment ,配置文件会完全融合到 StreamingContext 中,这样就可以非常方便的从 StreamingContext 中获取各种参数
在 StreamPark 中, StreamingContext 也是 Java API 编写 DataStream 作业的入口类, StreamingContext 的构造方法中有一个是专门为 Java API 打造的,该构造函数定义如下:
/**
* for Java
* @param args
*/
def this(args: StreamEnvConfig) = this(FlinkStreamingInitializer.initJavaStream(args))
由上面的构造方法可以看到创建 StreamingContext,需要传入一个 StreamEnvConfig 对象, StreamEnvConfig 定义如下:
class StreamEnvConfig(val args: Array[String], val conf: StreamEnvConfigFunction)
StreamEnvConfig的构造方法中,其中
args为启动参数,必须为main方法里的argsconf为StreamEnvConfigFunction类型的Function
StreamEnvConfigFunction 定义如下
@FunctionalInterface
public interface StreamEnvConfigFunction {
/**
* 用于初始化StreamExecutionEnvironment的时候,用于可以实现该函数,自定义要设置的参数...
*
* @param environment
* @param parameterTool
*/
void configuration(StreamExecutionEnvironment environment, ParameterTool parameterTool);
}
该Function的作用是让开发者可以通过钩子的方式设置更多的参数,会将 parameter (解析配置文件里所有的参数)和初始化好的 StreamExecutionEnvironment 对象传给开发者去完成更多的参数设置,如:
StreamEnvConfig JavaConfig = new StreamEnvConfig(args, (environment, parameterTool) -> {
System.out.println("environment argument set...");
environment.getConfig().enableForceAvro();
});
StreamingContext context = new StreamingContext(JavaConfig);
TableContext
TableContext 继承自 TableEnvironment ,在 TableEnvironment 的基础之上增加了 ParameterTool ,用来创建 Table & SQL 程序的上下文执行环境,简单可以理解为:
TableContext = ParameterTool + TableEnvironment
具体定义如下:
class TableContext(val parameter: ParameterTool,
private val tableEnv: TableEnvironment)
extends TableEnvironment
with FlinkTableTrait {
/**
* for scala
*
* @param args
*/
def this(args: (ParameterTool, TableEnvironment)) = this(args._1, args._2)
/**
* for Java
* @param args
*/
def this(args: TableEnvConfig) = this(FlinkTableInitializer.initJavaTable(args))
...
}
在 StreamPark 中,TableContext 也是 Java API 编写 TableEnvironment 类型的 Table Sql 作业的入口类,TableContext 的构造方法中有一个是专门为 Java API 打造的,该构造函数定义如下:
/**
* for Java
* @param args
*/
def this(args: TableEnvConfig) = this(FlinkTableInitializer.initJavaTable(args))
由上面的构造方法可以看到创建 TableContext,需要传入一个 TableEnvConfig 对象, TableEnvConfig 定义如下:
class TableEnvConfig(val args: Array[String], val conf: TableEnvConfigFunction)
TableEnvConfig的构造方法中,其中
args为启动参数,必须为main方法里的argsconf为TableEnvConfigFunction类型的Function
TableEnvConfigFunction 定义如下
@FunctionalInterface
public interface TableEnvConfigFunction {
/**
* 用于初始化TableEnvironment的时候,用于可以实现该函数,自定义要设置的参数...
*
* @param tableConfig
* @param parameterTool
*/
void configuration(TableConfig tableConfig, ParameterTool parameterTool);
}
该 Function 的作用是让开发者可以通过钩子的方式设置更多的参数,会将 parameter(解析配置文件里所有的参数)和初始化好的 TableEnvironment 中的 TableConfig 对象传给开发者去完成更多的参数设置,如:
TableEnvConfig config = new TableEnvConfig(args,(tableConfig,parameterTool)->{
tableConfig.setLocalTimeZone(ZoneId.of("Asia/Shanghai"));
});
TableContext context = new TableContext(config);
...
StreamTableContext
StreamTableContext 继承自 StreamTableEnvironment,用于流计算场景,流计算的对象是 DataStream, 相比 TableEnvironment, StreamTableEnvironment 提供了 DataStream 和 Table 之间相互转换的接口,
StreamTableContext 在 StreamTableEnvironment 的基础之上增加了 ParameterTool,又直接接入了 StreamTableEnvironment 的API,简单可以理解为:
StreamTableContext = ParameterTool + StreamTableEnvironment + StreamExecutionEnvironment
具体定义如下:
class StreamTableContext(val parameter: ParameterTool,
private val streamEnv: StreamExecutionEnvironment,
private val tableEnv: StreamTableEnvironment)
extends StreamTableEnvironment
with FlinkTableTrait {
/**
* 一旦 Table 被转化为 DataStream,
* 必须使用 StreamExecutionEnvironment 的 execute 方法执行该 DataStream 作业。
*/
private[scala] var isConvertedToDataStream: Boolean = false
/**
* for scala
*
* @param args
*/
def this(args: (ParameterTool, StreamExecutionEnvironment, StreamTableEnvironment)) =
this(args._1, args._2, args._3)
/**
* for Java
*
* @param args
*/
def this(args: StreamTableEnvConfig) = this(FlinkTableInitializer.initJavaStreamTable(args))
...
}
在StreamPark中,StreamTableContext 是 Java API 编写 StreamTableEnvironment 类型的 Table Sql 作业的入口类,StreamTableContext 的构造方法中有一个是专门为 Java API 打造的,该构造函数定义如下:
/**
* for Java
*
* @param args
*/
def this(args: StreamTableEnvConfig) = this(FlinkTableInitializer.initJavaStreamTable(args))
由上面的构造方法可以看到创建 StreamTableContext ,需要传入一个 StreamTableEnvConfig 对象,StreamTableEnvConfig 定义如下:
class StreamTableEnvConfig (
val args: Array[String],
val streamConfig: StreamEnvConfigFunction,
val tableConfig: TableEnvConfigFunction
)
StreamTableEnvConfig 的构造方法中有三个参数,其中
args为启动参数,必须为main方法里的argsstreamConfig为StreamEnvConfigFunction类型的FunctiontableConfig为TableEnvConfigFunction类型的Function
StreamEnvConfigFunction和TableEnvConfigFunction 定义上面已经讲过,这里不再赘述
该Function的作用是让开发者可以通过钩子的方式设置更多的参数,和上面其他参数设置不同的是,该Function提供了同时设置StreamExecutionEnvironment和TableEnvironment的机会 ,会将 parameter和初始化好的StreamExecutionEnvironment和TableEnvironment中的TableConfig对象传给开发者去完成更多的参数设置,如:
StreamTableEnvConfig JavaConfig = new StreamTableEnvConfig(args, (environment, parameterTool) -> {
environment.getConfig().enableForceAvro();
}, (tableConfig, parameterTool) -> {
tableConfig.setLocalTimeZone(ZoneId.of("Asia/Shanghai"));
});
StreamTableContext context = new StreamTableContext(JavaConfig);
...
在 StreamTableContext 中可以直接使用 StreamExecutionEnvironment 的 API, 以$打头的方法 都是 StreamExecutionEnvironment 的 API
生命周期
生命周期的概念目前只针对 scala API,该生命周期明确的定义了整个任务运行的全过程 ,但凡继承自 FlinkStreaming 或 FlinkTable 或 StreamingTable 就会按这个生命周期执行,生命周期的核心方法如下
final def main(args: Array[String]): Unit = {
init(args)
ready()
handle()
jobExecutionResult = context.start()
destroy()
}
private[this] def init(args: Array[String]): Unit = {
SystemPropertyUtils.setAppHome(KEY_APP_HOME, classOf[FlinkStreaming])
context = new StreamingContext(FlinkStreamingInitializer.initStream(args, config))
}
/**
* 用户可覆盖次方法...
*
*/
def ready(): Unit = {}
def config(env: StreamExecutionEnvironment, parameter: ParameterTool): Unit = {}
def handle(): Unit
def destroy(): Unit = {}
生命周期如下
- init 配置文件初始化阶段
- config 开发者手动设置参数阶段
- ready 启动之前执行自定义动作阶段
- handle 开发者代码接入阶段
- start 程序启动阶段
- destroy 销毁阶段
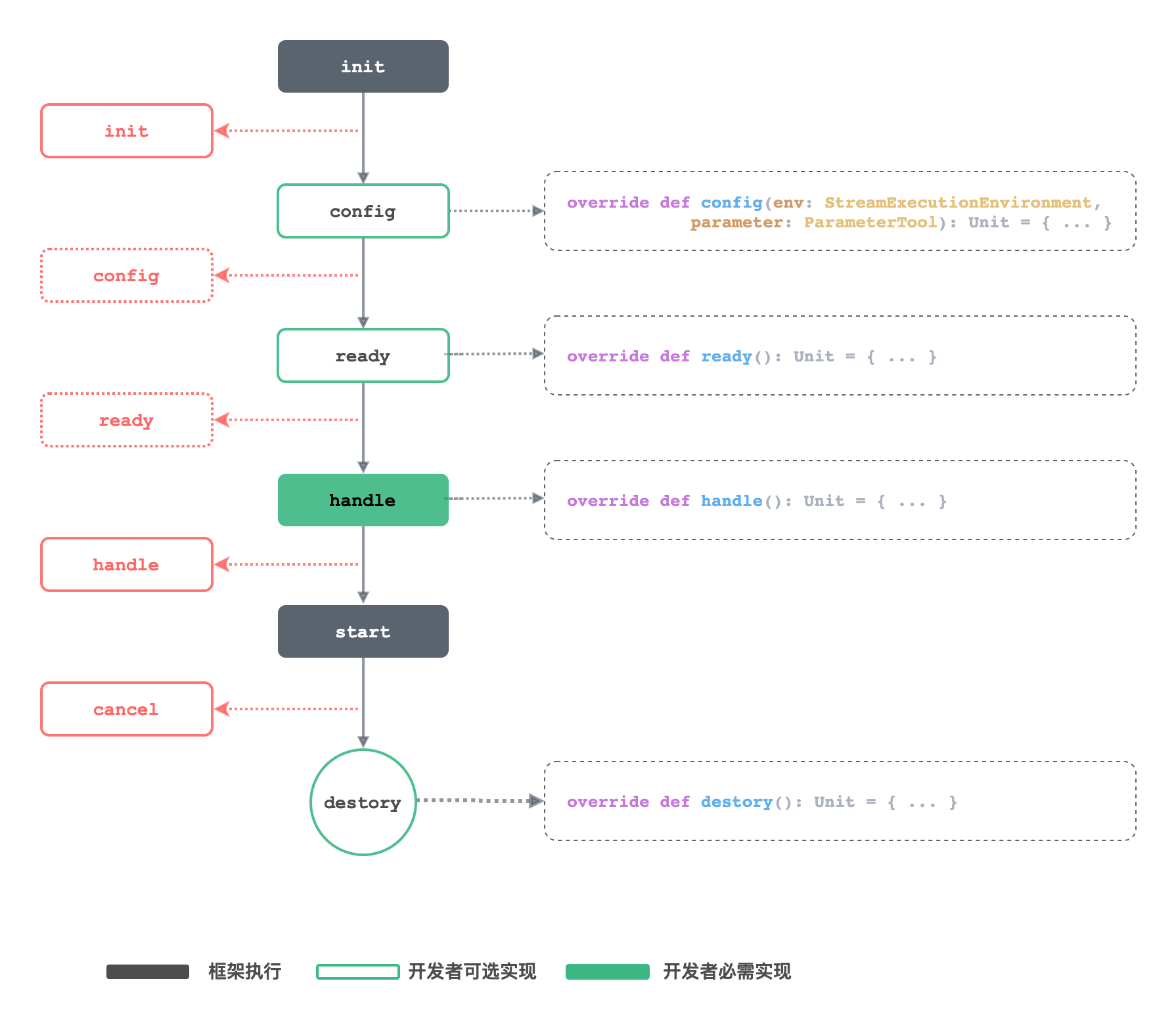
生命周期之 — init
init 阶段,框架会自动解析传入的配置文件,按照里面的定义的各种参数初始化StreamExecutionEnvironment,这一步是框架自动执行,不需要开发者参与
生命周期之 — config
config 阶段的目的是让开发者可以通过钩子的方式设置更多的参数(约定的配置文件以外的其他参数),在 config 阶段会将 parameter(init 阶段解析的配置文件里所有的参数)和init 阶段初始化好的StreamExecutionEnvironment对象传给开发者,
这样开发者就可以配置更多的参数
config 阶段是需要开发者参与的阶段,是可选的阶段
生命周期之 — ready
ready 阶段是在参数都设置完毕了,给开发者提供的一个用于做其他动作的入口, 该阶段是在初始化完成之后在程序启动之前进行
ready 阶段是需要开发者参与的阶段,是可选的阶段
生命周期之 — handle
handle 阶段是接入开发者编写的代码的阶段,是开发者编写代码的入口,也是最重要的一个阶段, 这个handle 方法会强制让开发者去实现
handle 阶段是需要开发者参与的阶段,是必须的阶段
生命周期之 — start
start 阶段,顾名思义,这个阶段会启动任务,由框架自动执行
生命周期之 — destroy
destroy 阶段,是程序运行完毕了,在jvm退出之前的最后一个阶段,一般用于收尾的工作
destroy 阶段是需要开发者参与的阶段,是可选的阶段
目录结构
推荐的项目目录结构如下,具体可以参考StreamPark Quickstart 里的目录结构和配置
.
|── assembly
│ ├── bin
│ │ ├── startup.sh //启动脚本
│ │ ├── setclasspath.sh //Java环境变量相关的脚本(框架内部使用,开发者无需关注)
│ │ ├── shutdown.sh //任务停止脚本(不建议使用)
│ │ └── flink.sh //启动时内部使用到的脚本(框架内部使用,开发者无需关注)
│ │── conf
│ │ ├── test
│ │ │ ├── application.yaml //测试(test)阶段的配置文件
│ │ │ └── sql.yaml //flink sql
│ │ │
│ │ ├── prod
│ │ │ ├── application.yaml //生产(prod)阶段的配置文件
│ │ │ └── sql.yaml //flink sql
│ │── logs //logs目录
│ └── temp
│
│── src
│ └── main
│ ├── Java
│ ├── resources
│ └── scala
│
│── assembly.xml
│
└── pom.xml
assembly.xml 是assembly打包插件需要用到的配置文件,定义如下:
<assembly>
<id>bin</id>
<formats>
<format>tar.gz</format>
</formats>
<fileSets>
<fileSet>
<directory>assembly/bin</directory>
<outputDirectory>bin</outputDirectory>
<fileMode>0755</fileMode>
</fileSet>
<fileSet>
<directory>${project.build.directory}</directory>
<outputDirectory>lib</outputDirectory>
<fileMode>0755</fileMode>
<includes>
<include>*.jar</include>
</includes>
<excludes>
<exclude>original-*.jar</exclude>
</excludes>
</fileSet>
<fileSet>
<directory>assembly/conf</directory>
<outputDirectory>conf</outputDirectory>
<fileMode>0755</fileMode>
</fileSet>
<fileSet>
<directory>assembly/logs</directory>
<outputDirectory>logs</outputDirectory>
<fileMode>0755</fileMode>
</fileSet>
<fileSet>
<directory>assembly/temp</directory>
<outputDirectory>temp</outputDirectory>
<fileMode>0755</fileMode>
</fileSet>
</fileSets>
</assembly>
打包部署
推荐 streampark-flink-quickstart 里的打包模式,直接运行maven package即可生成一个标准的StreamPark推荐的项目包,解包后目录结构如下
.
Streampark-flink-quickstart-1.0.0
├── bin
│ ├── startup.sh //启动脚本
│ ├── setclasspath.sh //Java环境变量相关的脚本(内部使用的,用户无需关注)
│ ├── shutdown.sh //任务停止脚本(不建议使用)
│ ├── flink.sh //启动时内部使用到的脚本(内部使用的,用户无需关注)
├── conf
│ ├── application.yaml //项目的配置文件
│ ├── sql.yaml // flink sql文件
├── lib
│ └── Streampark-flink-quickstart-1.0.0.jar //项目的jar包
└── temp
启动命令
启动之前确定application.yaml和 sql.yaml 配置文件,如果要启动的任务是DataStream任务,直接在startup.sh后跟上配置文件即可
bin/startup.sh --conf conf/application.yaml
如果要启动的任务是Flink Sql任务,则需要跟上配置文件和sql.yaml
bin/startup.sh --conf conf/application.yaml --sql conf/sql.yaml