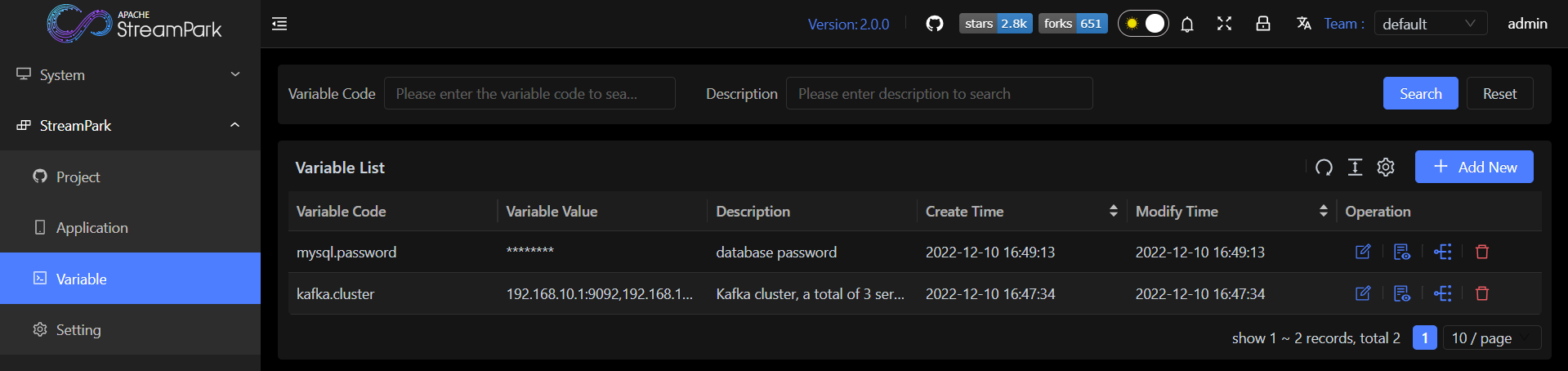
变量管理
背景介绍
在实际生产环境中,Flink作业一般很复杂,会依赖多个外部组件,例如,从Kafka中消费数据时要从HBase或Redis中去获取相关数据,然后将关联好的数据写入到外部组件,这样的情况下会导致如下问题:
- Flink作业想要关联这些组件,需要将外部组件的连接信息传递给Flink作业,这些连接信息是跟随StreamPark的Application一起配置的,一旦一些组件的连接信息有变化,依赖这些组件的Application都要修改,这会导致大量的操作且成本很高。
- 团队中一般有很多开发人员,如果对组件连接信息没有统一的传递规范,会导致相同的组件有不同的参数名,这样难以统计外部组件到底被哪些作业依赖。
- 在企业生产中,通常有多个环境,比如有测试环境、生产环境等,很多时候无法通过IP和端口来判断属于哪个环境,这样的话本来属于生产环境的IP和端口可能配置到了测试环境,导致生产故障。
创建变量
变量在Team之间是隔离的,不同的Team有独立的变量管理,所以在创建变量之前首先要切换到正确的Team,这里我们选择的是default team, 通过点击Add New按钮创建变量。
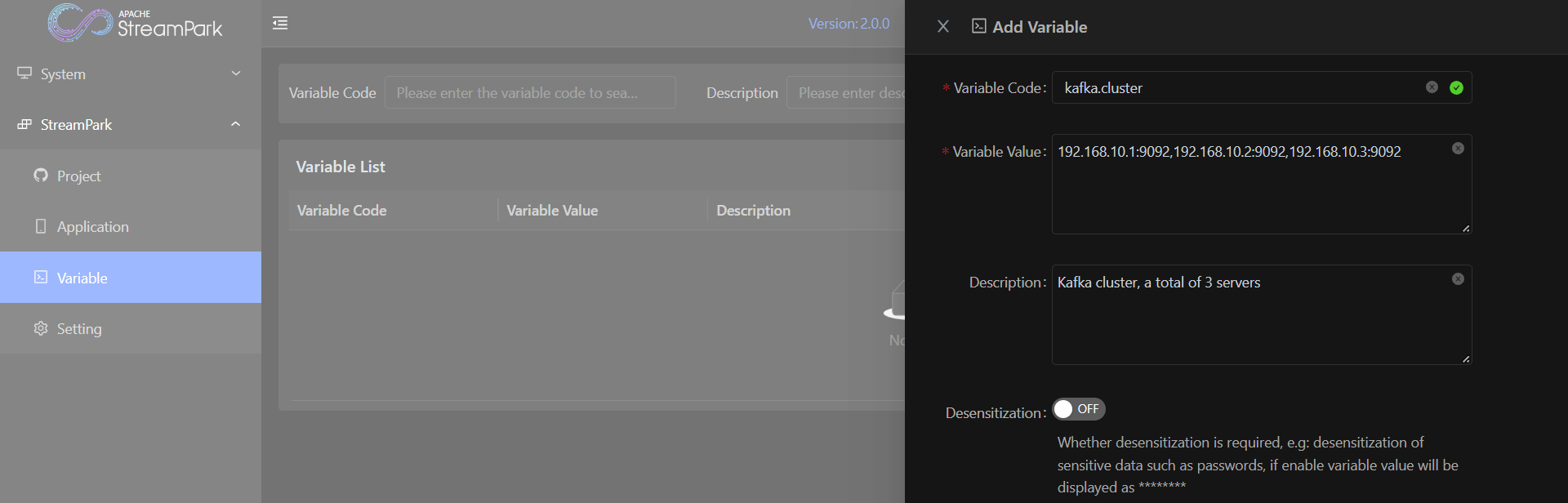
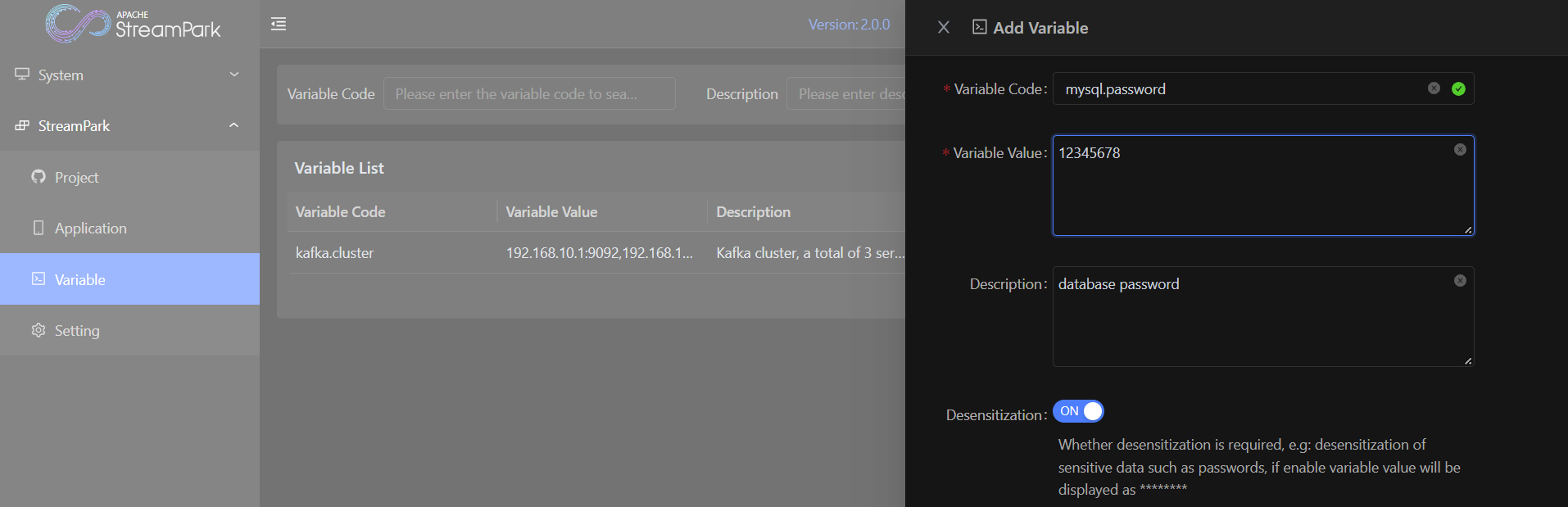
有些变量是敏感的,比如数据库的密码,在创建的时候可以打开Desensitization选项,这样变量的值将显示为********。
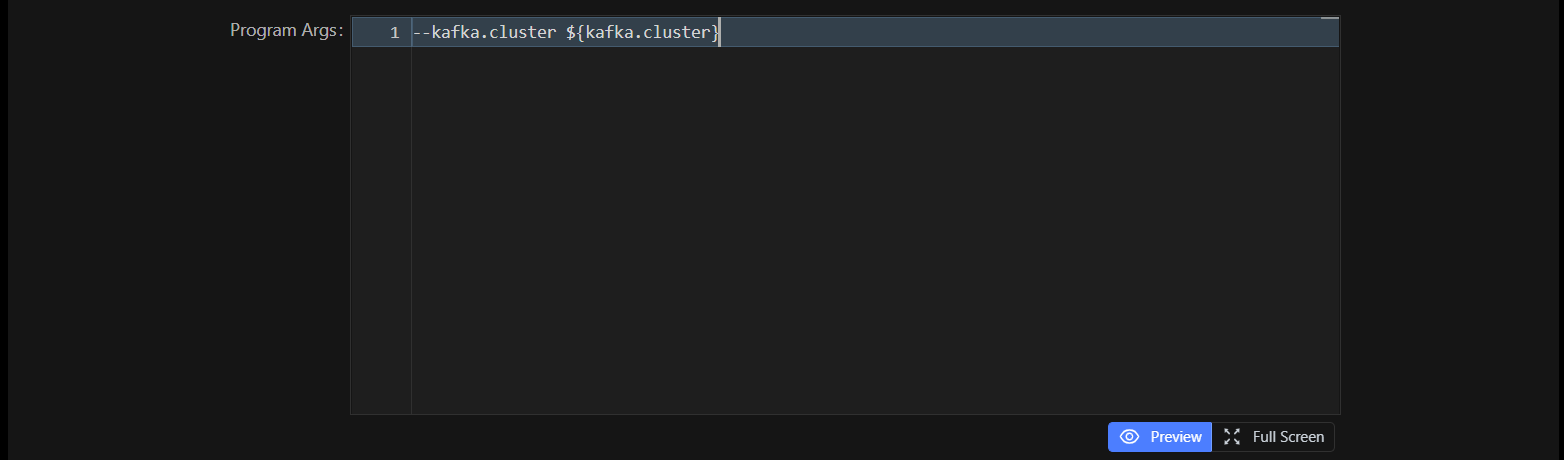
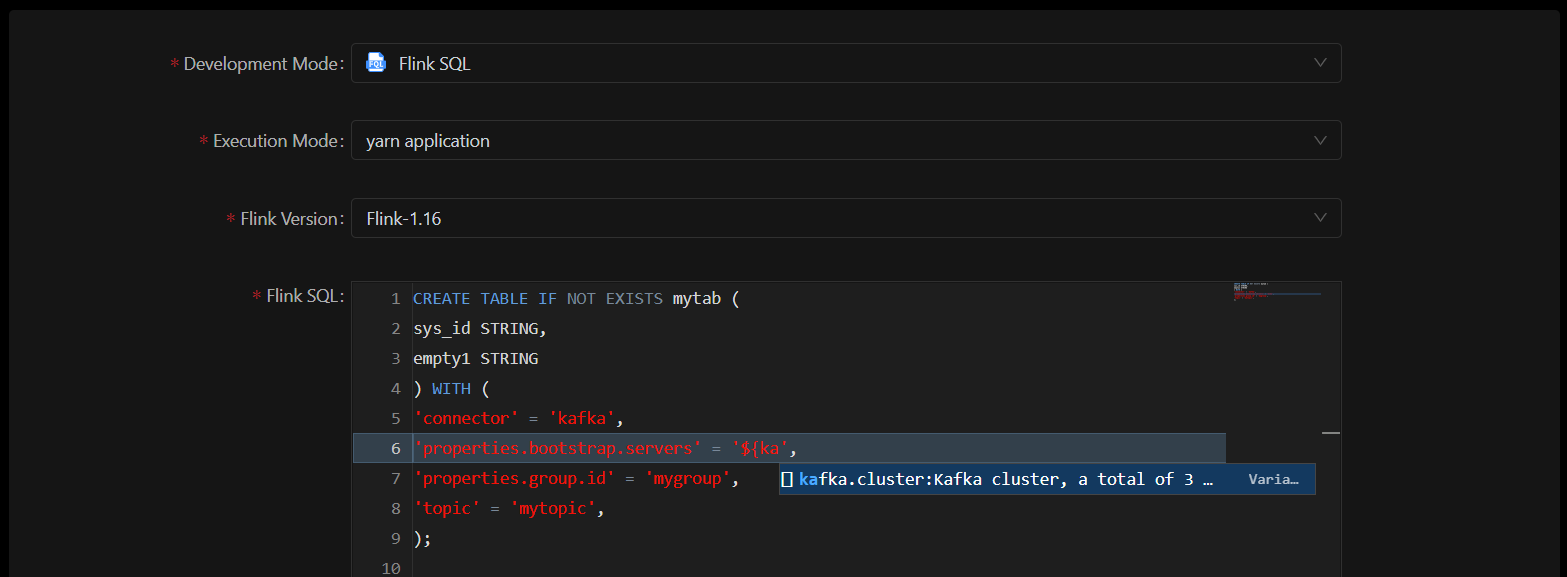
在Flink SQL中引用变量
在Flink SQL中以${kafka.cluster}的方式引用变量,当输入${时会提示跟随搜索。
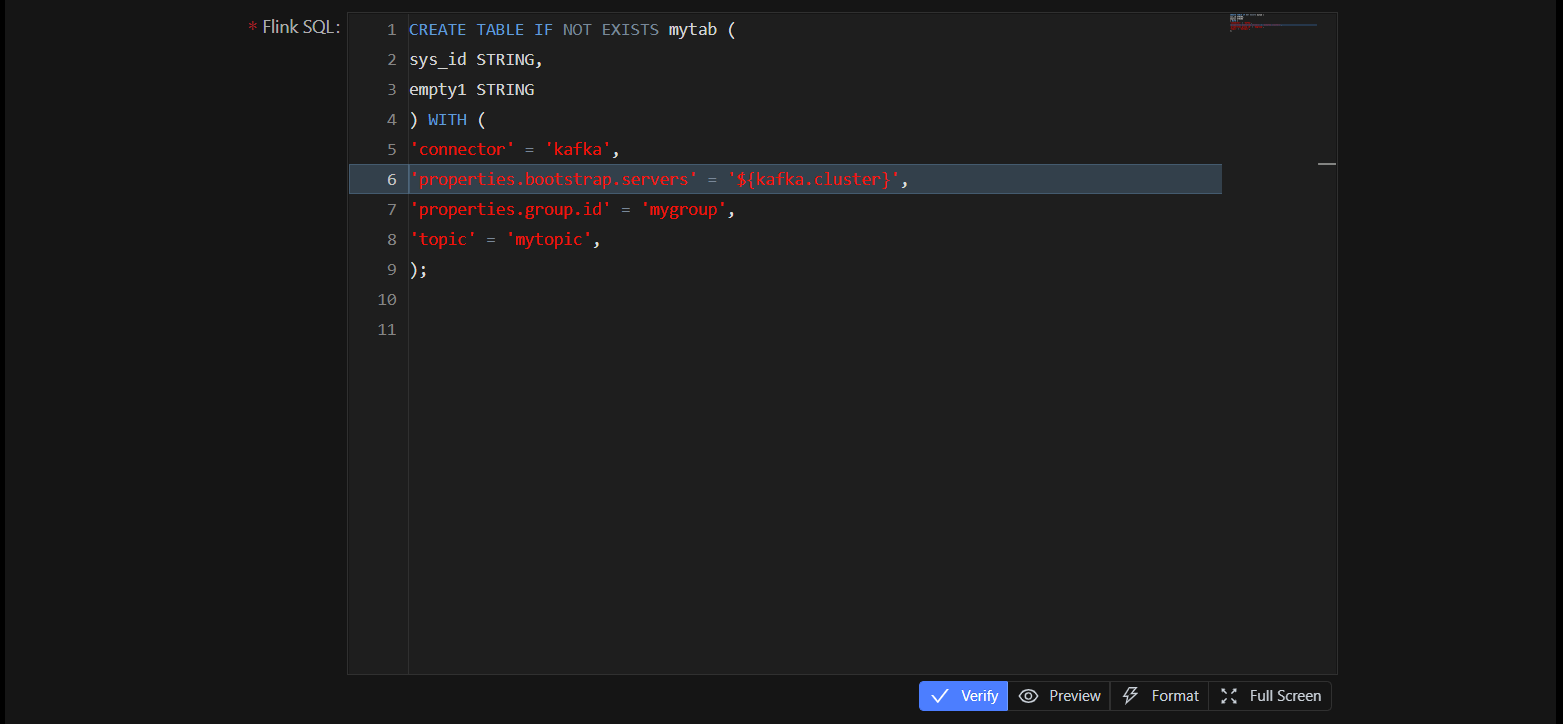
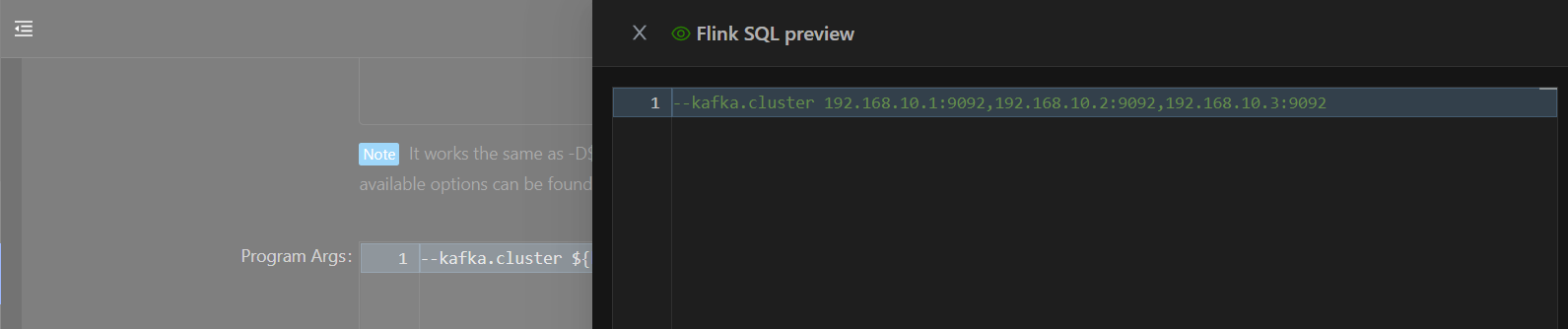
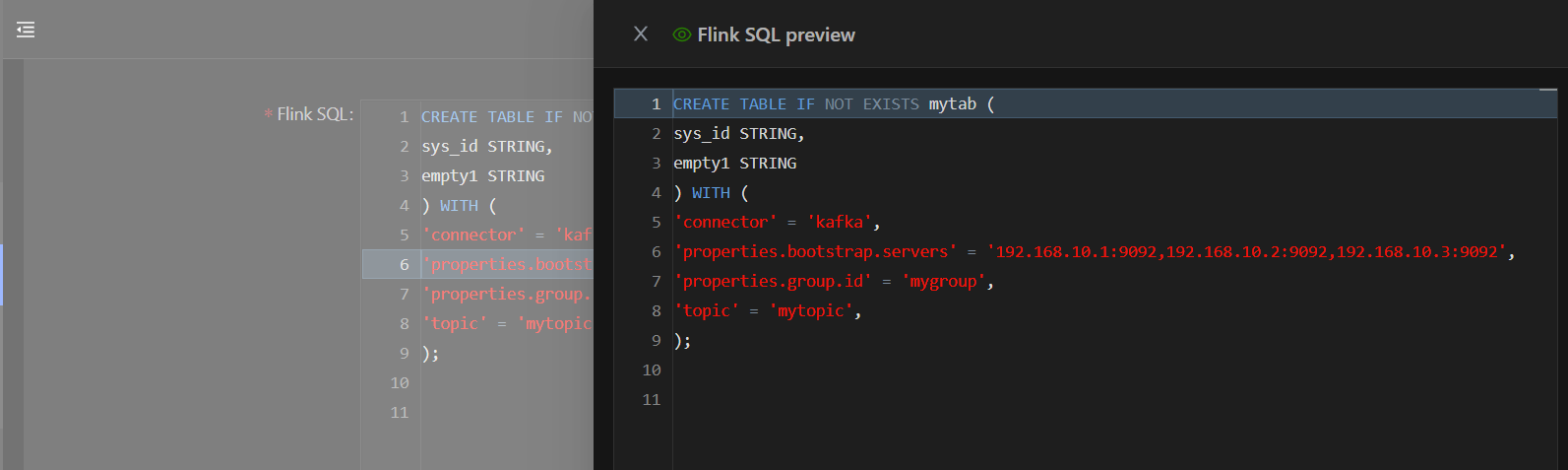
点击Preview按钮可以预览变量的值,如果变量被设置为敏感的,变量的值依然会显示为********。
在Flink JAR作业的args中引用变量
也可以在Flink JAR作业的args中引用变量,也支持输入${后跟随搜索。